These sharded clusters distributively store data in multiple physical machines based on shardkey. Their great scalability, therefore, makes them very suitable for storing terabytes to petabytes of data.
Sharded clusters support instance-level backup and Rollback to ensure high data reliability. Multi-node automatic disaster recovery mechanism is used in each shard to ensure high service availability.
You can leverage the sharding feature of TencentDB for MongoDB to build a massive distributed storage system easily and efficiently.
How do I create a MongoDB sharded cluster?
Log in to the TencentDB for MongoDB purchase page, click Sharded Cluster in Instance Type, and select the number of shards, the number of nodes in each shard, and node specification, according to your needs.
Each shard is a replica set containing multiple nodes. Multi-node automatic disaster recovery mechanism is used in each shard to ensure high service availability.
How do I query the information of a MongoDB sharded cluster?
In the console, you can view detailed information of the sharded cluster instance, such as the shard composition, shard node specifications, and used capacity, as well as perform operations including instance capacity expansion.
How do I expand the capacity of a MongoDB sharded cluster?
You can expand the capacity only by expanding all nodes at the same time. Adding nodes is not supported.
In the console, click Adjust Configuration on the instance list page and select the desired capacity.
How do I monitor data in a MongoDB sharded cluster instance?
You can monitor the data of the TencentDB for MongoDB sharded cluster in three dimensions:
Instance
Shard
Node
You can view the monitoring report on the System Monitoring page of an instance, from which you will see various metrics, including operation requests, capacity usage, and load.
What is the MongoDB sharding policy?
Hash key sharding mechanism is supported.
The shardkey is indexed compound fields.
Sharding is required for all data sets in a shard instance. We recommend that you store non-sharded data in a separate replica set instance.
What is the authentication mechanism for MongoDB shards?
MongoDB is fully compatible with SCRAM-SHA-1 and MONGODB-CR.
What sharded cluster commands are supported by MongoDB?
How do I select the sharding method for a sharded cluster instance?
You need to enable sharding for data collections in advance in the sharded cluster instance. The shardkey plays a crucial role in the read/write performance of the cluster. On TencentDB for MongoDB earlier versions, the shardkey cannot be modified once set. Generally, you can select an optimal shardkey as follows:
Make sure that the written data can be evenly distributed across multiple shards.
Make sure that frequent queries can get data from the same shard as much as possible, so as to avoid aggregation in mongos after data is obtained from multiple shards.
For frequent range queries, we recommend that you use ranged sharding.
For frequent queries with specified fields, we recommend that you use hashed sharding.
How do I perform presharding in a sharded cluster instance?
For a sharded cluster instance, presharding can ensure that data will be written into multiple shards as evenly as possible while avoiding business jitters caused by the moveChunk operation due to the imbalance between different shard chunks during peak hours. TencentDB for MongoDB supports two sharding strategies for data presharding:
Hashed presharding
The hashed presharding feature is supported by default, and you can run the following command to implement it (here, n is the number of shards):
Ranged presharding
MongoDB natively does not support ranged presharding by default, because it cannot know your data distribution. You can use splitAt for presharding to split the data into two parts within the specified ranges. For more information, see Split Chunks in a Sharded Cluster.
Balance window settings
If chunks are unevenly distributed across shards, moveChunk will be triggered to balance data. This process involves data migration, which increases the system load and affects the business during peak hours. Therefore, we recommend that you perform data balancing during off-peak hours and set the balance window. Below are examples:
How do I solve the problem where the database performance is compromised when a query request without the shardkey is executed in a sharded cluster instance?
Issue
If a query request carries the shardkey, it can be ensured that the data in the corresponding shard will be read, which maximizes the read performance. However, in actual business scenarios, when a business accesses the same table, some query requests carry the shardkey field while others don't. Such other requests will be broadcast to multiple shards, and the queried data will be aggregated in mongos and then returned to the client, leading to a low query efficiency.
Solution
If the cluster has a high number of shards, and the frequency of query requests without the shardkey is also high, you can create a secondary index table to solve this problem.
For example, in a feed information flow business, each feed information entry corresponds to a detail data entry and is stored in the feed_info details collection as shown below:
{
"_id": ObjectId("614498889f97fd4692d22991")
"feedId":"223"
"userId":3445
"feedInfo":"xxxxxxx"
}
As the feed_info table frequently queries data by userId, userId is used as the shardkey. However, the business also uses feedId frequently for query besides userId. As queries by feedId don't carry the shardkey, they will be broadcast to all shards, and the performance will be low if there are many shards.
