Data sync refers to the process of syncing data between two data sources in real time. It is suitable for cloud-local active-active, multi-site active-active, and cross-border data sync as well as real-time data warehousing.
While data migration involves moving the entire database in one go and requires a manual cutover to the new database upon completion, data sync is an ongoing process that will keep the data synced (in near real time) between the source and target databases to ensure consistency.
DTS supports local-cloud sync, cross-cloud sync, and cross-TencentDB database sync.
Local-cloud sync: DTS can sync an IDC-based self-built database to a TencentDB instance and vice versa.
Cross-cloud sync: DTS can sync a third-party cloud database to TencentDB instance.
Cross-TencentDB instance sync: DTS can sync TencentDB instances in various scenarios, such as multi-site active-active, cross-border, and cross-Tencent Cloud account sync.
How It Works
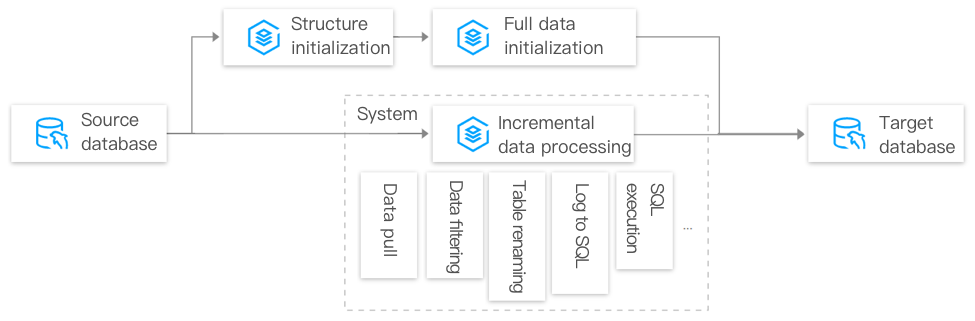
The following takes MySQL as an example to describe the data sync process: Data is exported from the source database and then imported to the target database. Key steps include structure initialization, full data initialization, and incremental data processing.
Structure initialization
Structure initialization means creating the same table structure information in the target database as that in the source database. When configuring a sync task, you can select whether to sync the table structure. If the target database already contains the same structure information, you simply need to sync the data; otherwise, you'll need to sync the database/table structure information as well.
Full data initialization
After structure initialization is completed, DTS will initialize the existing data, that is, export all existing data from the source database and import it to the target database.
Incremental data processing
In the incremental data processing stage, DTS continuously obtains the incremental data through the source database's binlog and persistently stores such data in the intermediate storage after a series of filtering and conversion operations. After importing the full data, it continuously replays the changed incremental data stored in the intermediate storage on the target database in order to ensure data consistency between the source and target databases.
Data Conflict Resolution
During a DTS sync task, the data in the source and target databases may have conflicts. DTS can check for duplicate table name and primary key conflicts.
Duplicate table name conflict
If the source and target databases have tables with the same name, the task can be configured to report an error (Precheck and report error) or append the source database data to the table with the same name in the target database (Ignore and execute).
Primary key conflict
DTS can check for primary key conflicts and provides the following conflict resolution methods. For specific implementation examples, see Selecting Data Sync Conflict Resolution Policy.
Report: During a sync task, if an INSERT statement in the source database has a primary key conflict with the data in the target database, the task will report an error and pause. You need to handle the conflict manually first before proceeding.
Ignore: During a sync task, if an INSERT statement in the source database has a primary key conflict with the data in the target database, the data inserted into the source database will be ignored, and the data in the target database will prevail.
Overwrite: During a sync task, if an INSERT or UPDATE statement has a primary key conflict with the data in the target database, the data in the target database will be overwritten by the inserted or updated data in the source database.
Lock-Free Data Sync Logic
In MySQL's full data replication process, a global lock (FTWRL) is generally added in the source database to obtain the binlog offset in incremental data sync, but it can block data writes from the source database for a few seconds during the locking process.
DTS, on the other hand, allows you to sync full data without adding the global lock (FTWRL) to the source database. Note that the lock-involved or lock-free sync logic only makes sense for the full data sync scenario where you have selected "Full data initialization" for the "Initialization Type" parameter in the console.
