Using Prometheus To Monitor Performance Testing Metrics
Download
Focus Mode
Font Size
Last updated: 2025-03-10 22:14:24
Performance testing is a challenging field, with performance assessment and optimization spanning all stages of development, testing, deployment, and launch. These processes directly impact system efficiency and user experience. This document introduces the storage metrics in Prometheus during performance testing and demonstrates how to visualize these metrics using Grafana. By observing the dynamic changes in metrics, you can identify system bottlenecks.
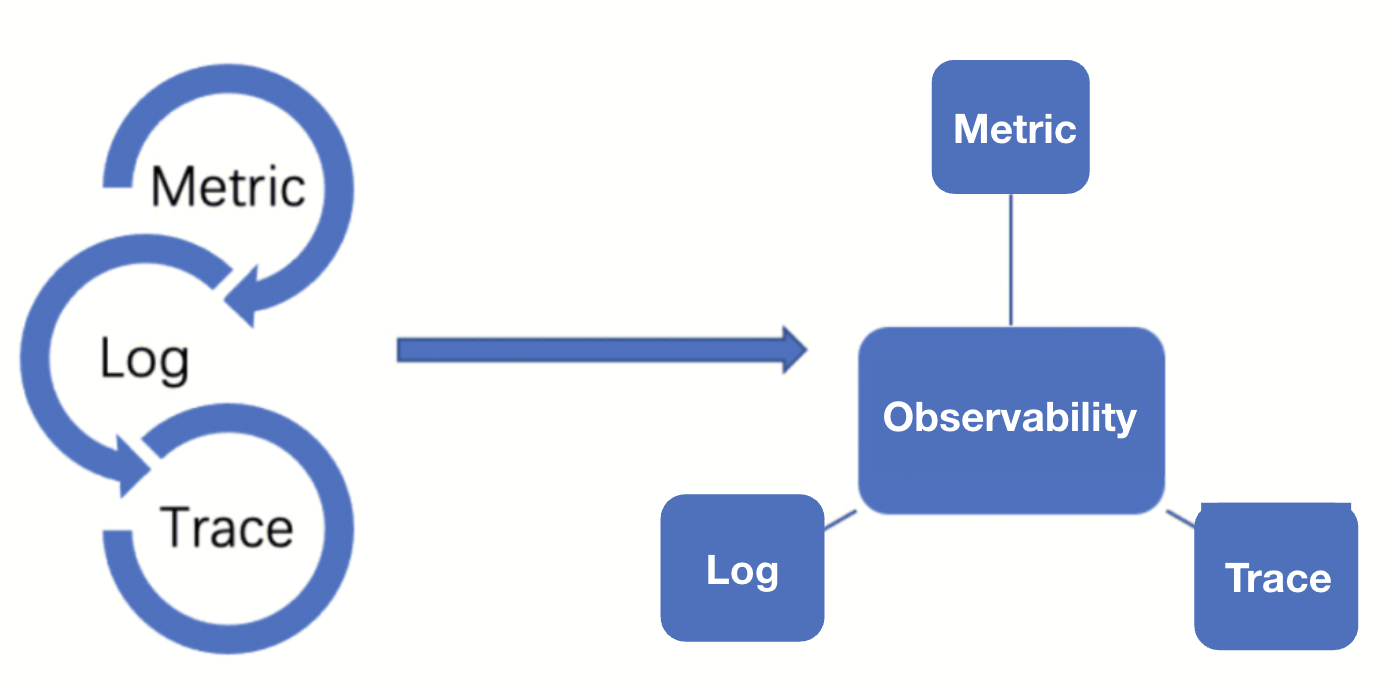
Performance Testing Observability
The observability system primarily consists of three types of metrics: Metrics, Logs, and Traces. These can operate independently or complement with each other to deduce the overall state of the system.
Metrics: Aggregated measurement values that quantify various system performance dimensions. Metrics are commonly used to provide a global view of the system and typically include types such as Counter, Gauge, and Histogram.
Logs: Logs or events generated during the operation of an application, provide contextual information about system operations, such as the value of a specific variable or details of an error that occurred.
Traces: Provide a complete view of a request from initiation to response across the entire linkage. In distributed systems, a request often passes through multiple services. Traces offer insights into each stage of the request chain, including response times, response content, and error occurrences. Traces make it easier to identify and analyze abnormal stages within a request.
Overview of Metrics
Counter: An Increment-Only Counter
Counter is a type of cumulative metric used to represent an increase-only value. If the system or service is reset, the Counter may start counting from zero again. The most common use of a Counter is to track the number of events, such as the number of requests, completed tasks, or errors. For example, a Counter metric like http_requests_total is used to record the total number of requests.
