This document introduces the use cases, working principles, and usage modes of the in-place Pod resource update feature. According to the Kubernetes specifications, to modify container parameters when the Pod is running, you need to update the PodSpec and submit it again. This will delete and rebuild the Pod. TKE native nodes provide in-place Pod configuration adjustment capability, with which you can adjust the request/limit values of the Pod CPU and memory without restarting the Pod.
Prerequisites
This feature is available only to native nodes.
Supported cluster versions: Kubernetes v1.16 or later with minor versions as follows:
kubernetes-v1.16.3-tke.30 or later
kubernetes-v1.18.4-tke.28 or later
kubernetes-v1.20.6-tke.24 or later
kubernetes-v1.22.5-tke.15 or later
kubernetes-v1.24.4-tke.7 or later
kubernetes-v1.26.1-tke.2 or later
During node creation, set the custom kubelet parameter: feature-gates = EnableInPlacePodResize=true. See the figure below:
Warning:
Adding the current feature-gates parameter to the existing node will trigger restarting the Pod on the node . It is recommended to evaluate the impact on the business before execution.
Use Cases
1. Deal with traffic burst and ensure business stability
Scenario: Dynamically modifying the Pod resource parameter is suitable for temporary adjustments. For example, when the memory usage of the Pod gradually increases, to avoid triggering Out Of Memory (OOM) Killer, you can increase the memory limit without restarting the Pod.
Solution: Increase the limit value of the CPU or memory.
2. Increase CPU utilization to reduce business costs
Scenario: To ensure the stability of online applications, admins usually reserve a considerable amount of resource buffers to cope with the load fluctuations of upstream and downstream links. The container's request configuration will be far higher than its actual resource utilization, resulting in low resource utilization of the cluster and a large amount of resource waste.
Solution: Decrease the request value of the CPU or memory.
Case Demo
Verification
Increase the memory's limit value of a running business Pod from 128Mi to 512Mi, and check that the new limit value takes effect and the Pod is not rebuilt.
Verification steps
1. Kubectl creates the pod-resize-demo.yaml file with the following content. The memory's request value is set to 64Mi and the limit value is 128Mi.
# Kubectl command:
kubectl apply -f pod-resize-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo
namespace: kather
spec:
containers:
- name: app
image: ubuntu
command: ["sleep", "3600"]
resources:
limits:
memory: "128Mi"
cpu: "500m"
requests:
memory: "64Mi"
cpu: "250m"
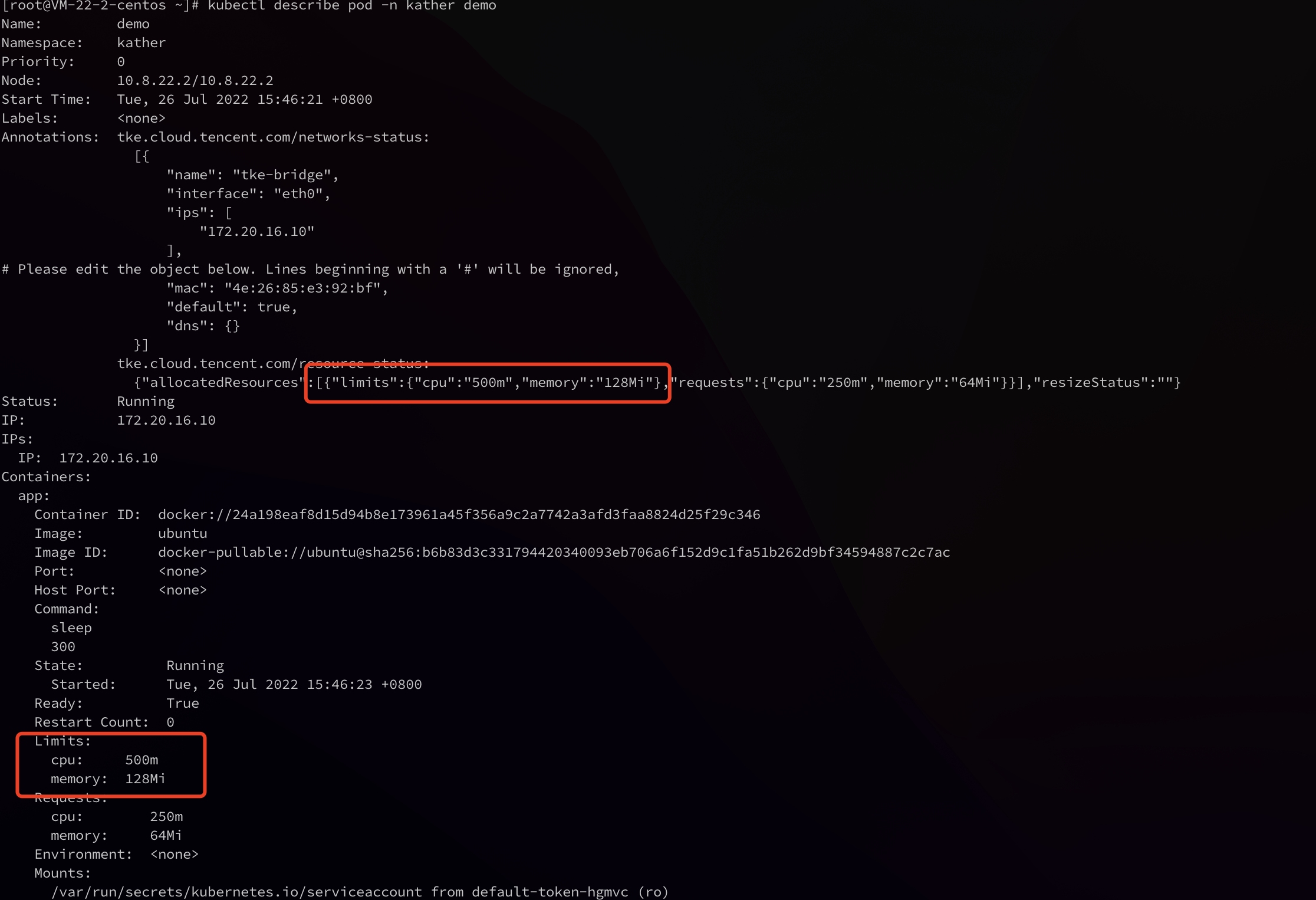
2. Check the resource value of the Pod whose configuration is to be adjusted.
# Kubectl command:
kubectl describe pod -n kather demo
As shown in the figure below, the Annotations part of a Pod whose configuration is adjustable contains the tke.cloud.tencent.com/resource-status field, which marks the Pod's current in-use resources and configuration adjustment status. The expected Pod resource values will be marked on each container.
3. Update Pod configuration.
Assume that you want to increase the limit value of the Pod memory. Use kubectl to change the value of the pod.spec.containers.resources.limits.memoy field from 128Mi to 512Mi.
