Suggestions and Principles for Cluster Specification Adjustment
Download
Focus Mode
Font Size
Last updated: 2021-07-13 17:14:55
As your business develops, the data volume and access traffic of your ES cluster grow. When the cluster size and configuration become insufficient to satisfy your actual business needs, you can expand your ES cluster as needed.
Configuration Adjustment Suggestion Overview
If your business hits a bottleneck, you need to consider which configuration adjustment method should be used. You can choose a method based on the table below and your actual business needs (the rolling mode and blue-green mode mentioned in the table will be detailed later in this document):
Configuration Adjustment Method
Use Case
How It Works
Characteristics
Expanding disk capacity
The computing resources are sufficient, but the disk storage space is insufficient.
The configuration is directly adjusted to increase the capacity of disks mounted to the cluster nodes one by one (the blue-green mode is used for encrypted cloud disks).
The cluster can be smoothly expanded without interrupting your business, and the expansion is quick (about 30 seconds for each node).
Increasing disk quantity
The computing resources are sufficient, but the disk storage space, IOPS, or throughput is insufficient.
You can choose the rolling mode or the blue-green mode.
The rolling mode is quicker, while the blue-green mode is slower but has no impact on the business in the production environment.
Adding more nodes
The node specification is high, but the overall computing resources of the cluster are insufficient.
The configuration is directly adjusted to add more nodes in the same specification as that of existing ones to the cluster.
The cluster can be smoothly expanded without interrupting your business, and the expansion is quick, which is not subject to the number of nodes and generally takes 5–10 minutes.
Upgrading node specification
The node specification is low, and the overall computing resources of the cluster are insufficient.
You can choose the rolling mode or the blue-green mode.
The rolling mode is quicker, while the blue-green mode is slower but has no impact on the business in the production environment.
Note:
The table above focuses on the mappings between different scenarios and configuration adjustment methods. The description of how it works is applicable to the scenarios where only the corresponding >configuration item is adjusted. If multiple configuration items (such as node specification, disk capacity, and disk quantity) are adjusted at the same time, the actual adjustment method may be different.
An expansion operation can adjust either vertical (node specification, disk capacity, and disk quantity) or horizontal (node quantity) configuration items at a time. You cannot adjust vertical and horizontal >configuration items at the same time.
Basic Configuration Adjustment Concepts
Common cluster configuration adjustment modes include direct adjustment mode, rolling mode, blue-green mode, etc. as detailed below:
Direct adjustment
As direct adjustment does not involve heavy change operations on the cluster (such as restart or data replication), it generally has no impact on the business in the production environment and is relatively quick. For example, both horizontally adding more nodes to the cluster or vertically expanding the disk capacity are direct adjustments.
Rolling mode
In this mode, nodes in the cluster are restarted one by one on a rolling basis, and the system service is not interrupted, but the access performance in the production environment may be affected.
Advantage: as no data migration is required, the expansion duration is not subject to the cluster data volume, and the configuration adjustment can be completed quickly. Therefore, this mode is suitable for scenarios where your cluster hits a bottleneck and you want to quickly complete the expansion and configuration adjustment.
Disadvantage: as all nodes in the cluster need to be restarted on a rolling basis, if the cluster has no replicas, the data may be lost. Moreover, there are nodes consecutively leaving and joining the cluster during the configuration adjustment, which may compromise the cluster performance. Therefore, we recommend you not use this scheme during peak hours of your business.
Blue-Green mode
The same number of new nodes as the existing nodes are added to the original cluster with no cluster restart required (the new nodes need to be configured as the desired type, and data on the existing nodes needs to be replicated to the new nodes). After the configuration, you can seamlessly switch to the new nodes and remove the legacy ones. The node IPs will change after the configuration adjustment is completed.
Advantage: the business does not need to be stopped during the configuration adjustment, and the expansion is very smooth; therefore, this mode is applicable to scenarios that have high requirements for cluster availability.
Disadvantage: as data replication is involved, the configuration adjustment duration is directly proportional to the cluster data volume and can range from several minutes to several days or even longer.
