Scenarios
Download
Mode fokus
Ukuran font
Overview
TDMQ for CKafka (CKafka) is widely used in domains that require large-scale data exchange, such as logs, big data, and other upstream and downstream processes, including webpage tracking and behavior analytics, log aggregation, monitoring/linkage data aggregation, streaming data processing, and online and offline analysis.
You can simplify data integration in the following ways:
Import messages from CKafka into Tencent Cloud's products such as Cloud Object Storage (COS) and Stream Compute Service (SCS).
Connect CKafka to other cloud products through Serverless Cloud Function (SCF) triggers.
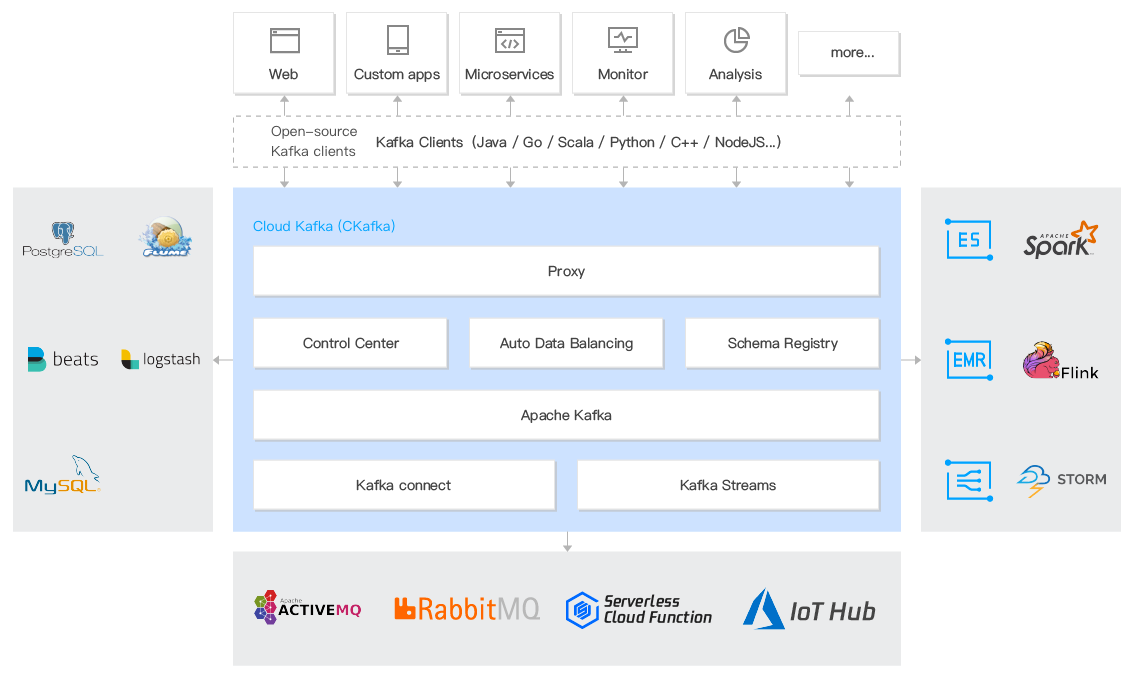
Webpage Tracking
Client browsers and applications send messages to CKafka topics by processing website activities in real time, such as page views (PVs), searches, and other user activities, based on behavior types. These data streams can be used for real-time monitoring or offline statistical analysis.
Since each user's PVs generate a large amount of activity information, website activity tracking requires high throughput. CKafka can meet the requirements of high throughput and offline processing.
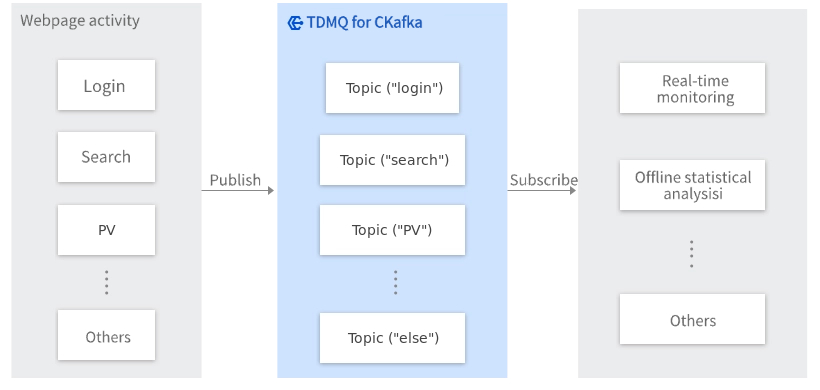
Log Aggregation
CKafka's high-throughput and low-latency processing characteristics easily support multiple data sources and distributed data processing (consumption). Compared to centralized log aggregation systems, CKafka can achieve stronger persistence guarantees and lower end-to-end latency under the same performance conditions.
CKafka's characteristics make it ideally suited as a log collection hub. Multiple hosts and applications can asynchronously send operation logs to CKafka clusters in batches without storing them locally or in databases. CKafka can submit messages in batches, imposing almost imperceptible performance overhead on producers. Consumers can then use specialized storage and analysis systems like Hadoop, Flink, and Spark to perform statistical analysis on the pulled logs.