Obtain the request QPS by using the rate() function:
rate(http_requests_total[5m])
Query the top 10 HTTP requests by system access volume:
topk(10, http_requests_total)
Gauge: A Metric That Can Increase or Decrease
Gauge differs from Counter in that Counter reflects the number of occurrences of events, while Gauge reflects the current status of the system, such as the current temperature, server CPU/memory utilization, and the remaining available memory. For example, using a Gauge metric, you can monitor the available memory on a node:
# HELP node_memory_MemAvailable_bytes Memory information field MemAvailable_bytes.
# TYPE node_memory_MemAvailable_bytes gauge
node_memory_MemAvailable_bytes
Check the proportion of the remaining available memory (this statement is often used to set alarms, notifying you when the remaining available memory falls below a certain threshold so you can take action to avoid system memory shortages):
Histogram and Summary are primarily used to collect and analyze the distribution of samples.
Taking Histogram as an example, the histogram_quantile function is commonly used to calculate percentiles. For instance, to calculate the 90th percentile of request response times:
This query returns the 90th percentile of all recorded request durations over the past 5 minutes. In this way, Histogram provides you with a powerful tool to monitor and understand your system's performance.
Designing Observability Metrics
Performance stress testing can reveal system bottlenecks. By selecting appropriate observability tools and designing scientific metrics for monitoring, you can use metric variations to help identify system bottlenecks.
Core Metrics
During the performance testing, the following core metrics should be primarily monitored from the perspective of the load generating party:
Request response time: Includes average response time and response time percentiles.
Request RPS.
Request success rate and failure rate.
Request error reasons.
Performance test concurrency.
Checkpoint success and failure counts.
Request sent and received bytes.
Pressure machine memory/CPU utilization.
Metric Dimensions
Each metric should ideally be distinguished by different dimensions, such as:
1. Calculate the QPS for different requests based on response codes, such as the QPS for requests with response code 200 and response code 500.
2. Calculate the QPS for requests sent to different services, such as the QPS for performance testing targeting www.test1.com and www.ok1.com, respectively.
Taking HTTP requests as an example, the common dimensions are as follows:
job: Identifier for the performance testing task; each test is a different job.
method: Request method, such as GET, POST, and HEAD.
proto: Request protocol, such as HTTP, HTTPS, and HTTP2.
service: Request address, for example, https://www.test1.com.
status: Request response code, such as 200, 404, or 500.
result: Identifies the request response code, for example, 200 or any other code less than 400 corresponds to OK, 404 corresponds to Not Found, and 500 corresponds to Internal Error.
check: Name of the checkpoint/assertion, typically used to briefly describe the purpose of the assertion.
Metric Design
Based on this, we have designed a basic and commonly used metric system that can cover the majority of users' needs. For details, see the table below. You can also extend this metric system to meet specific requirements.
Metric
Type
Labels
Description
req_total
Counter
job,method, proto,service, status, result
Requests
req_duration_seconds
Histogram
job,method, proto,service, status, result
Request Duration
checks_total
Counter
job, check, result
Checkpoint
send_bytes_total
Counter
job,method, proto,service, status, result
Sent Bytes
receive_bytes_total
Counter
job,method, proto,service, status, result
Received Bytes
num_vus
Gauge
job
Concurrency, which can be used to indicate the number of virtual users. If JMeter is used for performance testing, it can also refer to the number of threads.
Example
To view the real-time number of concurrent users:
sum(num_vus{job=~"$job"})
To view the QPS of requests:
# View the QPS of different requests
sum(rate(req_total{job=~"$job"}[1m])) by (service)
# View the QPS of successful requests
sum(rate(req_total{job=~"$job",result="ok"}[1m]))
# View the QPS of a specific http://www.test1.com service
Users can flexibly extend the above demos to monitor the services under performance testing in a similar way. During the performance testing process, users can compare the metrics reports generated by the performance testing platform with the metrics reports of user services to comprehensively analyze and troubleshoot issues.
Use Prometheus to store the above metrics, query the data in Prometheus using query statements, and finally visualize the data through Grafana. This allows you to perform performance testing while monitoring the real-time changes in service performance metrics.
2. In the left sidebar, choose PTS > Test Scenarios.
3. On the testing scenario page, click Create Scenario.
4. On the page for creating a test scenario, select JMeter as the performance testing type and click Start to create a performance testing scenario.