Principles of Main Configuration Adjustment Scenarios
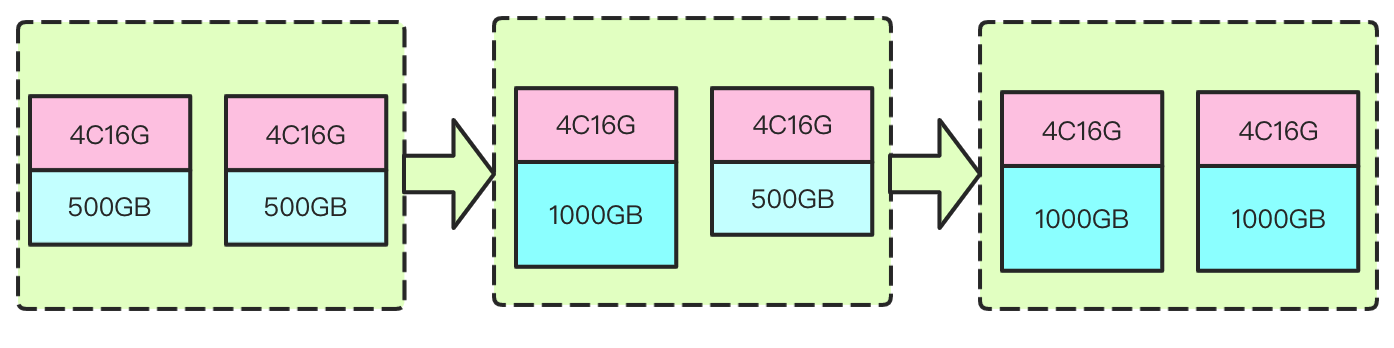
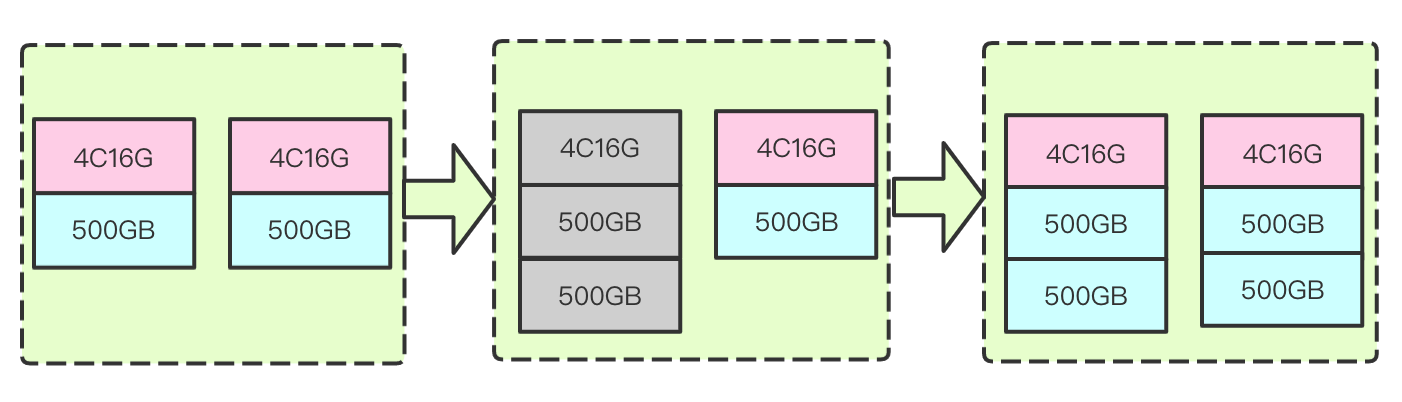
1. Expanding disk capacity
It refers to increasing the disk capacity of each node so as to increase the overall storage capacity of the cluster without changing the computing resource configuration.
How it works: during disk capacity expansion, vertical expansion is performed on disks mounted to each data node in the cluster one by one to increase the overall disk storage capacity of the cluster; for example, the original disk capacity is 1,000 GB, and you can use this expansion method to increase the capacity to 5,000 GB. This method does not require node restart; therefore, the use of the cluster by your business will not be affected. As data nodes are expanded on a rolling basis, the more the nodes in the cluster, the longer the scaling process. If it takes about 10 seconds to expand a node, then it will take about 2 minutes to expand a cluster with 10 data nodes. The process and principle are as shown below:
Use cases: it is suitable for scenarios where the computing resources are sufficient, but the disk capacity is insufficient; for example, the CPU load and memory utilization of your cluster are relatively low, but the average disk utilization is high, and all data is important, which cannot be deleted to release disk space. In this case, you can expand the cluster by only expanding the disk capacity.
