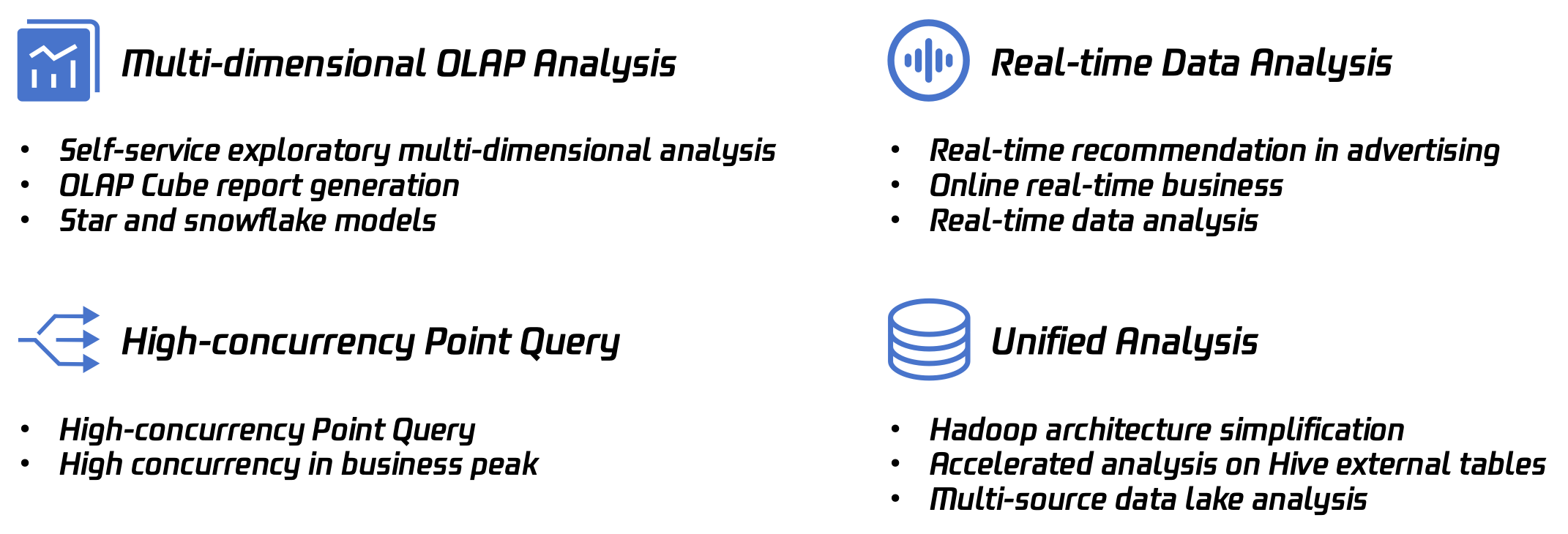
Tencent Cloud TCHouse-D, as an analytical database, is suitable for almost all analytical data scenarios, including the following four main scenarios:
These four scenarios are most anticipated by users in actual business when it comes to analytical databases. However, facing large data volumes, these scenarios demand a highly performant system. Tencent Cloud TCHouse-D meets these stringent requirements on system features and performance through the following technologies.
Multi-dimensional OLAP Analysis—High-speed and Flexible Probing on Multi-dimensional Tables
In relational databases, operations like drilling, rolling up, slicing, dicing, and pivoting on data cubes (CUBE) for multi-dimensional analysis definition are achieved through dimensional modeling.
The most common models in dimensional modeling are the star model and the snowflake model.
In dimensional modeling, columns in a table can be divided into dimension columns and metric columns. Tencent Cloud TCHouse-D supports defining dimension columns and metric columns during table creation, as shown in the figure below.
Functions can be defined on metric columns. During data import, data can be categorized according to dimension columns, and then aggregated according to the functions specified by the metric columns. This pre-aggregation capability greatly reduces the amount of data scanned by queries, thereby accelerating aggregate queries.
Also, Tencent Cloud TCHouse-D supports materialized views, rollup indexes, and CUBE syntax. The rollup corresponds to the operation of rolling up, and CUBE can be created through Grouping Set syntax.
