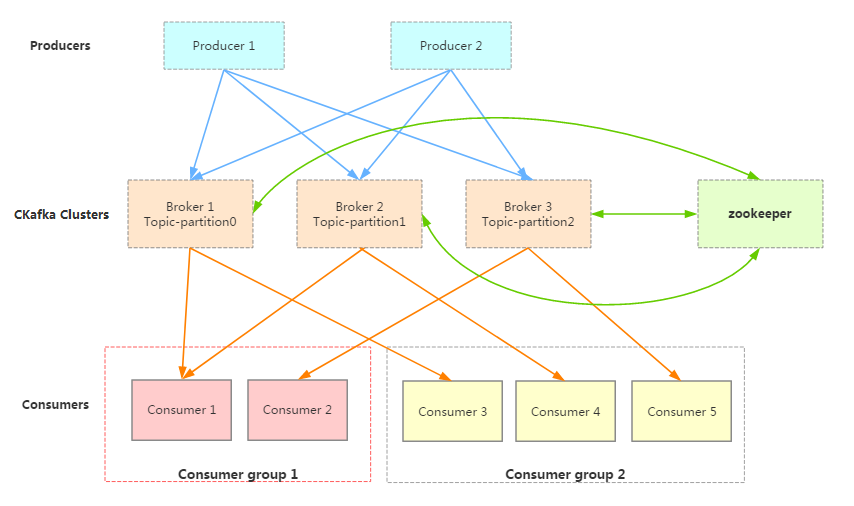
A producer can be information such as messages generated by webpage activities and service logs. It publishes messages to CKafka's broker cluster in push mode.
ZooKeeper is used to manage the cluster configuration, elect the leader, implement fault tolerance, and do more in the cluster.
Consumers are divided into several consumer groups. A consumer consumes messages from the broker in pull mode.
For the advantages of CKafka over self-built open-source Apache Kafka, see Strengths.
High Throughput
In CKafka, a huge amount of network data is permanently stored in disks and high numbers of disk files are sent over the network. The performance of this process directly affects Kafka's overall throughput, especially in the following aspects:
Improved disk utilization: data is read and written sequentially in the disk, which helps increase the disk utilization.
Message write: messages are written to the page cache and flushed by the async thread.
Message read: messages are transferred directly from the page cache into the socket and then sent out.
If the corresponding data is not found in the page cache, disk IO will be caused, and the messages will be loaded from the disk to the page cache and then sent out directly from the socket.
Broker's zero copy mechanism: the sendfile system is called to send data directly from the page cache to the network.
Reduced network overheads
Data compression reduces the network load.
Batch processing mechanism: the producer writes data to the broker in batch, while the consumer pulls data from the broker in batch.
Data Persistence
Data persistence is mainly implemented in CKafka through the following principles:
Partition storage distribution in topic
In the file storage of CKafka, a topic has multiple different partitions, each of which physically corresponds to a folder. Messages and index files are stored in these partitions. For example, if two topics are created where topic 1 has 5 partitions and topic 2 has 10 partitions, then a total of 5 + 10 = 15 folders will be generated in the cluster.
File storage method in partition
A partition is physically composed of multiple segments of equal size. These segments are read from/written to sequentially and are deleted quickly upon expiration, which improves the disk utilization.
Scale-out
One topic can include multiple partitions distributed in one or more brokers.
One consumer can subscribe to one or more of these partitions.
A producer is responsible for equally assigning messages to partitions.
Messages in partitions are sequential.
Consumer Group
CKafka does not delete consumed messages.
A consumer must belong to a group.
Consumers in the same consumer group do not consume the same partition at the same time.
Different groups consume the same message at the same time, which is more diversified (queuing model and publish-subscribe model).
Multiple Replicas
The multi-replica design can enhance the system availability and reliability.
Replicas are evenly distributed across the entire cluster. The replica algorithm is as follows:
1. All brokers (assuming n brokers in total) and the partitions to be assigned are sorted.
2. The ith partition is assigned to the (i mod n)th broker.
3. The jth replica of the ith partition is assigned to the ((i + j) mod n)th broker.
Leader Election Mechanism
CKafka dynamically maintains a set of in-sync replicas (ISR) in ZooKeeper, and all replicas in ISR catch up to the leader. Only members of the ISR can be elected as leaders.
If there are f + 1 replicas in ISR, a partition can
tolerate f replica failures while guaranteeing that committed message will not be lost.
If there is a total of 2f + 1 replicas (including the leader and followers), it must be guaranteed that f+1
replicas have replicated the messages before the commit operation. To ensure that a new leader can be correctly elected, the number of failed replicas cannot exceed f.

 Yes
Yes
 No
No
Was this page helpful?