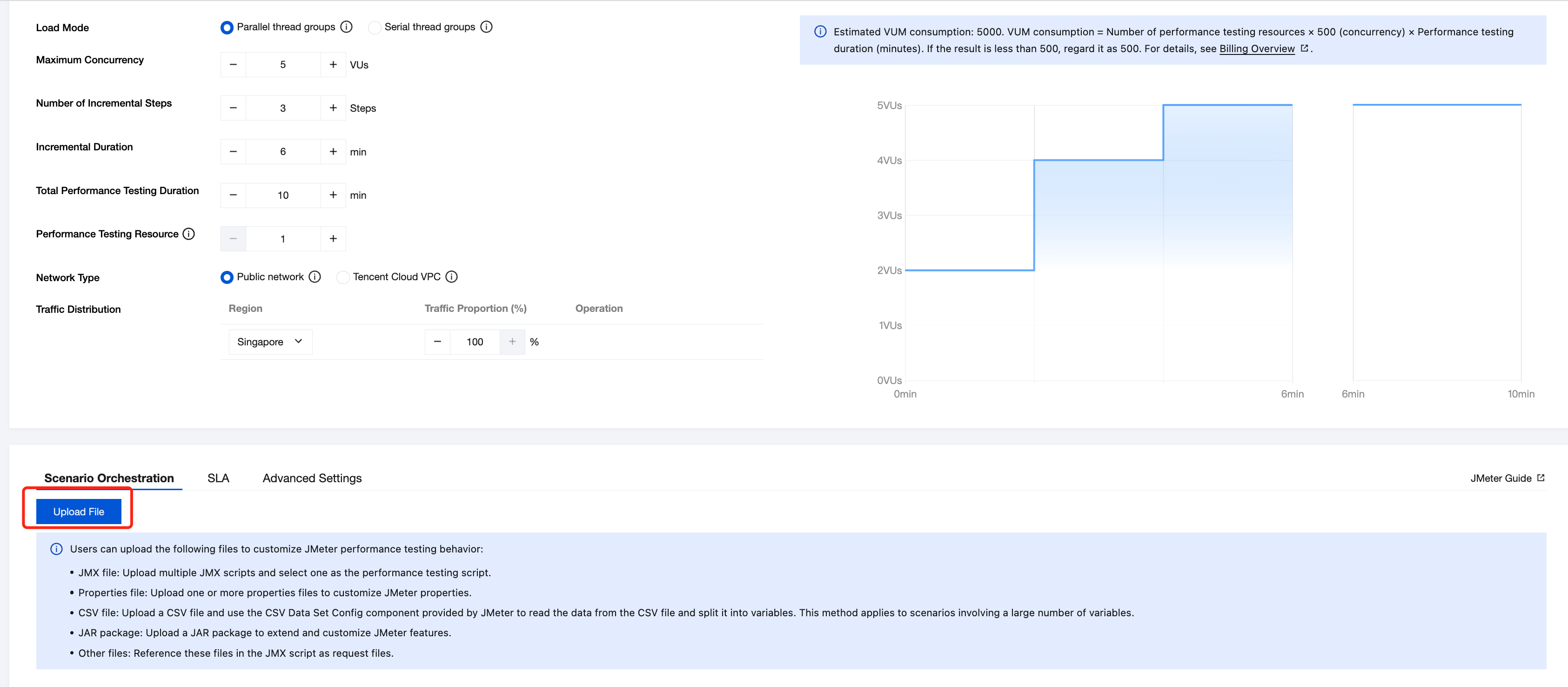
Uploading JMX Script
Required: Upload the JMX script.
Optional:
Upload Jar package: If your script uses JMeter third-party plugins, you can upload the corresponding jar package to extend JMeter features.
Upload properties file: Customize JMeter attributes based on the native jmeter.properties file.
CSV file: Use data from a CSV file in JMeter as variables referenced in the script.
Other files: Any additional files referenced in the JMX script.
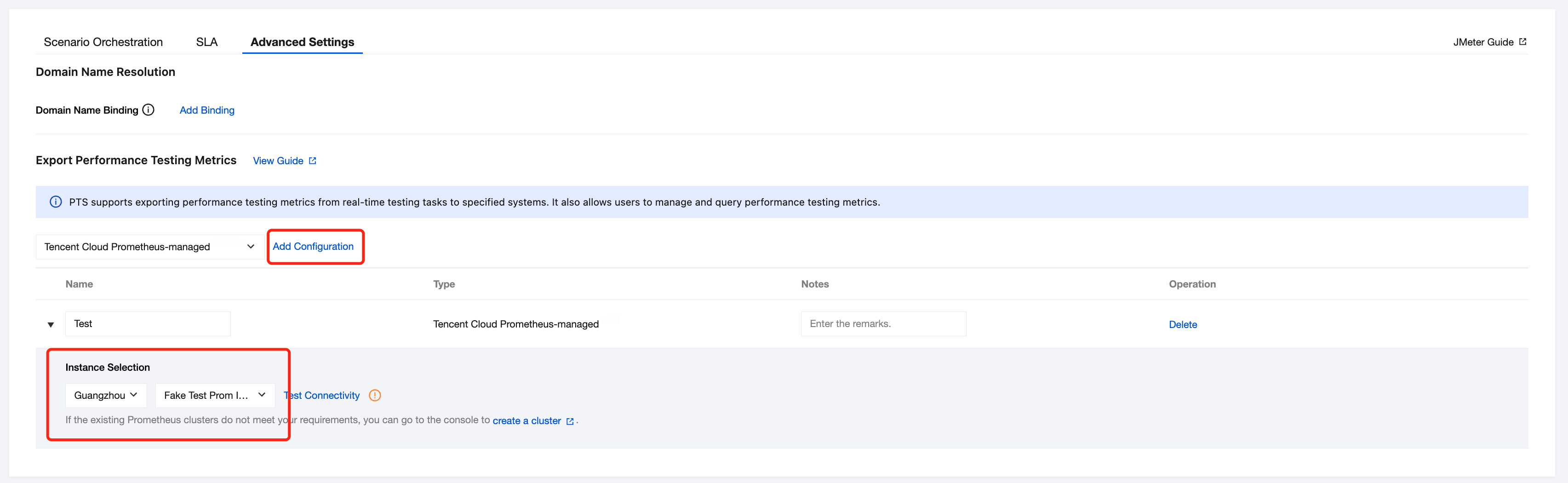
Exporting the Report to Tencent Cloud Prometheus
In Advanced Configuration > Export Performance Testing Metrics > TencentCloud Managed Service for Prometheus, click Add Configuration and select your instance:
If you do not have an instance in the region, you can also click Create New.