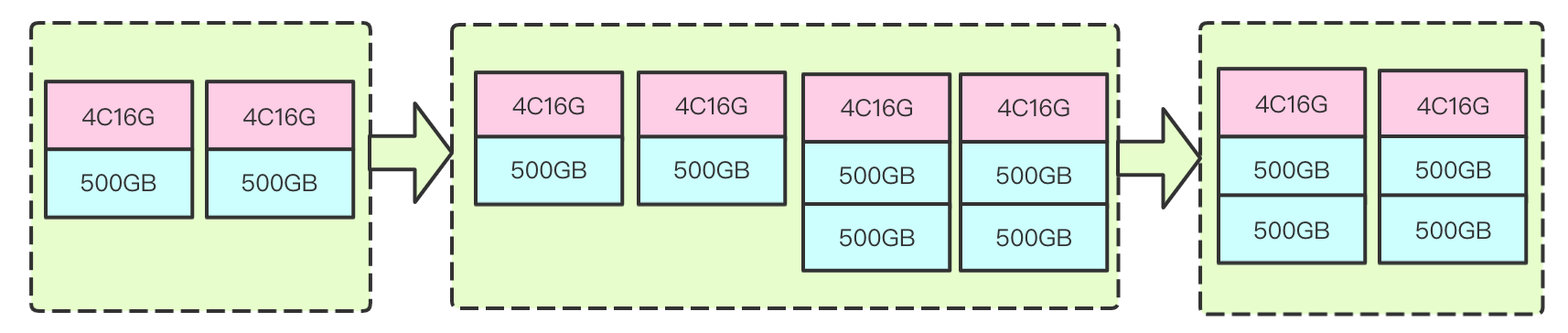
2. Increasing disk quantity
It refers to increasing the disk quantity of each node so as to increase the overall storage capacity, IOPS, and throughput of the cluster without changing the computing resource configuration.
How it works: the number of cloud disks mounted to a node is increased; for example, only one disk is mounted to each data node in the original cluster, but after this process is completed, multiple disks can be mounted to each data node. Currently, the blue-green mode and rolling mode are supported.
Blue-green mode:
This mode is to add the same number of new nodes as existing nodes to the cluster with multiple cloud disks mounted to each new node, migrate data in the existing nodes to the new nodes, and then remove the existing nodes from the cluster. Its process and principle are as shown below:
Advantage: the entire cluster expansion process is smooth, which is applicable to scenarios with high requirements for business stability and availability.
Disadvantage: the configuration adjustment duration is subject to the cluster data volume. The higher the volume, the longer the expansion duration.
Rolling mode:
This mode is to directly add more disks to the original nodes so as to mount multiple disks. As the configuration of the cluster nodes needs to be modified, they need to be restarted for the change to take effect. To minimize the impact on the cluster performance, rolling restart is used, that is, disk addition and restart are performed on only one node at a time. Only after a node joins the cluster again will the next node be processed. The process and principle are as shown below (gray indicates the restarting status):
Advantage: as the rolling restart expansion mode involves no data migration, the expansion duration is not subject to the cluster data volume, and the configuration adjustment can be completed quickly. Therefore, this mode is suitable for scenarios where your cluster hits a bottleneck and you want to quickly complete the expansion and configuration adjustment.
Disadvantage: as all nodes in the cluster need to be restarted on a rolling basis in this mode, if the cluster has no replicas, the data may be lost. Moreover, there are nodes consecutively leaving and joining the cluster during the configuration adjustment, which may compromise the cluster performance. Therefore, we recommend you not use this scheme during peak hours of your business.
In addition, the ES cluster does not rebalance the shards on individual nodes, that is, ES does not balance the shard assignment between different data paths; therefore, if you choose the rolling restart mode to directly add disks to existing nodes, ES will assign shards to the disk with most available storage space first, which cannot take advantage of multiple disks in a short time and may even result in performance problems such as excessive I/O load. This problem cannot be alleviated until the number of new disks reaches the number of existing ones. Moreover, when the utilization of a single disk in the existing cluster exceeds the threshold configured in ES, the entire node will also reach the threshold. In this case, even if there is available space on the new disks and you add more disks to the node, the problem will still persist. To solve it, you can migrate the data to other nodes or delete some data.