Real-time Data Analysis—Real-time Addition, Deletion, Modification, and Query on PB-level Data
The following figure shows a table creation statement of Tencent Cloud TCHouse-D. From this statement, it can be seen that data can be partitioned (Partition) and can also be bucketed (DISTRIBUTED BY). Through partitioning and bucketing, data in a table (Table) can be split into multiple tablets.
In Tencent Cloud TCHouse-D, each tablet can be set with multiple replicas. These tablets and their replicas can be stored in different backends (BEs), ensuring high data availability and reliability.
Physically, each tablet is split into multiple segment files of a certain size (256 MB). Segment is a column-stored LSM-Tree, also known as Log Structured Merge Tree, which is a layered, orderly, disk-oriented data structure. The theoretical basis of this structure is that the performance of bulk sequential writing on disk is much higher than random writing.
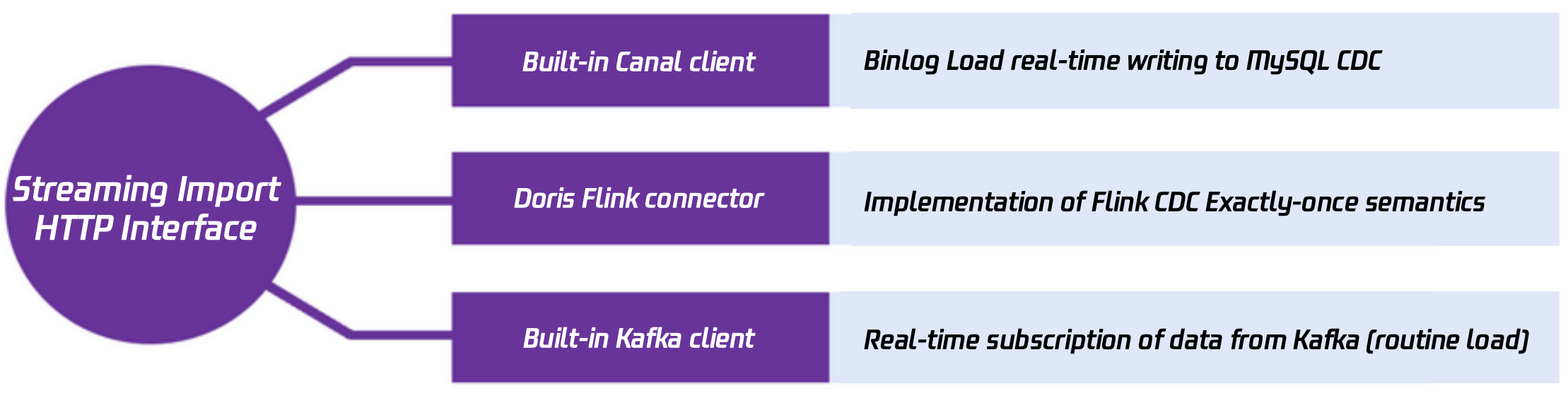
Also, real-time data input is a very crucial link. To achieve real-time data input, Tencent Cloud TCHouse-D supports multiple input methods:
Real-time data writing through Stream Load;
Real-time access to MySQL binlog through the built-in Canal client;
Precision data import through Doris Flink Connector's integration with Flink CDC;
Real-time data update through subscription to Kafka Topic using the built-in Kafka client.
High-concurrency Point Query—Low Latency for High-concurrency Queries
Tencent Cloud TCHouse-D is a modern Massively Parallel Processing (MPP) query engine, which completely implements the Exchange node. With the Exchange node, queries can be decomposed for parallel data processing on nodes.
At the same time, the easy horizontal scaling of frontends (FEs) and backends (BEs) theoretically enables Tencent Cloud TCHouse-D to handle the increase in concurrency, thereby meeting high concurrency requirements.
Additionally, Tencent Cloud TCHouse-D provides a wealth of index structures to help expedite data reading and filtering. Indexes can generally be divided into smart indexes and secondary indexes.
Smart indexes are automatically generated during data writing without user intervention, including prefix sparse indexes and MinMax indexes.
Secondary indexes are auxiliary indexes that users can selectively add to certain columns.
Tencent Cloud TCHouse-D also supports the dynamic partition trimming and predicate push technologies. These technologies can effectively reduce the data volume scanned from the disk, thereby accelerating query execution.