Links that support lock-free sync
Data sync among MySQL, MariaDB, Percona, TDSQL-C for MySQL, TDSQL Boundless, Kafka and TDSQL for MySQL is implemented without locks by default. In the full data sync stage, no global lock (FTWRL) is added to the source database, and only tables without a primary key are locked.
Special lock-involved scenario
Lock-involved data sync is required when the primary key conflict policy is "Report".
When the source database is Alibaba Cloud ApsaraDB RDS 5.5/5.6, PolarDB 5.5/5.6, Amazon RDS for MySQL on all versions, or Amazon Aurora, data sync is implemented without locks by default. However, if the primary key conflict policy is "Report" for the related data sync links, it won't take effect in the full data sync stage but in the incremental sync stage.
Supported Topologies
The basic sync service is one-way sync. When configuring a sync task, you can choose to sync data definition language (DDL) or data manipulation language (DML) operations. By combining one-way sync tasks, you can customize various complex topologies.
In a complex topology, technical measures will be used for DML operations to avoid a data loop. For DDL operations, the data sync service will perform the loop check during configuration to avoid forming any DDL loop.
You can use DTS to sync data between databases in multiple regions in real time to implement multi-site active-active deployment. Database instances in each region can run in the cloud or your self-built IDC.
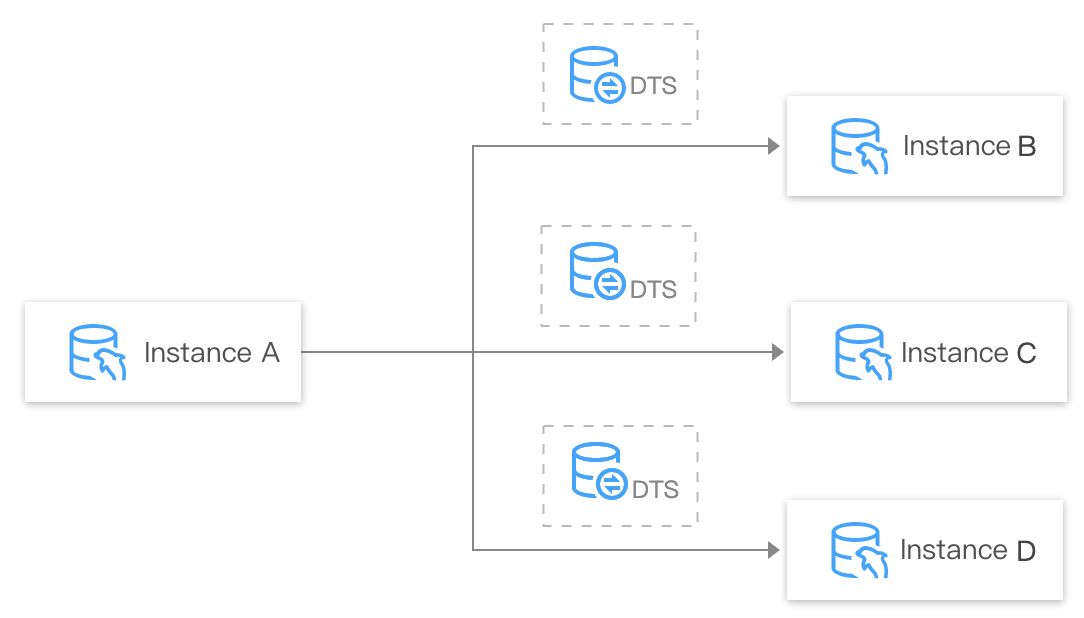
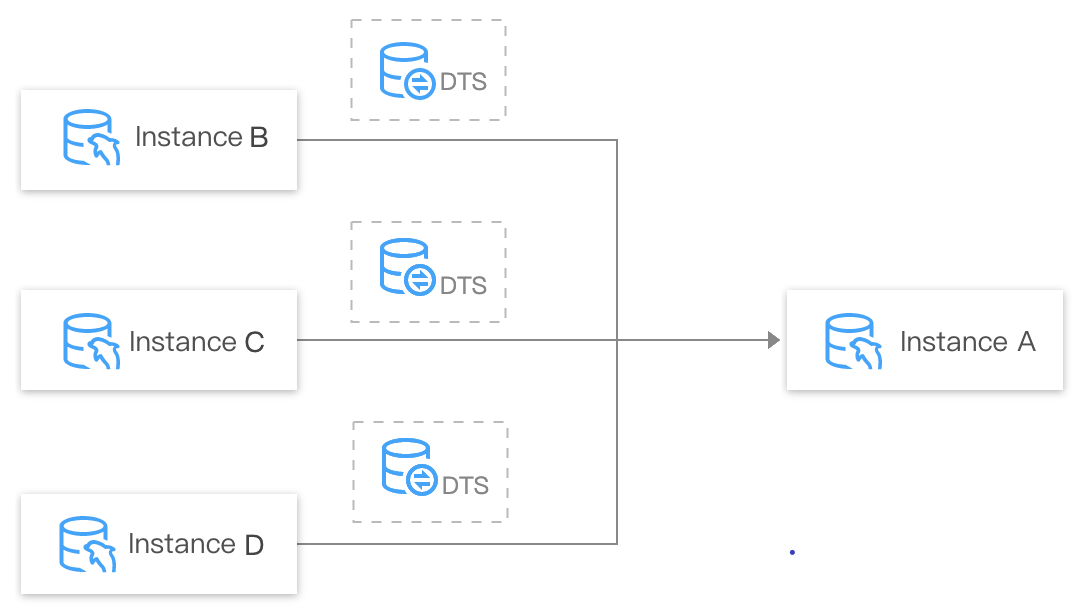
Many-to-one sync
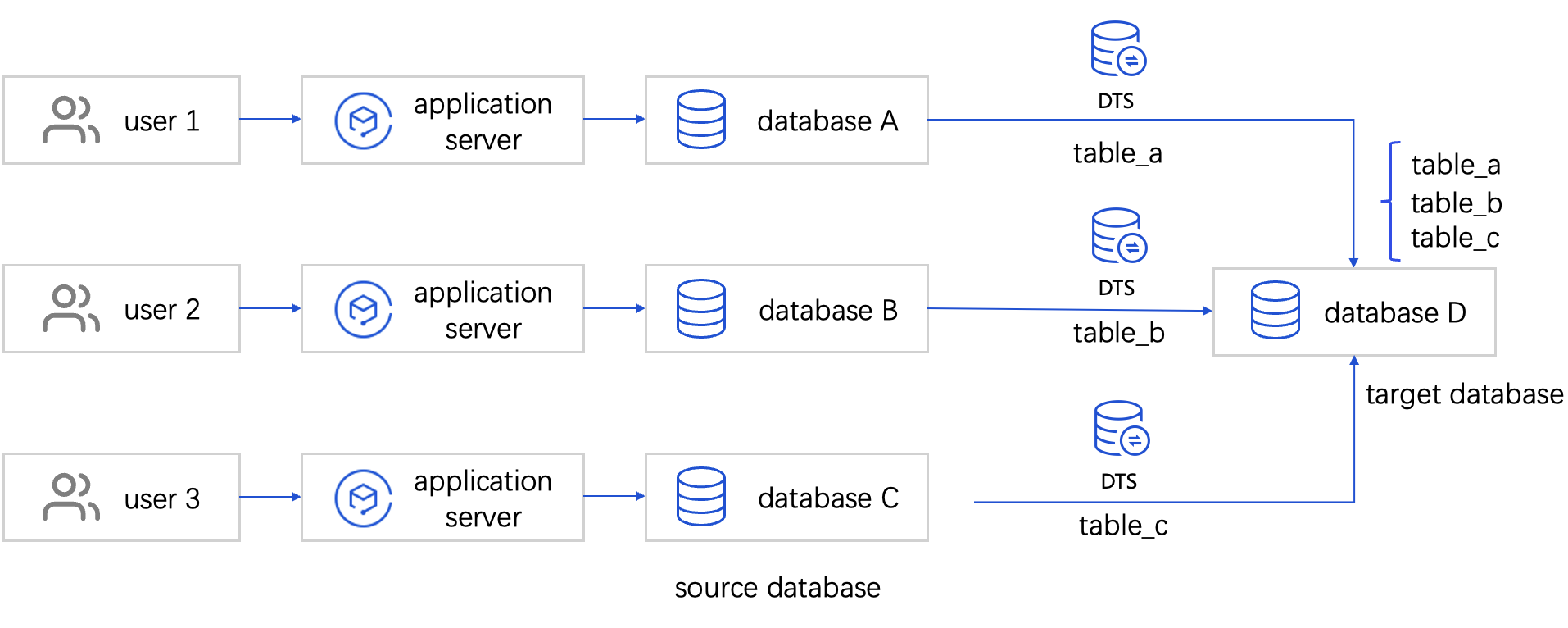
You can use DTS to sync data from multiple source databases to one target database for data integration and aggregate analysis.