Running the Performance Testing Script
Click Save and Run to start the performance testing.
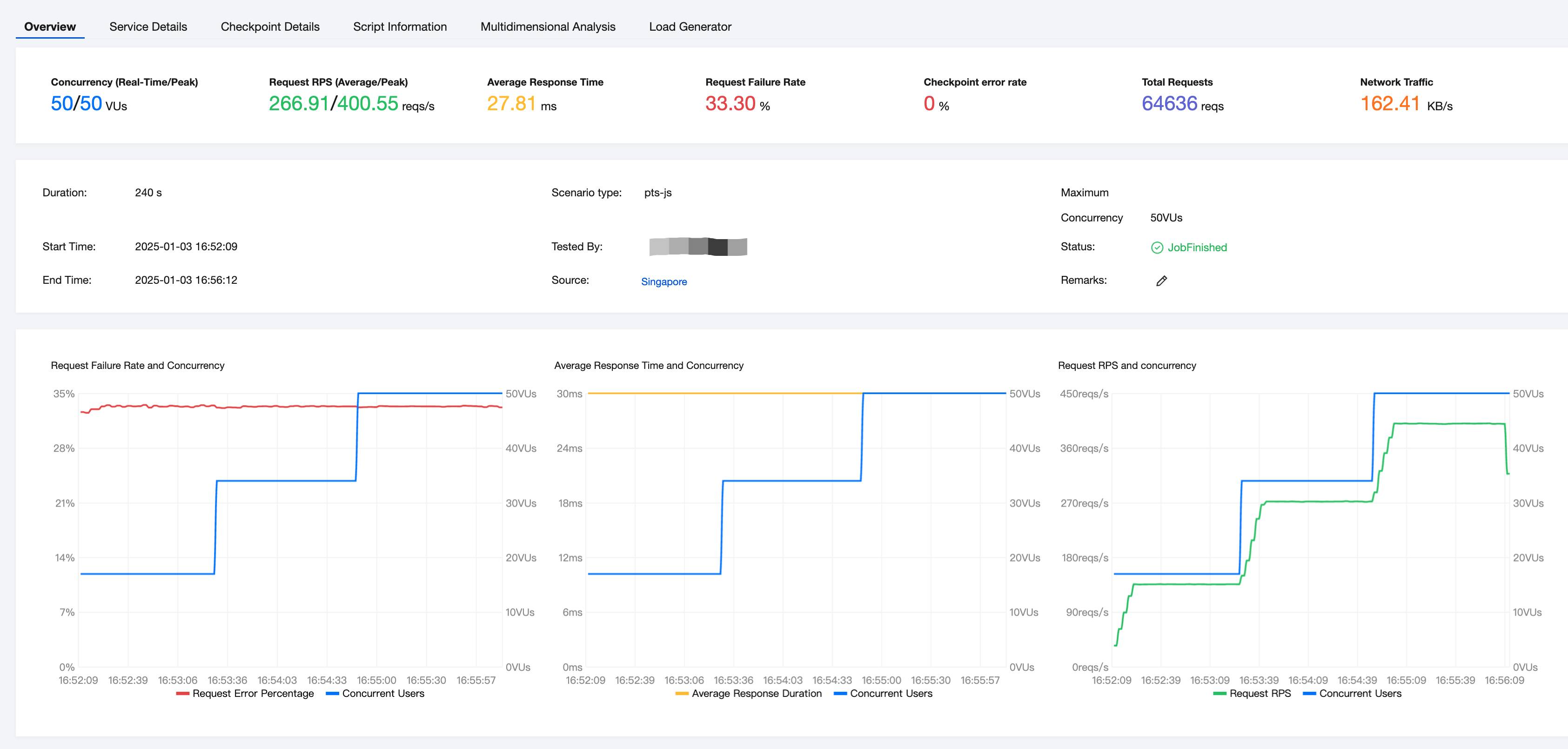
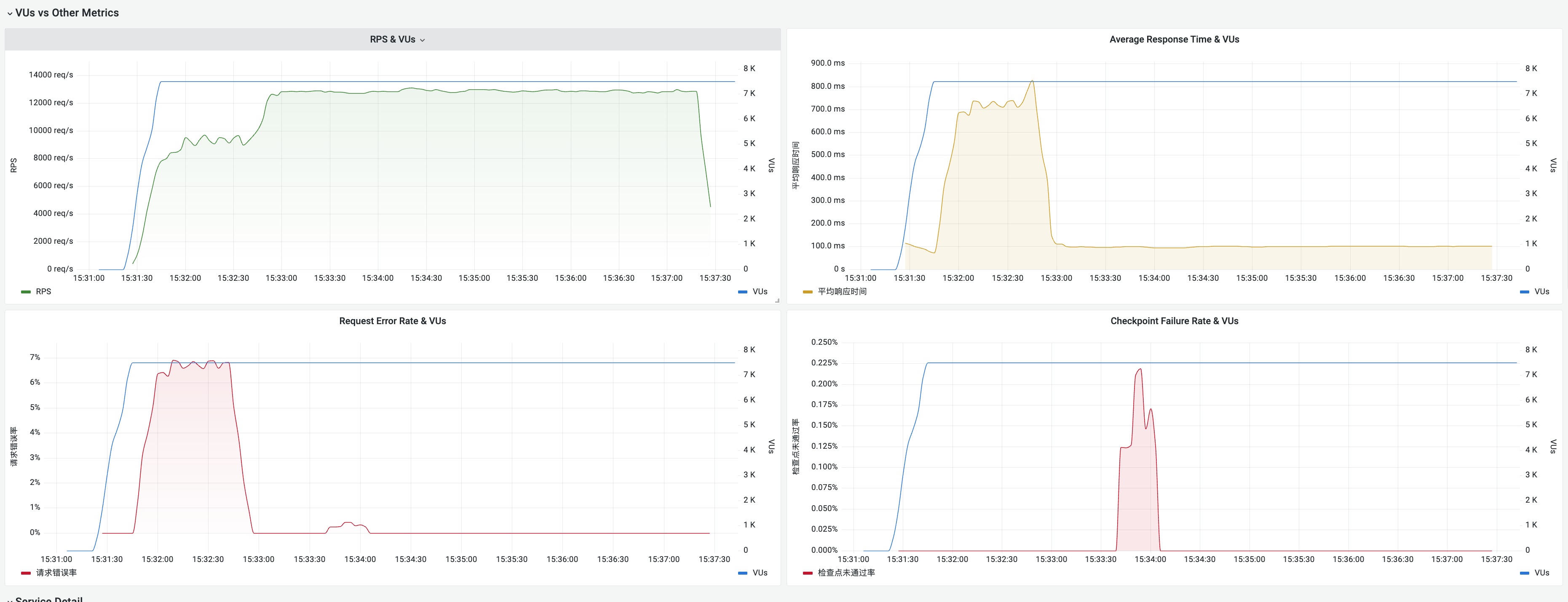