Comparison between different disk quantity increasing schemes:
Disk Quantity Increasing Scheme
Advantage
Disadvantage
Blue-green mode
The configuration adjustment is smooth and imperceptible to the business
The process duration is uncontrollable
The node IPs change
Rolling mode
The configuration adjustment duration is short and not subject to the cluster data volume
The node IPs do not change
Nodes are restarted on a rolling basis, affecting the business continuity
You cannot take advantage of multiple disks in a short time
Data in indices with no replicas may get lost
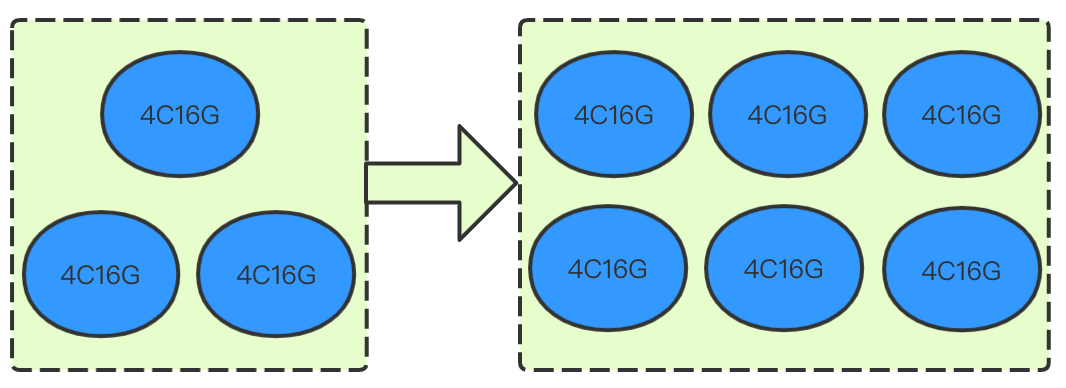
3. Adding more nodes
It is suitable for scenarios where the cluster computing resources hit the bottleneck; for example, the CPU load is continuously high, or the memory utilization stays high and repeatedly triggers memory issues or even OOM. In this case, you can expand the cluster nodes to improve the cluster's overall performance.
How it works: adding cluster nodes is an expansion method in which more nodes are added to the cluster without changing the cluster node model configuration. Its process and principle are as shown below:
The major advantage of this expansion method is smoothness, so that your business will not be interrupted during the expansion. As no data migration between new and existing nodes is involved, the expansion will not be affected by the node quantity and can be completed generally in 5–10 minutes.
Use cases: the node configuration is already very high, but you want to further improve the cluster's overall read/write performance, and your business requires high cluster stability during the expansion. In this case, you can expand the cluster by adding nodes to it.
4. Upgrading node specification
It is suitable for scenarios where the cluster computing resources hit the bottleneck; for example, the CPU load is continuously high, or the memory utilization stays high and repeatedly triggers memory issues or even OOM. In this case, you can upgrade the specification of the cluster nodes to improve the cluster's overall performance.
How it works: it refers to upgrading the computing resource configuration of data nodes in the cluster without changing the number of nodes, such as upgrading the data node configuration from 4-core 16 GB MEM to 8-core 16 GB MEM. Currently, blue-green and rolling configuration adjustment modes are supported.
