Custom Consumption is an SDK developed in-house by CLS, designed to efficiently obtain and process log data from the cloud. Its core mechanism leverages consumer groups for collaboration. Based on the principle of server-automated CLB, it dynamically allocates tasks when the number of consumers or log partitions changes, thereby ensuring continuity and non-duplication in data processing. It is a highly reliable and scalable framework for real-time log consumption.
Consumer Group Consumption Process
When a consumer group is used to consume data, the server manages the consumption tasks of all consumers within the group. It automatically adjusts the load balancing of these tasks based on the relationship between topic partitions and the number of consumers. Concurrently, the server records the consumption progress for each topic partition, ensuring that different consumers can consume data without duplication. The specific workflow for consumer group consumption is as follows:
1. Create a consumer group.
2. Each consumer periodically sends a heartbeat to the server.
3. The consumer group automatically allocates topic partitions to consumers based on the load status of the topic partitions.
4. Based on the assigned partition list, the consumer obtains the partition offset and consumes the data.
5. The consumer periodically updates the partition consumption progress to the consumer group, facilitating the group's task allocation for the next round.
6. Repeat steps 2 - 6 until consumption is complete.
CLB Consumption Principles
The consumer group dynamically adjusts the consumption tasks for each consumer based on the number of active consumers and topic partitions, ensuring load balancing. Meanwhile, each consumer saves the consumption progress for every topic partition. This ensures that data consumption can resume after a failure, preventing duplicate consumption.
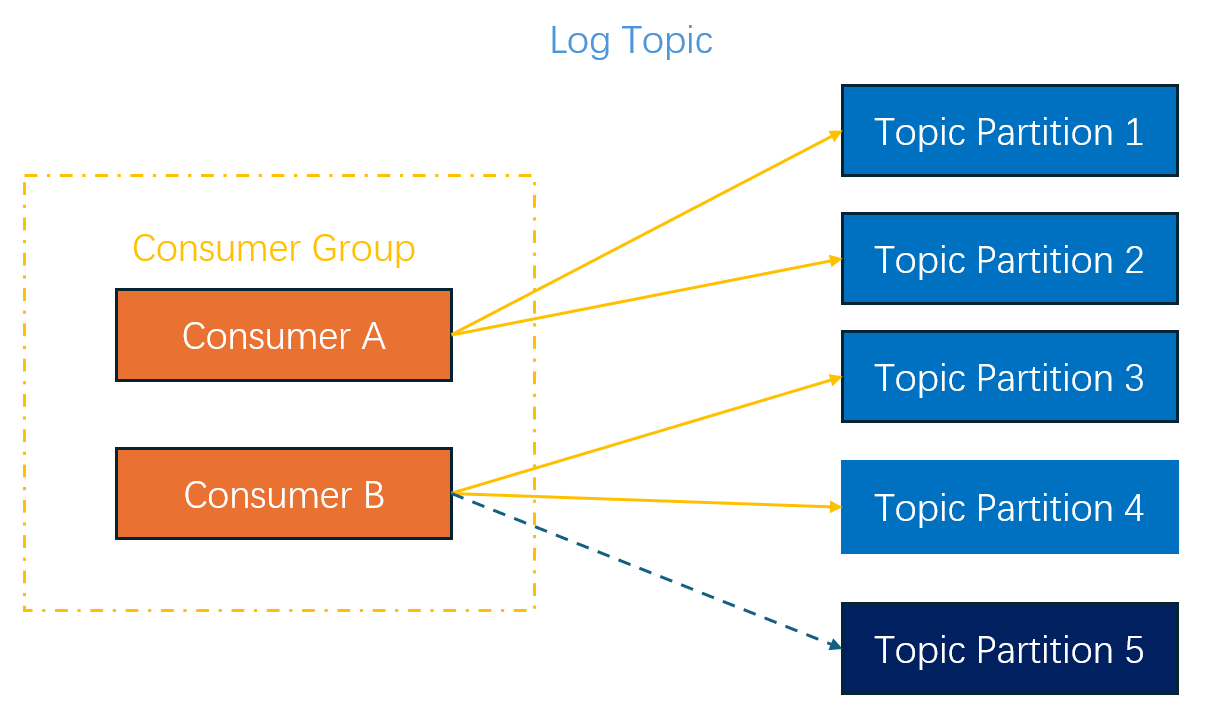
Example 1: Topic Partition Changes
For example: A log topic has two consumers. Consumer A is responsible for consuming partitions 1 and 2, while Consumer B is responsible for consuming partitions 3 and 4. After a new topic partition 5 is added via a split operation, the consumer group automatically assigns partition 5 to Consumer B for consumption, as shown in the following figure:
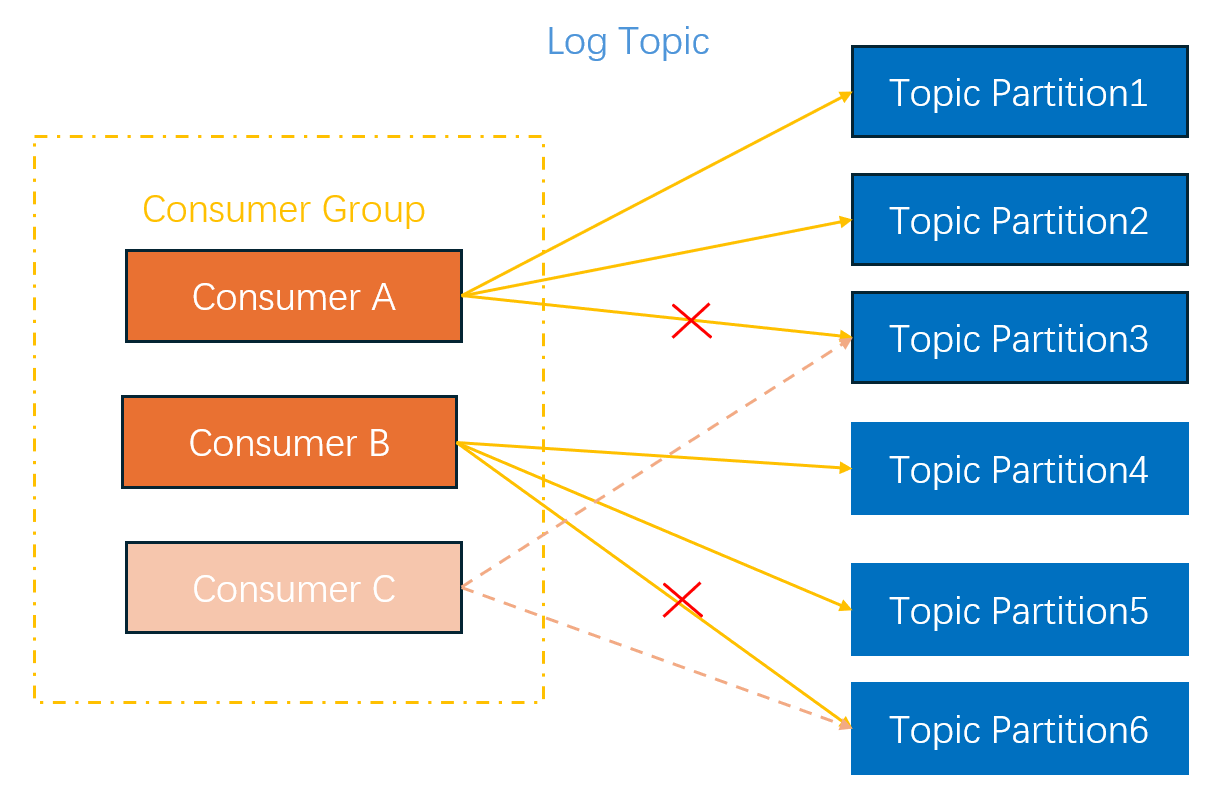
Example 2: Consumer Changes
For example: A log topic has two consumers. Consumer A is responsible for consuming partitions 1, 2, and 3, while Consumer B is responsible for consuming partitions 4, 5, and 6. When a new consumer, Consumer C, is added, the consumer group rebalances the load. It reassigns partitions 3 and 6 to the new Consumer C for consumption, as shown in the following figure:
Using Custom Consumption
Prerequisites