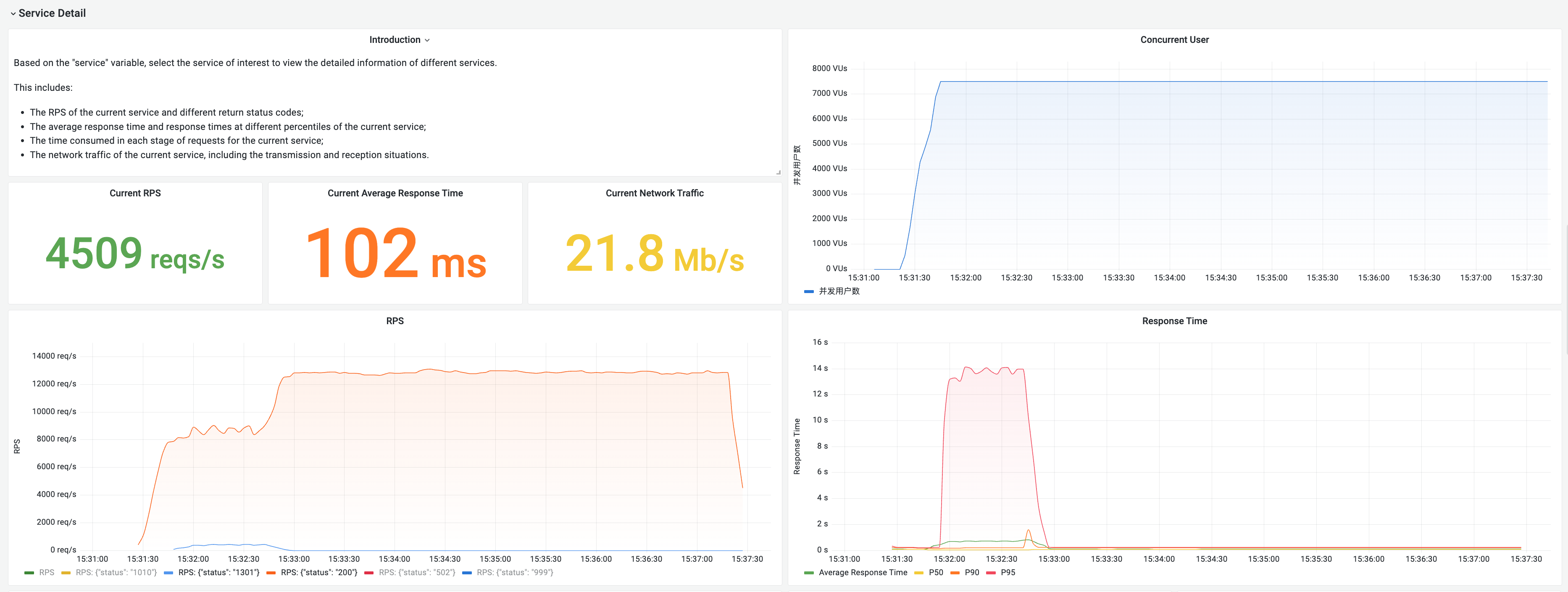
Viewing the Real-Time Reports
You can select different tabs to view the detailed reports from various dimensions.