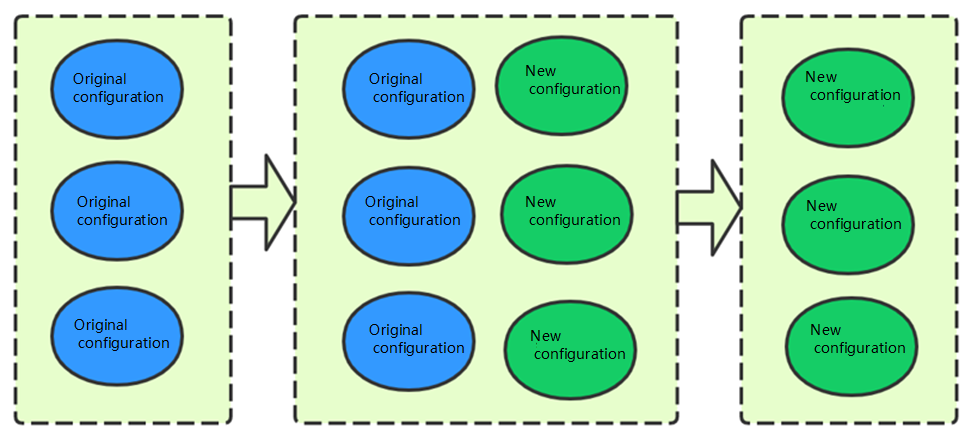
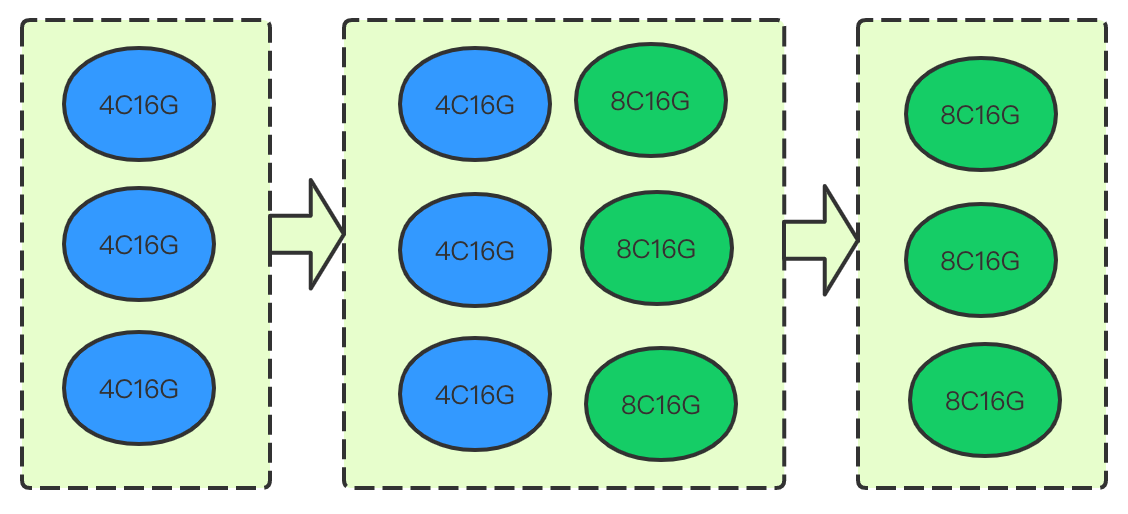
Blue-Green mode
This mode is to first add the same number of new nodes as existing nodes in a higher specification in the cluster, migrate data in the existing nodes to the new nodes, and then remove the existing nodes. Its process and principle are as shown below:
The major advantage of this expansion method is smoothness, so that the cluster use and availability will not be affected during the expansion. However, as the data in existing nodes needs to be migrated to the new nodes, the migration duration is greatly subject to the data volume. Therefore, if the cluster data volume is over 1 TB and you want to complete expansion as soon as possible, you can choose the rolling mode or set the following attributes in Kibana to speed up the data migration:
PUT _cluster/settings {"persistent":{"cluster.routing.allocation.node_concurrent_recoveries":"8", "indices.recovery.max_bytes_per_sec":"80mb"}}
Here:
The cluster.routing.allocation.node_concurrent_recoveries attribute specifies the number of shards concurrently restored on each node in the cluster, which is 2 by default and cannot exceed 50. You can determine the specific value by multiplying the number of CPU cores in an existing data node by 4; for example, you are recommended to set this attribute to 16 if the existing data node specification is 4-core 16 GB MEM or to 50 if the specification is 16-core 64 GB MEM. If you find that the cluster stability is compromised after you increase the attribute value, you can appropriately set a smaller value.
The indices.recovery.max_bytes_per_sec attribute specifies the maximum bandwidth for data transfer between nodes, which is 40mb by default. The bandwidth limit should not be too high; otherwise, the cluster stability may be compromised. You can adjust the limit by an increment of 5mb while checking the cluster stability so as to determine an appropriate value.