# Kubectl command:
kubectl edit pod -n kather demo
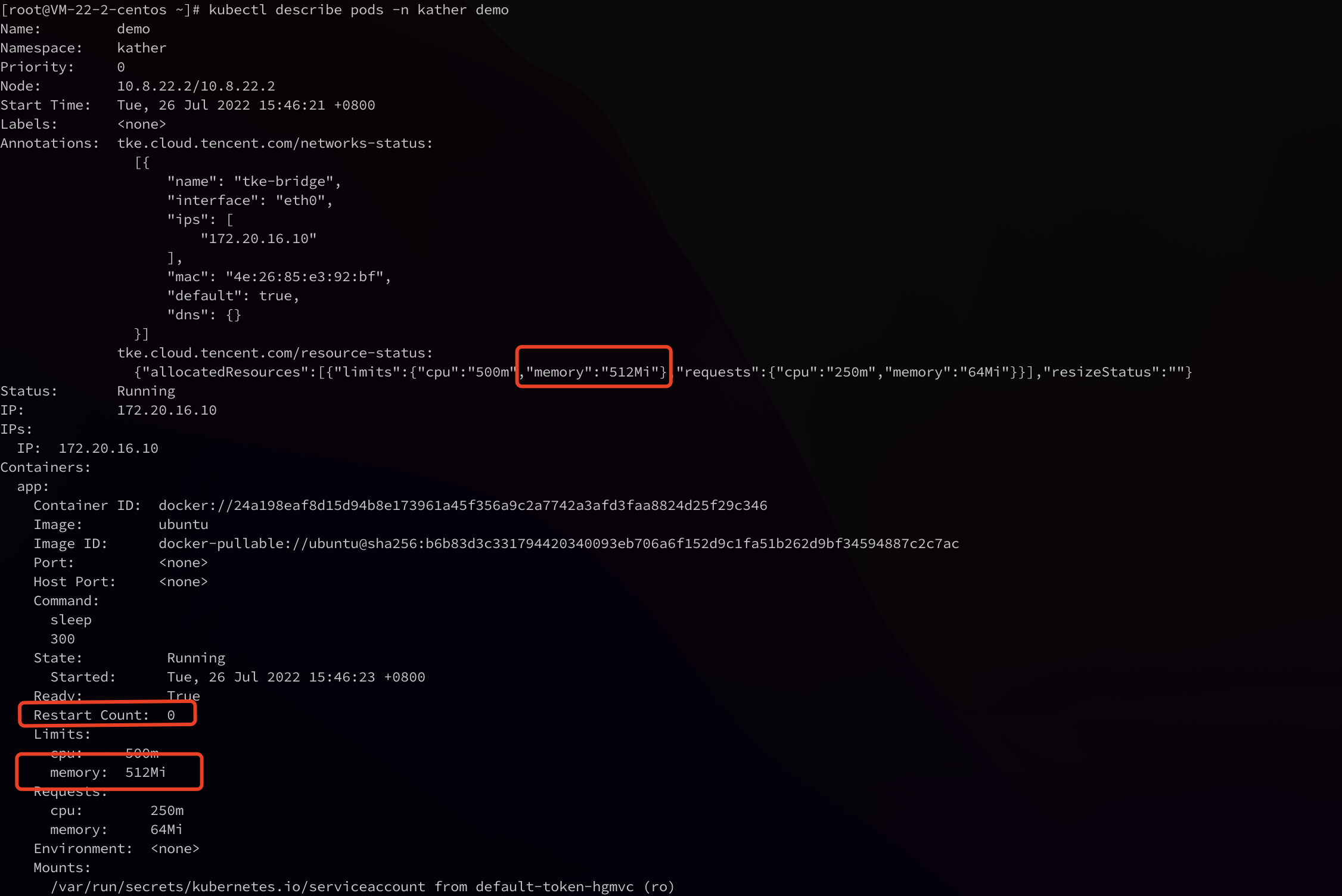
4. Run the following command to check the running status of the Pod.
# Kubectl command:
kubectl describe pod -n kather demo
As shown in the figure below, the memory values in Pod spec and Annotations are changed to the expected value "512Mi", and the value of Restart Count is 0.
5. Verify the in-place Pod configuration adjustment.
After you locate the container by using the docker or ctr command, you can see that the memory limit in the container metadata has been changed. If you enter memory cgroup, you will see that the memory limit has also been changed to the expected value "512Mi".
1. Kubelet stores the Pod's current in-use resources and configuration adjustment status in JSON format in tke.cloud.tencent.com/resource-status in Annotations, where, the resizeStatus field indicates the configuration adjustment status. For more information, see Configuration Adjustment Status.
2. Resources in pod.spec.containers.resources are the expected resources, which are expected to be allocated to the Pod. If the current expected resource is modified, kubelet will try to modify the Pod's actual resource and write the final result to Annotations.
Note
The implementation of in-place Pod configuration adjustment is based on Kubernetes Enhancement Proposal 1287.
Configuration Adjustment Status
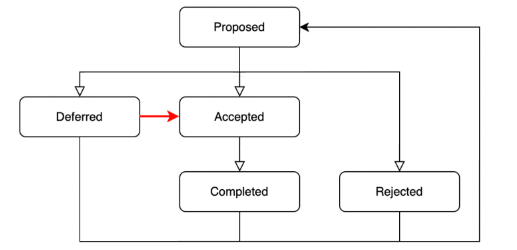
The Kubernetes community adds some fields to Pod.Status in later versions to display the configuration adjustment status. This status works with Kube Scheduler to implement scheduling. Similar fields, including the Pod's actual resources and current configuration adjustment operation status, are added to Pod Annotations of TKE native nodes.
Status
Description
Remarks
Proposed
The Pod configuration adjustment request is submitted.
-
Accepted
Kubelet discovers that Pod resources have been modified and the node resources are sufficient to admit the Pod after the configuration adjustment.
-
Rejected
The Pod configuration adjustment request is rejected.