Viewing Performance Testing Reports in Prometheus
During the performance testing process, metrics are synchronized to Tencent Cloud Prometheus (TMP). You can also query metric information in Prometheus and customize query statements.
1. Log in to the Prometheus Console and use the search bar to find your Prometheus instance by its name.
2. Click the instance ID to enter the instance details.
3. If your Prometheus instance is not associated with a Grafana, you can click Bind Grafana to display Prometheus metrics using Grafana.
4. Select Data Collection > Integration Center, search for the PTS application, and click it. A window will pop up; click Dashboard>Install/Upgrade to install the PTS monitoring dashboard to the Grafana bound to Prometheus.
5. To view the performance testing report in Grafana, log in to the Grafana page bound to Prometheus.
6. Search for PTS to view the PTS performance testing report.
7. Click PTS Task Details to view the detailed report.
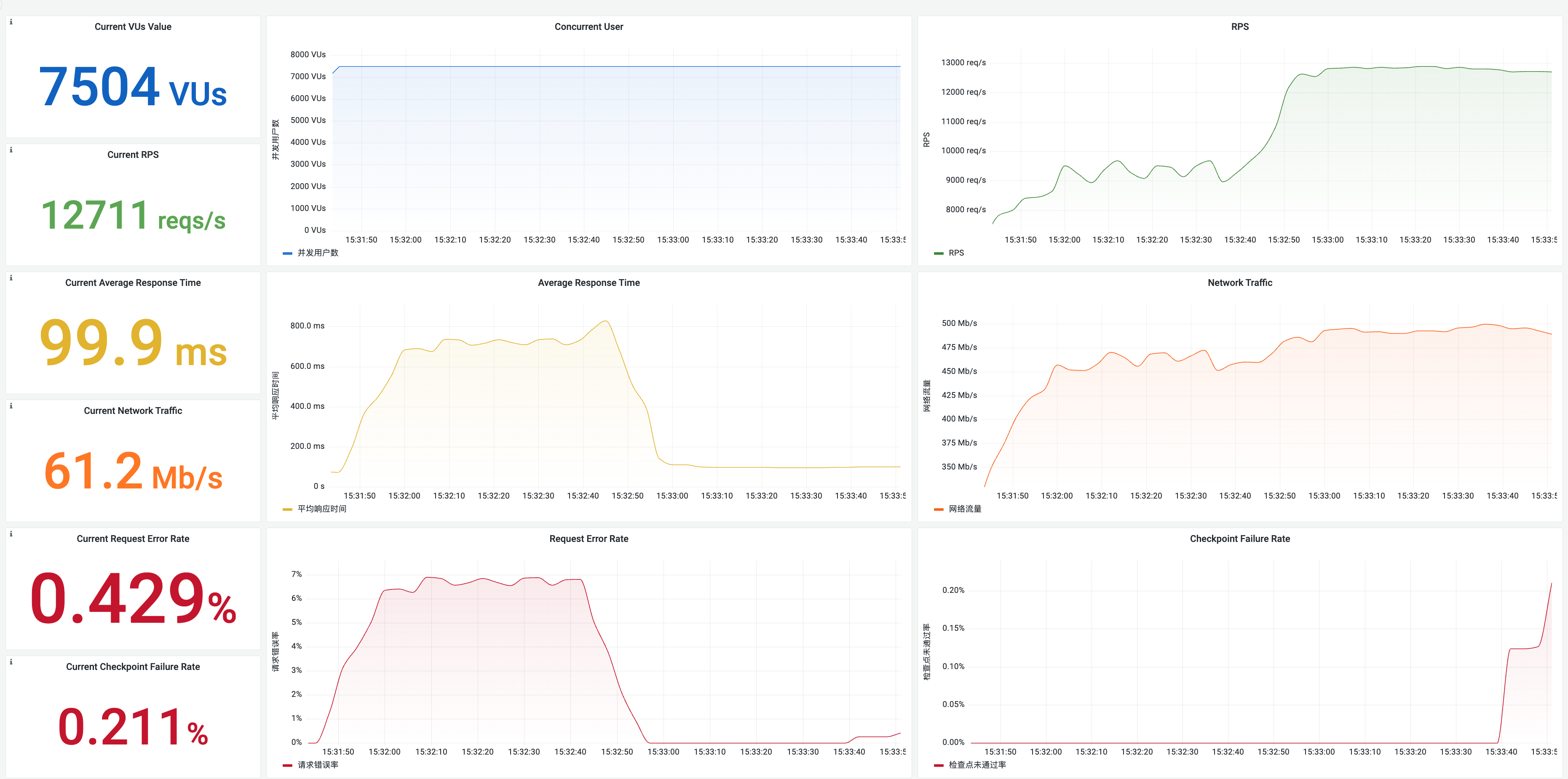
Assessing System Bottlenecks During Performance Testing
During the performance testing, the key focus should be on system throughput (RPS and network bandwidth), response time, and the number of concurrent users. The formula is as follows:
RPS = VU (concurrency) / Average response time
Understanding the Performance Testing Formula
Taking a single thread that loops to execute a request as an example: If the average response time for a request is 10 ms, then one concurrent thread can execute 100 requests per second. This corresponds to an RPS of 100 req/s.