Big Data Scenarios
In certain big data-related business scenarios, it is necessary to process and aggregate large volumes of concurrent data, which imposes high demands on cluster processing performance and scalability. CKafka's implementations in data distribution mechanisms, disk storage allocation, message format processing, server selection, and data compression make it suitable for handling massive real-time messages. It can aggregate data from distributed applications, facilitating system Ops.
In specific big data scenarios, CKafka well supports the processing of offline data and streaming data, and facilitates operations such as data aggregation and analysis.
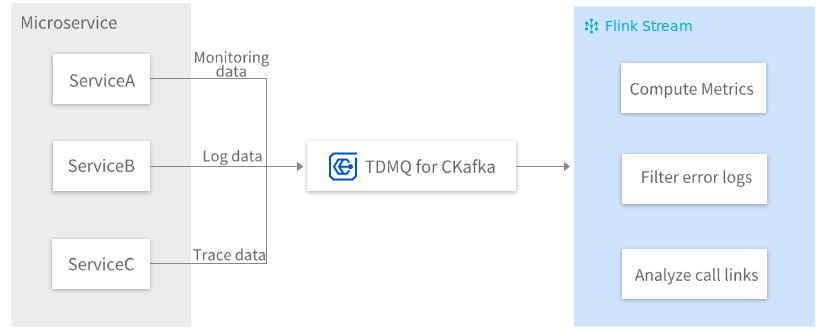
User Linkage Observability
In a typical microservice architecture, the system consists of multiple independent services, each generating substantial monitoring data (such as CPU and memory utilization), log data (such as request logs and error logs), and trace data (such as service call chains). To achieve comprehensive system observability, the data can be uniformly collected and sent to CKafka. Downstream systems then consume the data in real time through Flink Stream for aggregation, analysis, and exception detection, enabling the Ops team to rapidly identify and resolve issues, thereby enhancing system stability and maintainability.
IoT Data Collection and Distribution
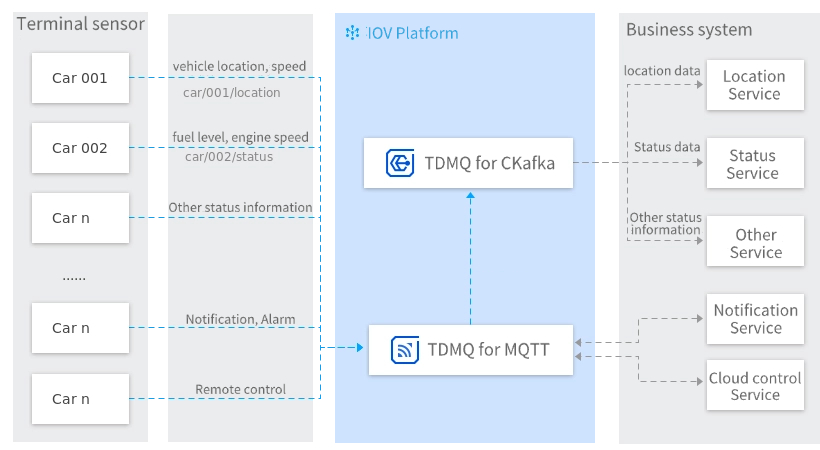
In Internet of Things (IoT) scenarios, devices deliver data to CKafka through the MQTT protocol, which is then distributed to different systems through rules engines for further processing. For example, vehicles collect various information through onboard sensors and controllers, such as the position of vehicles, speed, fuel levels, and engine status. This data needs to be transmitted to the automaker's servers in real-time or periodically for operations like data analysis, fault prediction, and remote control.
Terminal devices access TDMQ for MQTT through the MQTT protocol and connect to CKafka clusters through rule engines to forward data.
Internet of Vehicles (IoV) service platforms, high-precision map services, location-based services, and other IoV-related applications can directly consume data by subscribing to CKafka. Simultaneously, bidirectional communication for vehicle control (remote control) messages is achieved through TDMQ for MQTT.
SCF Trigger
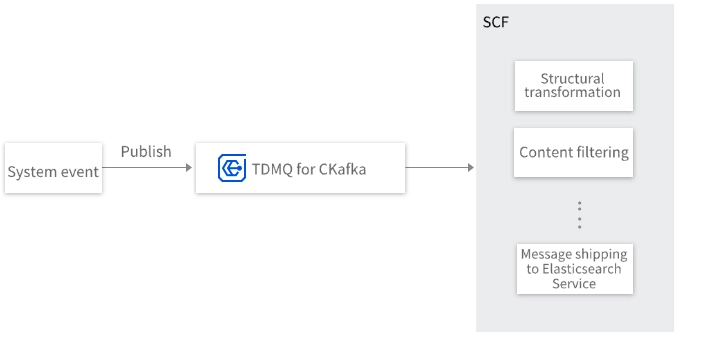
CKafka can serve as a Serverless Cloud Function (SCF) trigger. When messages are received in a message queue, SCF is triggered, and the messages are passed as event content to SCF. For example, when triggered by CKafka, SCF can perform operations such as structural transformation and content filtering on the messages, or deliver them to Elasticsearch Service (ES).
Note:
Bantuan dan Dukungan
Apakah halaman ini membantu?
Anda juga dapat Menghubungi Penjualan atau Mengirimkan Tiket untuk meminta bantuan.
masukan