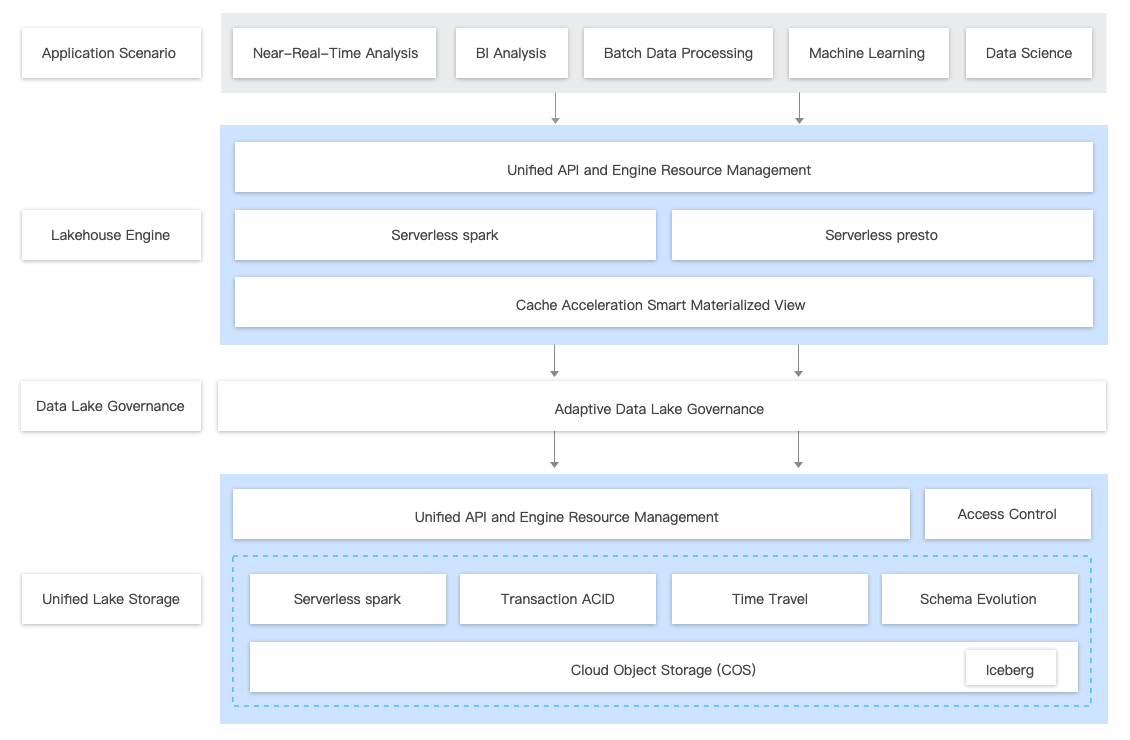
Data Lake Compute (DLC) offers agile and efficient data lake analytics and computation services. With its serverless architecture, it is ready to use out of the box. By utilizing standard SQL syntax, it can accomplish data processing and multi-source data joint computation, effectively reducing the cost of setting up and using data analysis services, and enhancing the agility of enterprise data.
Note:
The Presto engine has been deprecated and is only available for existing users.
Users are not required to perform traditional data layer modeling, significantly reducing the preparation time for massive data analysis. Furthermore, it can be combined with Tencent's big data ecosystem products such as WeData and DataInLong to swiftly construct an enterprise-level, cloud-native, real-time lake computation platform.
Unified Data Development: Integration with Tencent Cloud's WeData platform for unified integration, development, governance, and application of data lakes.
High-Performance Lakehouse Analysis Engine: Supports both Spark and Presto engines, unifies multi-engine SQL syntax, and accelerates query caching, thereby completing data query analysis more swiftly and efficiently.
Unified Metadata Service: Offers unified metadata management and a comprehensive permission system to meet multi-tenant usage scenarios.
Adaptive Data Governance: Equipped with intelligent lake format governance capabilities, efficiently handling small file merging under stream writing and deletion of expired snapshots from historical versions.
Unified Lake Storage: Data storage enhanced by COS and Iceberg, ensuring ACID transactionality of data and supporting a materialized view cache acceleration layer.
Main Features
Data Exploration: Ready-to-use SaaS-based data lake analysis.
Standard SQL can be used to easily query data lakes, compatible with SparkSQL, eliminating the need to understand the data structure of different data facilities, and assisting customers in seamlessly upgrading from database scenarios to big data scenarios. It also supports joint query analysis of heterogeneous data from multiple sources, including MySQL, EMR Hive(COS), EMR Hive(HDFS), and more.
Data Job: Ultimate elasticity and cost-effective Spark batch processing.
Aimed at big data + AI scenarios, it leverages the batch processing and stream computing capabilities of native Spark to support users in performing complex data processing and ETL operations through data tasks. It supports the management of commonly used dependency packages in machine learning and AI scenarios, swiftly constructing a big data foundation for AI scenarios. Additionally, it possesses a comprehensive data access policy management function, supporting the configuration of data access policies to ensure data security.
Data Management: User-friendly and comprehensive capabilities for holistic governance of data lakes.
Provides a unified metadata management view for data lakes, enabling the creation and editing of the overall data directory of the data lake, as well as the creation, querying, and deletion of database tables and data views, thereby eliminating data silos. It also supports intelligent data governance for backup lake formats. Users need not concern themselves with complex data lake format governance and optimization. DLC will intelligently handle a large number of small files and orphan snapshots generated by frequent fragmented writing, thereby comprehensively enhancing the performance of data lake queries.
Data Engine: Massive scale computation expansion, elastic cost reduction and efficiency enhancement.
Offers flexible and efficient elastic management of Spark and Presto cloud-native computing engines, supports various scaling rules configurations, significantly reduces the comprehensive cost of data lake query analysis, and closely aligns with the actual business usage curve. As a low-cost, highly elastic cloud-native data lake solution, Data Lake Compute empowers businesses to establish unified data assets, maximize performance advantages, and enable agile innovation in business applications.