应用场景
Download
聚焦模式
字号
腾讯云 EMR 支持开源组件丰富,应用场景广泛,本文为您介绍 EMR 的主要应用场景。
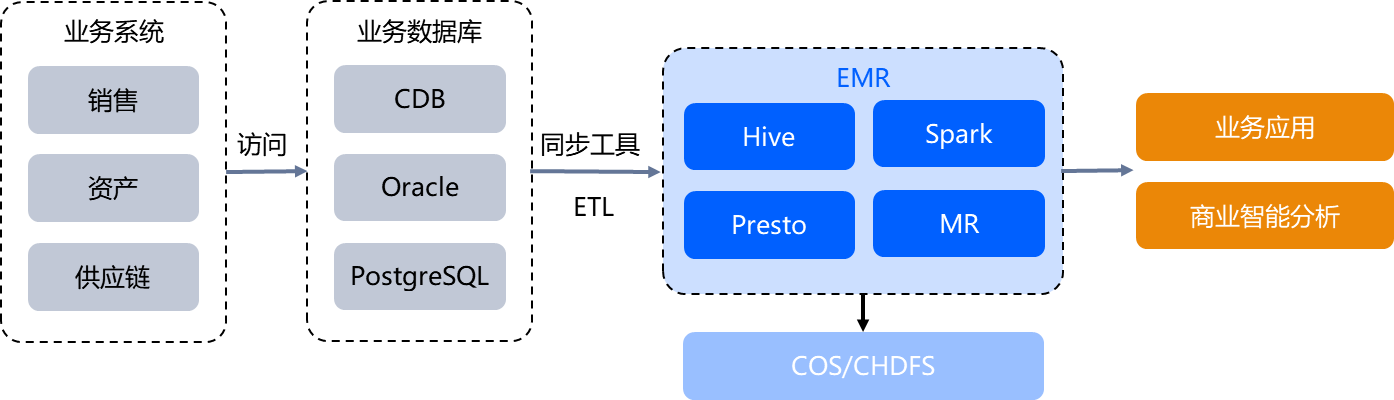
企业级数据仓库构建
对销售、资产、供应链等业务数据进行汇总分析,需要结合不同数据源,提取不同源的数据、然后借助 EMR 强大的 PB 级数据分析能力,以及原生支持腾讯云COS、CHDFS 存储,提供高性能存算分离数仓方案,对海量数据进行计算,发现数据中隐藏的商业价值,进行业务决策。
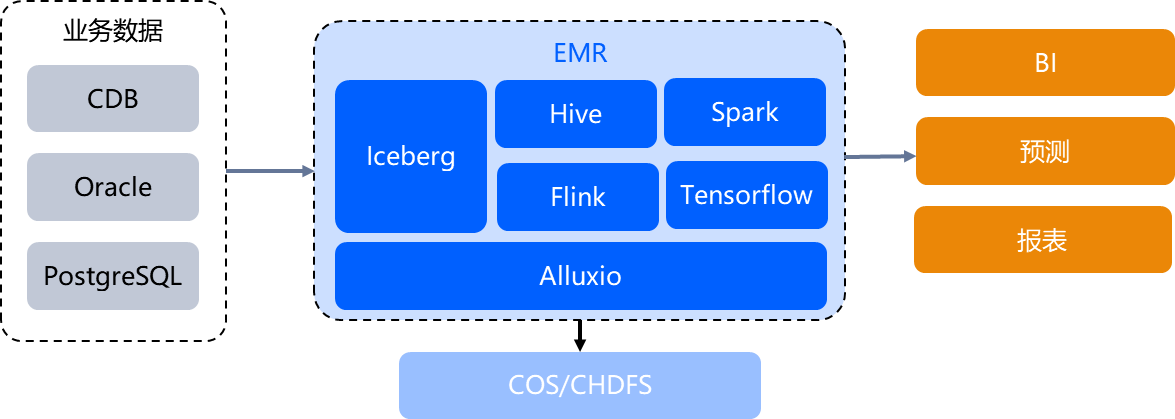
企业数据湖构建
在企业不断积累业务发展的全量数据领域,需要将各种类型的数据存储并适配多种场景的数据分析任务,借助 EMR 提供的数据湖格式及缓存加速能力构建数据湖,可以充分利用各种资源并适配如离线计算、流式计算、交互式分析、机器学习等场景,赋予客户更高的数据敏捷度、更低的数据分析成本。
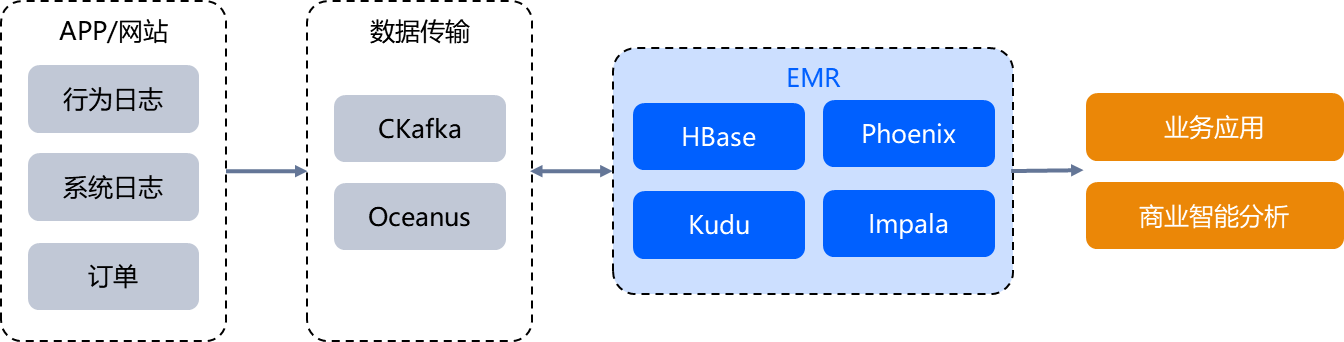