Rejection reason: The expected requests resource value after Pod configuration adjustment is greater than the node's allocated value.
Completed
The Pod resource is successfully modified, and the adjusted resource is set in the container.
-
Deferred
The current configuration adjustment is deferred due to certain issues and will be triggered again upon next Pod status change.
Possible issues:
The current node resources are insufficient: Allocated amount of node resources - Amount of resources occupied by other Pods < Amount of resources required by the Pod whose configuration is to be adjusted.
Failed to store the status.
The execution status of Pod configuration adjustment is as shown below:
Use Limits
To give priority to ensuring the stability of business Pod operation, it is necessary to carry out some operational restrictions on the in-place Pod configuration adjustment capability:
1. Allow only the CPU and memory resources of the Pod to be modified.
2. Allow Pod resource modification only when PodSpec.Nodename is not empty.
3. The resource modification scope is as follows:
The limit value of each container in a Pod can be increased or decreased: Decreasing the CPU limit value may cause traffic to slow down, and decreasing the memory limit value may fail (kubelet will retry decreasing memory in a subsequent syncLoop).
The request value of each container in the Pod can be increased or decreased, but the highest container request value cannot be greater than the container limit value.
4. For containers with no request or limit value specified:
For a container with no limit value specified, a new value cannot be set.
For a container with no request value specified, the lowest value cannot be smaller than 100m.
5. When a request or limit value is modified, the QoS type cannot be changed between burstable and guaranteed. You need to modify both the request and limit values to maintain the same QoS during configuration adjustment.
For example, [cpu-request: 30, cpu-limit: 50] can only be adjusted to [cpu-request: 49, cpu-limit: 50] and cannot be adjusted to [cpu-request: 50, cpu-limit: 50].