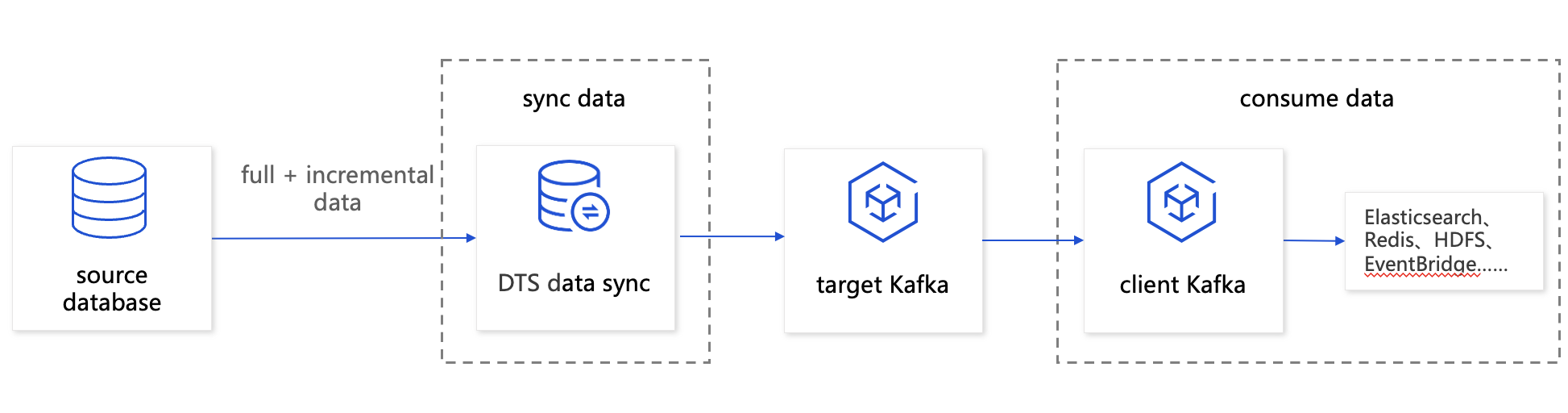
Data sync to Kafka
You can use DTS to deliver the source database data to Kafka to obtain the full + incremental data of the source database. This feature is suitable for data archiving and analysis scenarios.
Restrictions
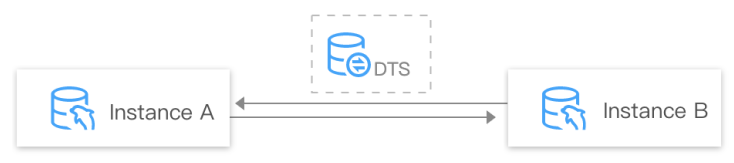
You can implement two-way sync by combining one-way sync tasks, but there are the following restrictions:
To ensure data consistency, your business needs to avoid updating the data record with the same primary key on two nodes; otherwise, a primary key conflict or mutual overwrite may occur. For example, you can choose to update the data records with primary keys 1, 3, and 5 on node A and data records with primary keys 2, 4, and 6 on node B.
If a data sync conflict occurs, DTS will process the data strictly according to the selected conflict resolution policy. You need to confirm whether the corresponding policy meets your business expectation during configuration.
Two-way sync is supported for DML statements, while only one-way sync is supported for DDL statements. To implement two-way sync, ensure that DDL sync is disabled in one of the one-way instances.
Supported Database Types
For more information on the source and target database types, versions, and sync types supported for data sync, see Databases Supported for Data Sync.
