CKafka Pro Edition supports multi-AZ deployment. When you purchase a CKafka instance in a region that has three or more AZs, you can select up to four of them for multi-AZ deployment. Partition replicas of this instance will be forcibly distributed across the nodes in the three AZs, which enables your instance to provide services uninterruptedly when one AZ becomes unavailable.
Note:
Only the Pro Edition supports multi-AZ deployment.
How multi-AZ deployment of CKafka works
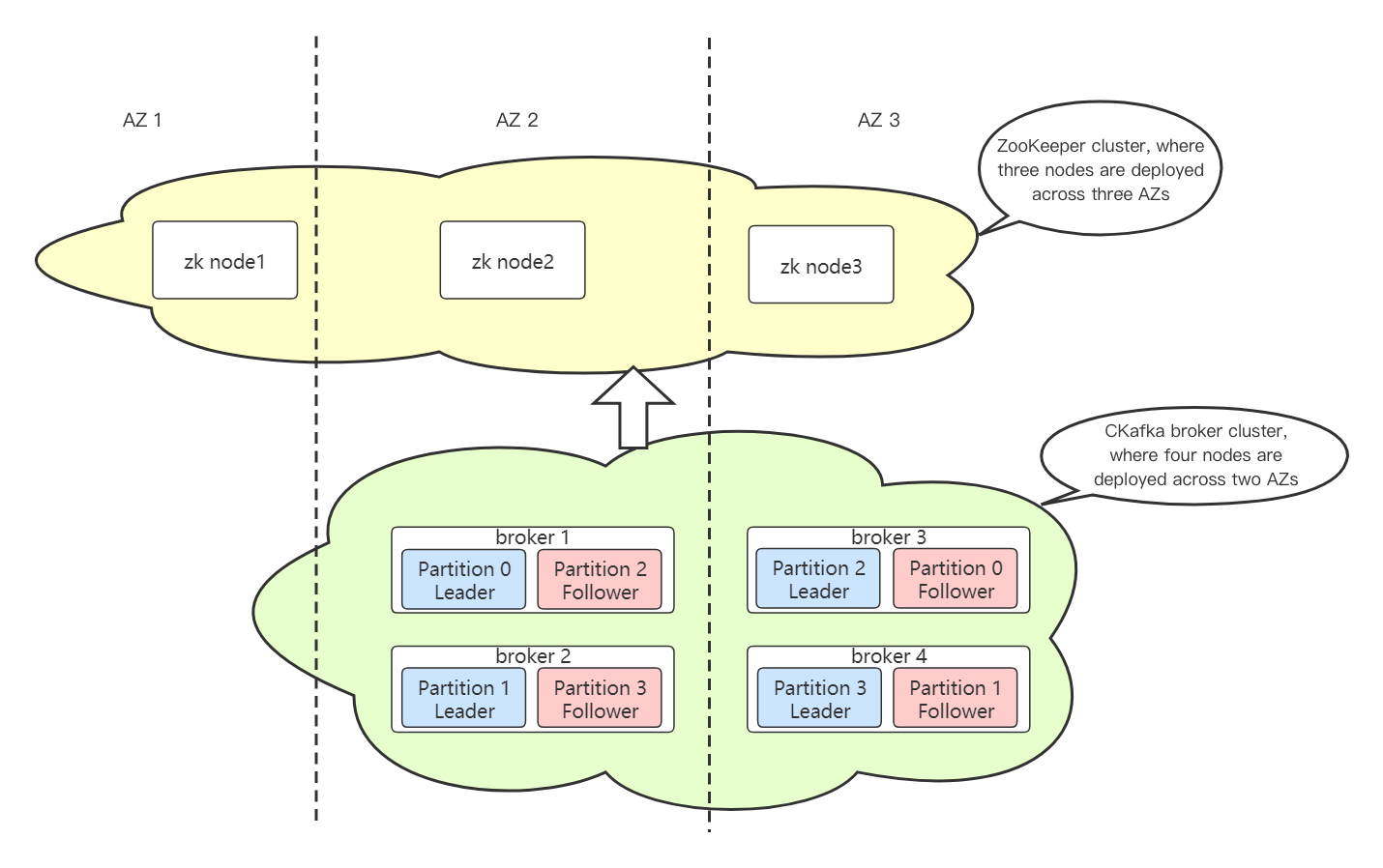
The multi-AZ deployment feature of CKafka involves three layers: network, data, and control.
Network layer
CKafka exposes a VIP to the client. After the client is connected to the VIP, it will get the metadata information (which is generally addresses mapped one to one at different ports on the same VIP) of the topic partitions .
This VIP can fail over to another AZ at any time. When an AZ becomes unavailable, the VIP will automatically shift to another AZ in the same region, thus achieving multi-AZ disaster recovery.