CLS has been activated, a logset and a log topic have been created, and log data has been successfully collected.
2. Create a consumer and start its thread. This consumer will consume data from the specified topic. Refer to Consumption Demo - Pre-filtering Consumption. This Demo provides an example of filtering logs before consumption. To achieve this, add a filter condition log_keep(op_and(op_gt(v("status"), 400), str_exist(v("cdb_message"), "pwd"))) to the consumer group Consumer. This enables the consumption of only those logs with a status code greater than 400 and containing the string "pwd" in the cdb_message field.
The region where the topic is located, for example, ap-beijing, ap-guangzhou, or ap-shanghai. For details, see Regions and Access Domain Names.
-
Supported Regions: ALL
logset_id
Yes
The logset ID. Only one logset is supported.
-
-
topic_ids
Yes
The log topic ID. For multiple topics, separate them with commas.
-
-
consumer_group_name
Yes
Consumer group name.
-
-
internal
No
Private network: TRUE
Public network: FALSE
Note:
For private/public network read traffic fees, see Product Pricing.
FALSE
TRUE/FALSE
consumer_name
Yes
Consumer name. Within the same consumer group, consumer names must be unique.
-
A string consisting of 0-9, aA-zZ, '-', '_', and '.'
heartbeat_interval
No
The interval for a consumer to report its heartbeat. If a consumer fails to report its heartbeat for two consecutive intervals, it will be considered offline.
20
0-30 minutes
data_fetch_interval
No
The interval for a consumer to fetch data, which must be no less than 1 second.
2
-
offset_start_time
No
The start time for data pulling, which is a string-type UNIX timestamp with second-level precision, for example, "1711607794". It can also be directly configured as "begin" or "end".
begin: The earliest data within the log topic's lifecycle.
end: The latest data within the log topic's lifecycle.
"end"
"begin"/"end"/UNIX timestamp
max_fetch_log_group_size
No
The size of data fetched by a consumer in a single pull. The default size is 2 MB, and the maximum size is 10 MB.
2097152
2M - 10M
offset_end_time
No
The end time for data pulling. It supports a string-type UNIX timestamp with second-level precision, for example, "1711607794". If left blank, it indicates continuous pulling.
-
-
query
No
The pre-consumption filtering parameter. It supports using pre-filtering functions to filter logs before consumption.
Note:
Only a subset of data processing functions is supported.
Only consumes logs where the status field is greater than 400 and the message field contains the keyword "access failed".
-
Note:
Consumption start time: If you have consumed data from a specified time point (such as offset_start_time=1711607794) and need to start consumption from that point again, modify the name of the consumer group.