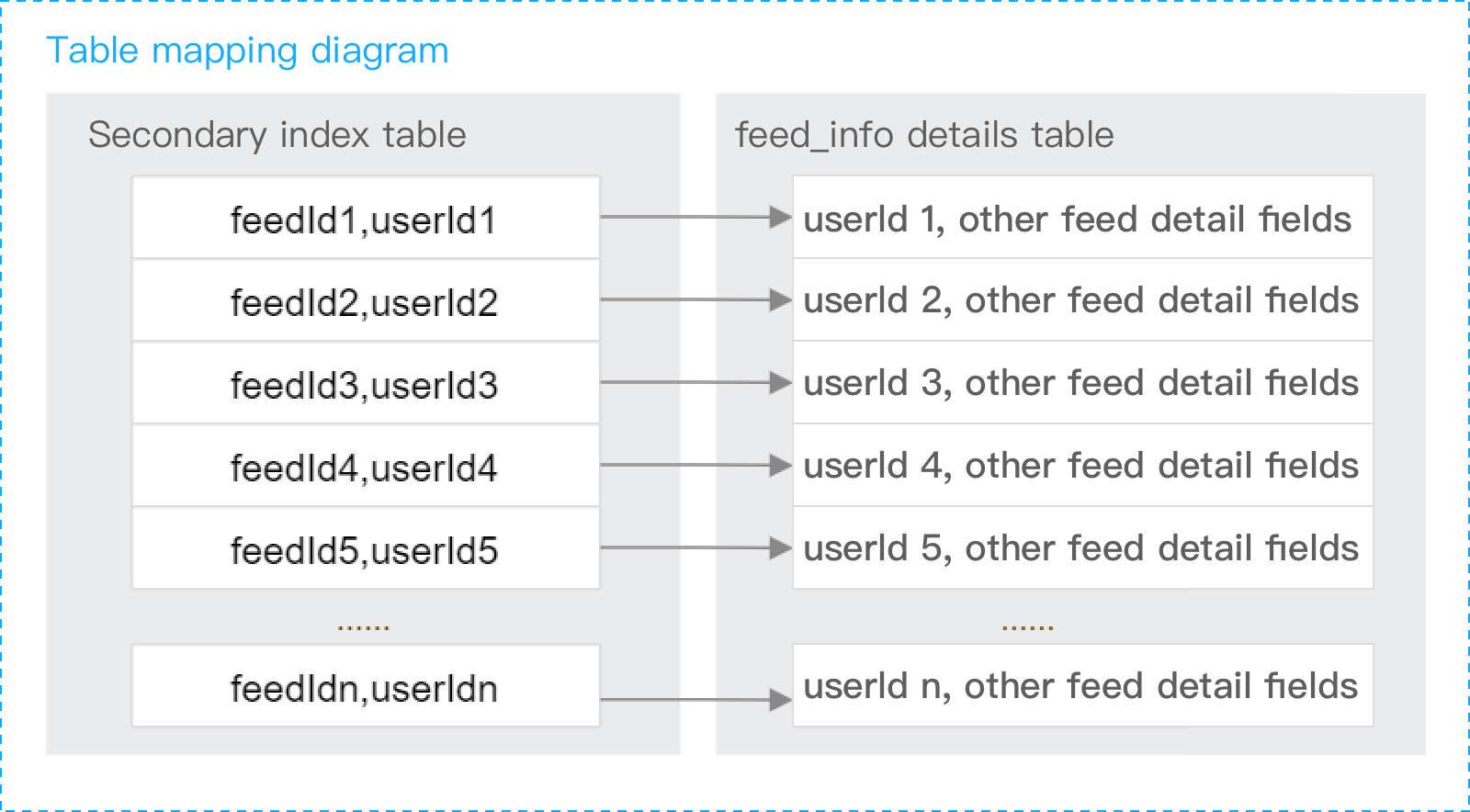
In this case, you can use the FeedId_userId_relationship secondary index collection with feedId being the shardkey. The mappings between this collection and the feed_info collection are as shown below:
As shown above, if you use a feedId to query the information of a specific feed, the corresponding userId of the feedId will be found from the secondary index collection, and the found userId and feedId will be used together to get the required details. The entire query process involves two collections, and the query statements are as follows:
1. // The shardkey of the `FeedId_userId_relationship` collection is `feedId`, and hashed presharding is performed
2. db.FeedId_userId_relationship.find({“FeedId”: “223”}, {userId: 1}) // Suppose the returned `userId` is `3445`
3. // The shardkey of the `feedInfo` collection is `userId`, and hashed presharding is performed
4. db.FeedInfo.find({"userId":"3445"})
In short, you can use a secondary index collection to ultimately solve the problem of cross-shard broadcasting. However, this approach increases the storage costs and adds a secondary index query. We recommend that you use it only in scenarios where the number of shards is high and queries without the shardkey are frequent.