This document introduces the basic syntax and examples of window functions.
A window function calculates the data of multiple rows and returns the calculation result. Unlike GROUP BY, it only appends the calculation result to each row of data and does not merge the rows.
Syntax
window_function (expression) OVER (
[ PARTITION BY part_key ]
[ ORDER BY order_key ]
[{ ROWS | RANGE } BETWEEN frame_start AND frame_end ])
Parameters
Parameter
Description
window_function
Specifies the window value calculation method. Aggregate functions, ranking functions and value functions are supported.
PARTITION BY
Specifies how a window is partitioned.
ORDER BY
Specifies how the rows in each window partition are ordered.
{ ROWS |RANGE } BETWEEN frame_start AND frame_end
Window frames, that is, the data range (rows) used when calculating the value of each row within the window partition. If not specified, it represents all rows within the window partition.
Example:
rows between current row and 1 following: The current row and the subsequent row
rows between 1 preceding and current row: The current row and the preceding row
rows between 1 preceding and 1 following: From the preceding row to the subsequent row (a total of three rows)
rows between current row and unbounded following: The current row and all subsequent rows
rows between unbounded preceding and current row: The current row and all preceding rows
General Aggregate Functions
All general aggregate functions are supported, such as sum() and avg(), can be used to calculate the statistics of each row of data in window frames.
Ranking Functions
Ranking functions cannot use window frames.
Function
Description
rank()
Returns the rank of each row in a window partition. Rows that have the same field value are assigned the same rank, and therefore ranks may not be consecutive. For example, if two rows have the same rank of 1, the rank of the next row is 3.
dense_rank()
Similar to rank(). The difference is that the ranks in this function are consecutive. For example, if two rows have the same rank of 1, the rank of the next row is 2.
cume_dist()
Returns the cumulative distribution of each value in a window partition, that is, the proportions of rows whose field values are less than or equal to the current field value to the total number of rows in the window partition.
ntile(n)
Divides the rows for a window partition into n groups. If the number of rows in the partition is not divided evenly into n groups, the remaining values are distributed one per group, starting with the first group. For example, if there are 6 rows of data, and they need to be divided into 4 groups, the numbers of each row of data are: 1, 1, 2, 2, 3, 4.
percent_rank()
Calculates the percentage ranking of each row in a window partition. The calculation formula is: (r - 1) / (n - 1), where r is the rank value obtained via rank() and n is the total number of rows in the window partition.
row_number()
Calculates the rank of each row (after ranking based on ranking rules) in a window partition. The ranks are unique and start from 1.
Value Functions
Function
Description
first_value(key)
Returns the first value of key of the window partition.
last_value(key)
Returns the last value of key of the window partition.
nth_value(key, offset)
Returns the value of key in the row at the specified offset of the window partition. Offsets start from 1 and cannot be 0 or negative. If offset is null or exceeds the number of rows in the window partition, null is returned.
lead(key[, offset[, default_value]])
Returns the value of key in the row that is at the specified offset after the current row of the window partition. Offsets start from 0, indicating the current row. offset is 1 by default. If offset is null, null is returned. If the offset row exceeds the window partition, default_value is returned. If default_value is not specified, null is returned.<br />When using this function, you must specify the ranking rule (ORDER BY) within the window partition and cannot use window frames.
lag(key[, offset[, default_value]])
Similar to lead(key[, offset[, default_value]]). The only difference is that this function returns the value at offset rows before the current row.
Example
Example 1. Query the 5 slowest requests and their IDs of each API in the last hour
Select the last hour as the time range and run the following query and analysis statement, where action indicates the API name, timeCost indicates the API response time, and seqId indicates the request ID.
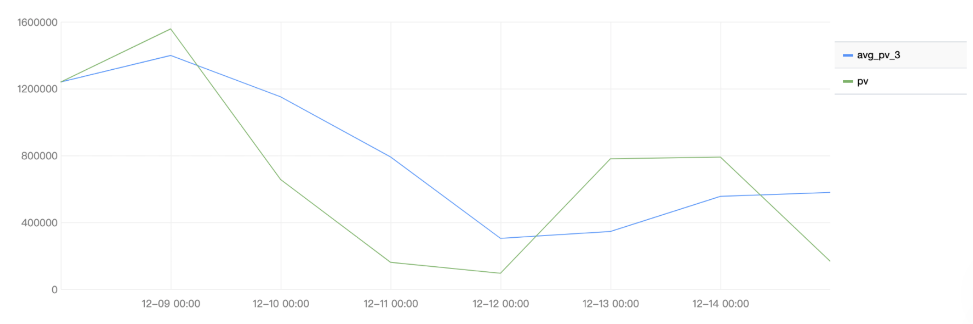
Example 2. Query the 3-day moving average trend of the application throughput
Select the last 7 days as the query and analysis time range and run the following query and analysis statement, where pv indicates the daily application throughput and avg_pv_3 indicates the application throughput after 3-day moving average.
Query and analysis statement
* |select avg(pv) over(order by analytic_time rows between 2 preceding and current row) as avg_pv_3,pv,analytic_time from (select histogram( cast(__TIMESTAMP__ as timestamp),interval 1 day) as analytic_time, count(*) as pv group by analytic_time order by analytic_time)

 Yes
Yes
 No
No
Was this page helpful?