高并发在线数据查询
对用户行为、系统日志、订单等结构化或半结构化数据进行高效分析,需要收集在线网站、App、系统的用户行为及系统日志等各种业务数据,通过 EMR 丰富的计算组件及分钟级集群构建与平行扩展能力,支撑在线业务实时查询,提高业务响应效率。
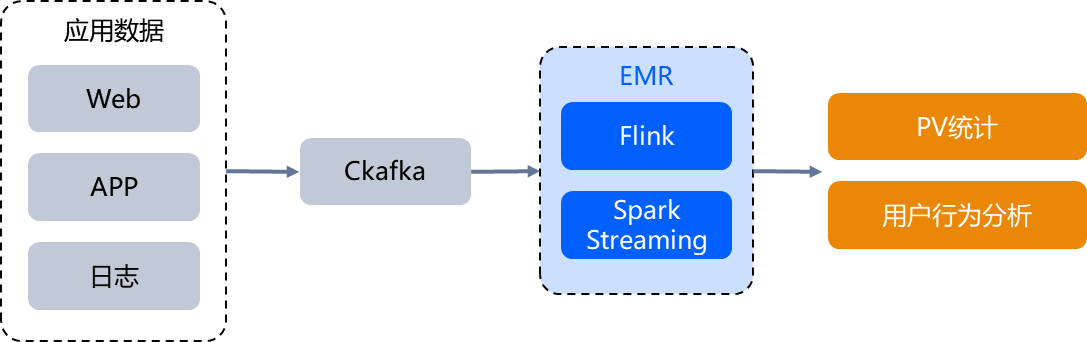
实时流式数据计算
在企业构建实时计算的业务领域,借助于 EMR 云端流计算服务,能够分钟级构建实时分析,对用户行为数据进行实时汇聚分析,帮助改进用户体验。通过同时搭建批、流处理系统,实现批流一体,降低资源投入,提升数据处理速度,及时分析业务运营效果,快速调整业务策略,支撑主流业务更好发展。
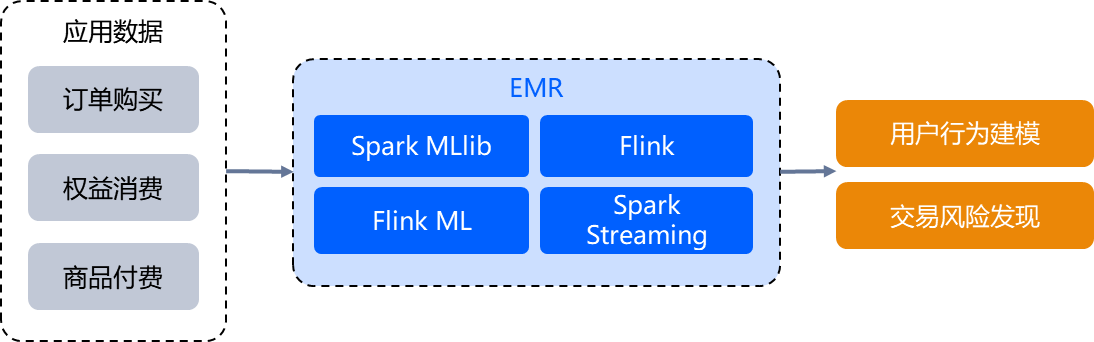
数据挖掘及分析
在实时风控、实时推荐等需要快速计算以及数据挖掘能力的业务场景,EMR 可以提供高效的云端流计算服务以及数据挖掘组件能力支撑,帮助业务监控储户异常交易,及时发现金融漏洞,确保资金安全,以及构建用户画像模型,帮助企业准确及时地了解用户群体。
文档反馈