Data layer
The data layer of CKafka is deployed in the same distributed way as Kafka; in other words, multiple data replicas are distributed on different broker nodes which are deployed in different AZs. When a partition is processed, there will be a leader-follower relationship between such nodes. When the leader goes offline due to an exception, the cluster controller will elect a new partition leader to handle the requests for the partition.
For the client, after an AZ becomes unavailable due to an exception, if the leader of a topic partition is located on a broker node in the AZ, the originally established link will time out or be closed. After an exception occurs on the leader node of the partition, the controller will elect a new leader node to provide services, and if the controller node is also abnormal, the remaining nodes will run for a new controller node. The leader switch can be completed within seconds (proportional to the number of nodes in the cluster and the size of the metadata). The client will periodically refresh the metadata of the topic partitions and link the new leader node for production and consumption.
Control layer
The control layer of CKafka applies the same technical scheme as Kafka. It relies on ZooKeeper to manage service discovery and cluster controller election for broker nodes. The ZK nodes in the ZooKeeper cluster of a CKafka instance that supports multi-AZ deployment are deployed in three AZs (or data centers). In this way, even if the ZK nodes in any AZ fail and disconnect, the entire ZooKeeper cluster can still provide services.
Pros and Cons of Multi-AZ Deployment
Pros
Multi-AZ deployment can significantly improve the disaster recovery capability of the cluster. When a single AZ experiences force majeure events such as network instability and restart after power outage, the client can resume message production and consumption after waiting a short while to reconnect.
Cons
In multi-AZ deployment mode, as partition replicas are distributed in multiple AZs, message replication across AZs experiences an additional network latency compared with message replication in one single AZ, which directly affects the client write time for production (the client ACK parameter is greater than 1 or equal to -1 or all). Currently, the network latency across AZs in major regions such as Guangzhou, Shanghai, and Beijing typically ranges between 10 ms and 40 ms.
Multi-AZ Deployment Scenarios
Unavailability of one single AZ
After a single AZ becomes unavailable, as explained above, the client will disconnect, reconnect, and then provide services normally after reconnection.
As multi-AZ deployment is currently not supported for the management of API services, after a single AZ becomes unavailable, you may not be able to create topics, configure ACL policies, or view monitoring data in the console, but this will not affect the production and consumption of existing businesses.
Network isolation between two AZs
If network isolation occurs between two AZs (that is, they cannot communicate), a cluster "split-brain" event may occur; in other words, the nodes in both AZs provide services, but data written in one of the AZs will be treated as dirty data after the cluster is recovered.
Suppose network isolation occurs between the cluster controller node and a ZK node in the ZooKeeper cluster and other nodes, other nodes will run for a new controller (which can be successfully elected since most nodes in the ZooKeeper cluster communicate normally over the network), but the isolated controller still regards itself as the controller node. In this case, a "split-brain" event occurs in the cluster.
At this time, the client writes need to be considered on a case by case basis. For example, when the client's ACK is set to -1 or all and the number of replicas is two, if the cluster contains three nodes, they will be distributed in a 2:1 ratio after the split-brain event occurs. In this case, an error will be reported when the original leader writes to the partitions in the AZ with one node, while writes in the other AZ will succeed. However, if the number of replicas is three and ACK = -1 or ACK = all is configured, writes on neither AZ will succeed. Therefore, you need to take further actions based on the specific parameter configuration.
After the cluster network is back to normal, the client can resume production and consumption without performing any operations. As the server will normalize the data again, the data on one of the split nodes will be truncated directly, which, however, will not result in data loss in case of multi-replica multi-AZ data storage.
Region: Select a region close to the resource for client deployment.
AZ: Select an AZ based on your actual needs.
Standard Edition: This edition does not support multi-AZ deployment.
Pro Edition: If the current region supports multi-AZ deployment, you can select up to three AZs for deployment. For more information on multi-AZ deployment, see Multi-AZ Deployment.
Product Specification: Select a model based on the peak bandwidth and disk capacity.
Message Retention Period: Select a value between 24 and 2,160 hours.
When the disk capacity is insufficient (that is, the disk utilization reaches 90%), old messages will be deleted in advance to ensure the service availability.
VPC: If you need to access other VPCs, you can modify the routing access rules as instructed in Adding Routing Policy.
Tag: It is optional. For more information, see Tag Overview.
Instance Name: When purchasing multiple instances, you can batch create instances by its numeric suffix (which is numbered in an ascending order) or its designated pattern string. For detailed directions, see Naming with Consecutive Numeric Suffixes or Designated Pattern String.
4. Click Buy Now to complete the instance creation process.

 Yes
Yes
 No
No
Was this page helpful?