From this formula, it can be deduced that there are several ways to improve the overall RPS during the performance testing:
Increase concurrency while maintaining the same average response time.
In this scenario, the service under test has not yet reached saturation. The RPS increases as the concurrency increases.
Reduce the average response time while keeping the VU constant.
This is an ideal scenario where the average response time decreases, indicating that the service under testing has been optimized. As a result, a single VU can send more requests in a given time.
In real-world performance testing, it is highly likely that as the number of VUs increases, the load on the system under test also increases, causing the response time to rise accordingly.
If the increase in response time is proportionally smaller than the increase in VU, the overall RPS will continue to grow. This indicates that the system has not yet reached its bottleneck.
If the increase in response time is proportionally greater than the increase in VU, the performance testing will show that as the VU increases, the overall RPS decreases instead. This indicates that the system has already reached its bottleneck.
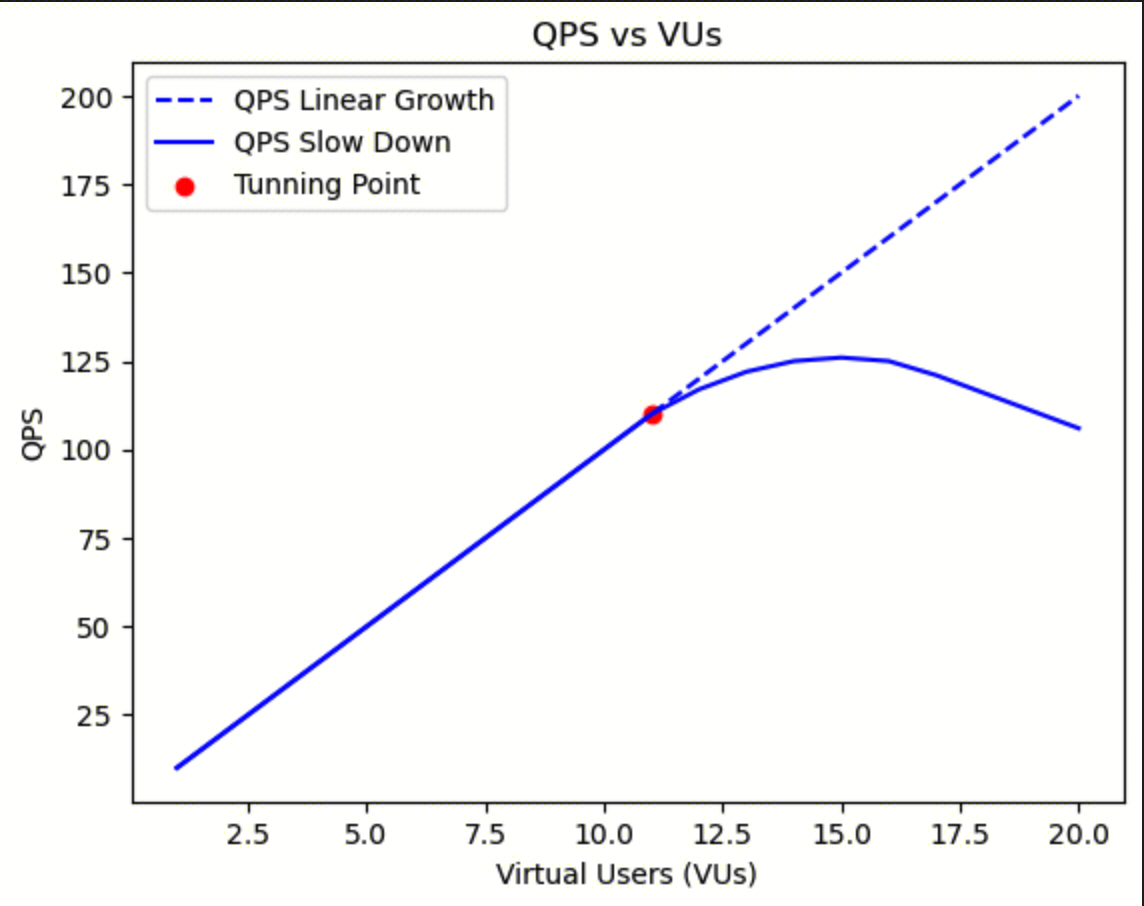
Assessing System Performance Turning Points
Performance testing aims to identify the scalability turning point of a business system under increasing load, which is the system's bottleneck or maximum capacity.