Use cases: the node configuration is relatively low, you want to further improve the cluster's overall read/write performance, your business requires high cluster stability during the expansion, and you have ample time for the expansion. In this case, you can expand the cluster through data migration.
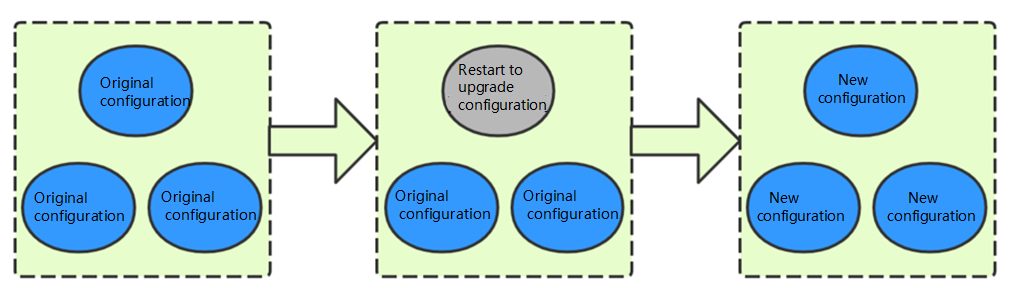
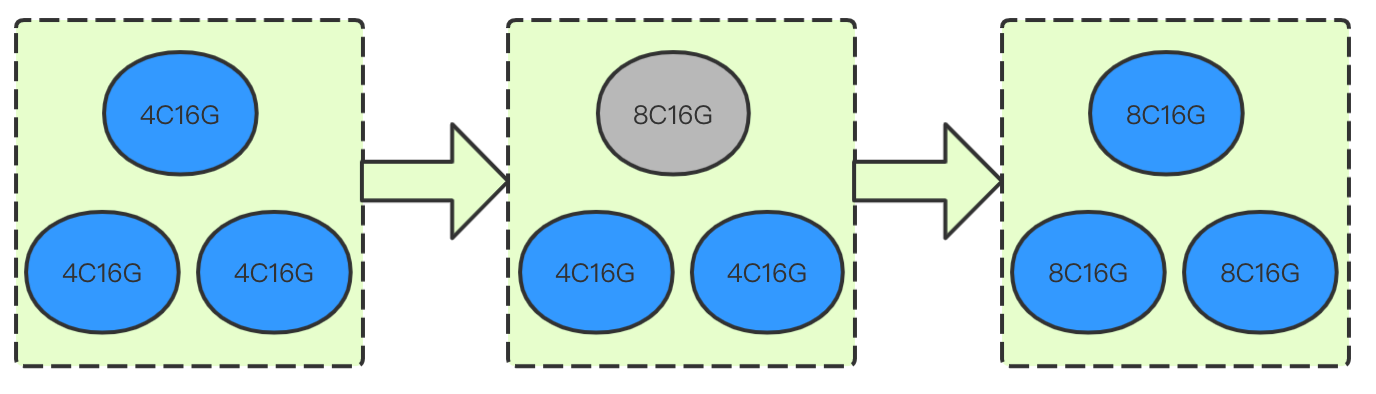
Rolling mode
This mode is to upgrade the node specification of the cluster by restarting the nodes one by one. As it does not involve data migration, the specification adjustment duration is not subject to the cluster data volume but directly proportional to the number of nodes. It takes around 3–5 minutes for each node. The process and principle are as shown below (gray indicates the restarting status):
Use cases: it is suitable for scenarios where the cluster node configuration is low and hits a performance bottleneck, the requirement for cluster stability is low, and you want to quickly improve the cluster performance. As the nodes are restarted on a rolling basis during the configuration adjustment, there are nodes consecutively leaving and joining the cluster, and we recommend you use this mode during off-peak hours of your business.
Comparison between different node specification upgrade schemes:
Node Specification Upgrade Scheme
Advantage
Disadvantage
Blue-green mode
The configuration adjustment is smooth and imperceptible to the business
The process duration is uncontrollable
The node IPs change
Rolling mode
The configuration adjustment duration is short and not subject to the cluster data volume
The node IPs do not change
Nodes are restarted on a rolling basis, affecting the business continuity