Supported Features
Feature
Description
Documentation
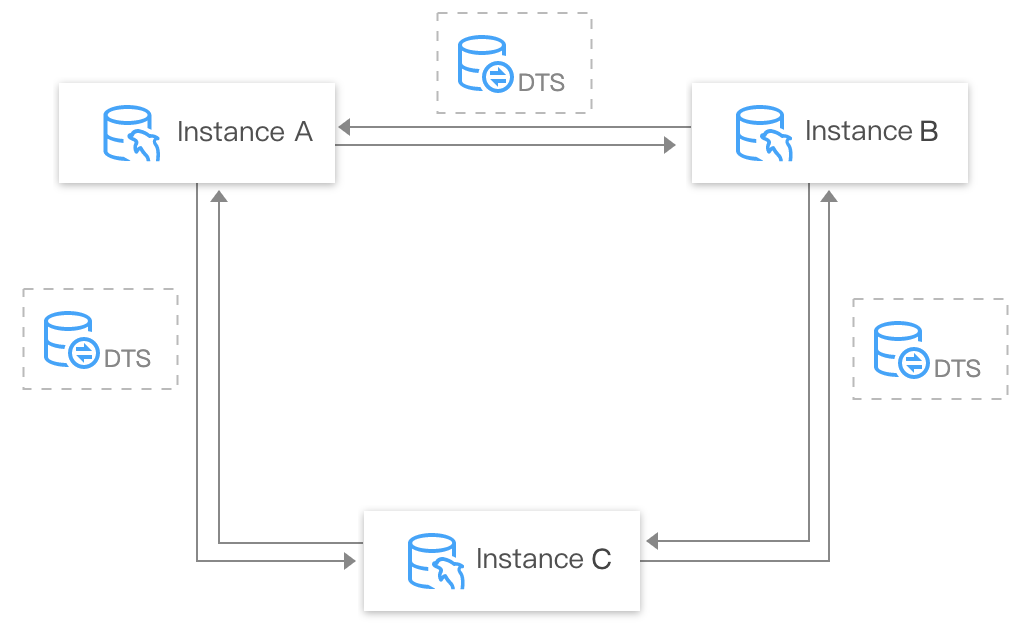
Two-way sync, ring sync, and many-to-one sync
DTS supports complex sync topologies such as two-way sync, ring sync, and many-to-one sync.
DTS supports the cross-version sync for most databases.
The target database version should be the same as or later than the source database version; for example, data on v5.5.x can be synced to v5.5.x, v5.6.x, or later. The minor version is represented by the last digit, and it is unrestricted.
-
Table conflict check
DTS provides the duplicate table name check policy.
-
Primary key conflict check
The following three primary key conflict resolution policies are supported:
Report: If a primary key conflict of tables is found during data sync, the system will report an error and pause the data sync task.
Ignore: If a primary key conflict is found during data sync, the system will keep the primary key record in the target database.
Overwrite: If a primary key conflict is found during data sync, the system will use the primary key record in the source database to overwrite that in the target database.
When lock-free sync is implemented, no global lock (FTWRL) will be added to the source database and only tables without a primary key are locked in the full data sync stage.
-
Task progress visualization
DTS supports displaying information such as the sync steps and progress.
During incremental data sync, the source and target instances can be restarted or upgraded.
-
HA switch
If GTID is enabled, HA switch of the source instance is supported.
HA switch of the target database is supported.
-
Sync of online DDL temp tables
If you perform an online DDL operation on tables in the source database with the gh-ost or pt-osc tool, DTS can sync the temp tables generated by online DDL changes to the target database.
After a sync task is started, if there are too many connections to the source database or the business needs to be adjusted, you can pause the task and resume it after the source database can handle the load or the business adjustment is completed.
If the sync task is temporarily interrupted due to a network error or other issues, DTS will automatically retry and resume the task within the set time range.
DTS supports the secure connection between DTS and the source/target database through SSL that encrypts the transfer link.
-
XA transaction
DTS can identify the XA transactions operated in the source database and parse the data synced to the target database based on the XA transaction logic.
If an XA transaction rollback occurs in the source database, the rollback and the pre-rollback SQL statements in the source database won't be synced to the target database.