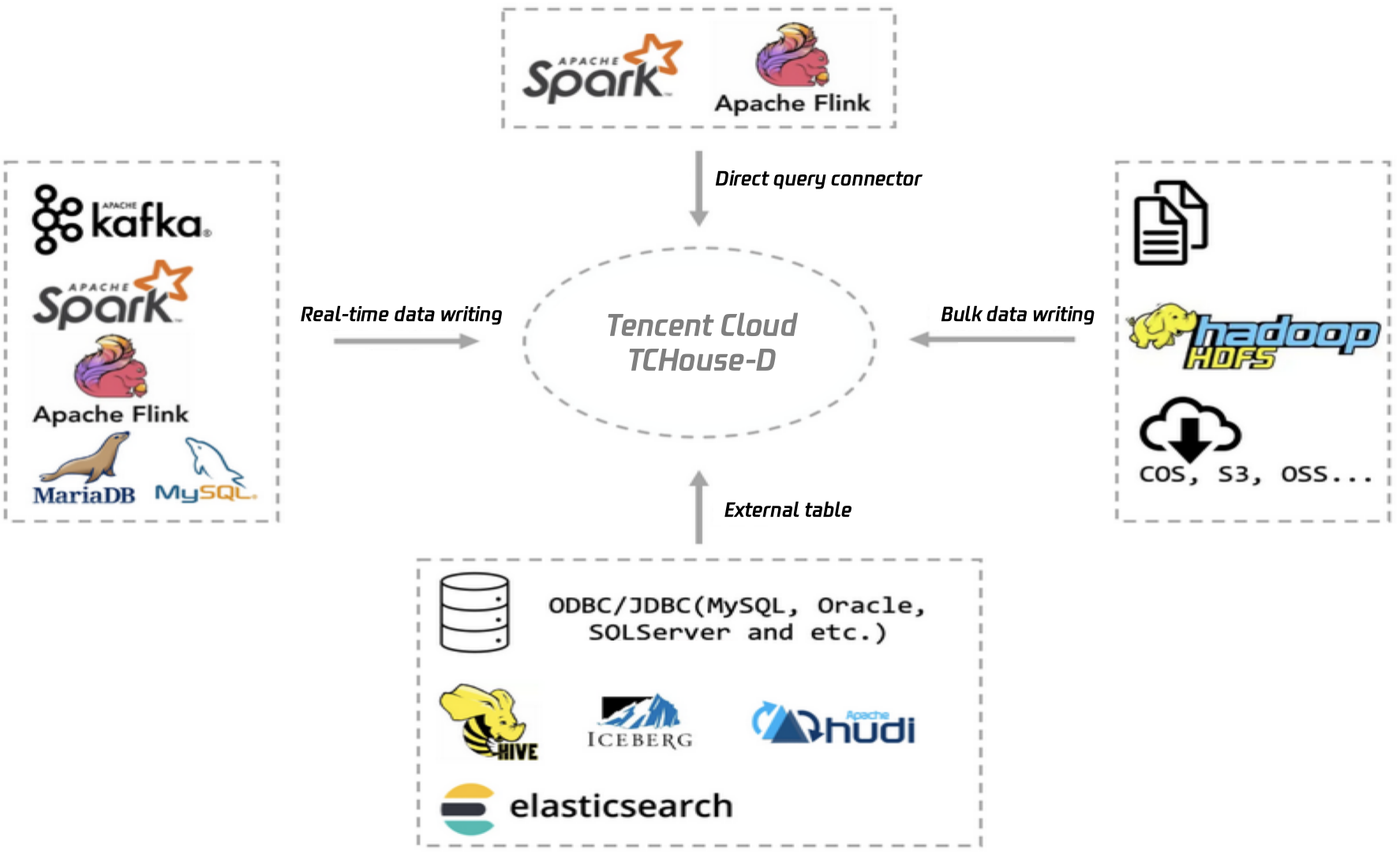
Unified Analysis—Hadoop Ecosystem Compatibility and High-performance External Table Querying
Tencent Cloud TCHouse-D is not dependent on Hadoop components, but it fully supports the Hadoop ecosystem. Apart from writing through Flink and Spark, it can import HDFS data or query Hive data directly by establishing a Hive external table.
The following figure is a panoramic view of Tencent Cloud TCHouse-D's support for the Hadoop ecosystem.