At a certain stage, we observe that scalability exhibits linear behavior. However, upon reaching a specific point, resource contention starts to affect performance. This point can be considered the system's turning point. As the dividing line of the curve, beyond this turning point, the overall throughput deviates from linear scalability due to intensified resource contention. Eventually, the overhead of resource contention leads to fewer completed requests and a decline in throughput.
This situation may occur after the system load reaches 100% utilization (saturation point) or when it is approaching 100% utilization, at which point queuing becomes more apparent.
For example, in a compute-optimized system, when more requests arrive, more threads are required to execute those requests. As CPU utilization approaches 100%, performance starts to degrade due to increased CPU scheduling delays. After the performance peak is reached, the overall throughput decreases as more threads are added. The additional threads lead to more context switching, consuming CPU resources, and resulting in fewer tasks being completed.
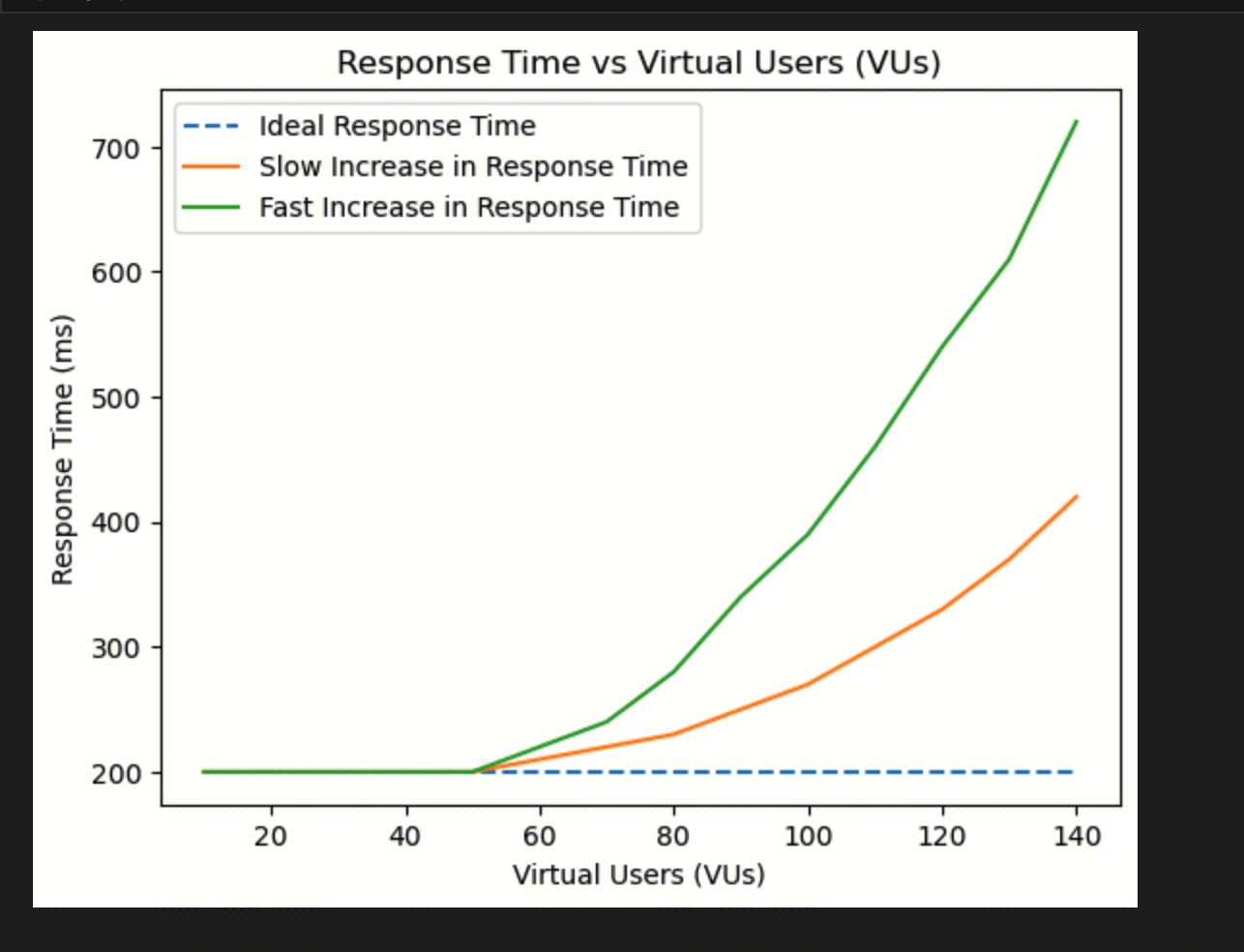
The non-linear change in performance can also be observed through changes in response time:
There are many reasons for performance degradation. In addition to the frequent context switching mentioned above, the following are also common causes:
The system memory is insufficient, leading to frequent swapping to compensate for memory shortages.
The system I/O increases, and the disk I/O operations may enter buffer queues.
The system implements internal queueing algorithms to perform peak shaving, resulting in longer request processing wait times.