付録
Download
フォーカスモード
フォントサイズ
マジック構文
Magic 構文は Jupyter Notebook の機能の1つで、特定のコマンドを使用して特別な操作を実行できます。通常、% または %% で始まります。Magic コマンドは一般的なタスクを簡素化し、作業効率を向上させるために使用できます。
Jupyter Notebook ネイティブマジックコマンド
行マジックコマンド(Line Magics)は通常 % で始まり、現在の行に作用します。
例を挙げて説明
マジックコマンド | 意味説明 | 使用例 |
%run | 指定されたPythonスクリプトまたはNotebookファイルを実行 |
|
%pip | 指定されたPythonパッケージをインストール |
|
セルマジックコマンド(Cell Magics)は通常%%で始まり、セル全体に作用します。
例を挙げて説明
マジックコマンド | 意味説明 | 使用例 |
%%python | 現在のセルをPython構文で実行します(通常は不要で、デフォルトはPythonです) |
|
%%markdown | セル内でMarkdownテキストをレンダリングします |
|
WeData Notebook 特殊マジックコマンド
多言語切り替え
デフォルトでは、NotebookはPython構文を使用してコードを記述します。現在のセルの構文を切り替えたい場合は、セルの前に%%<言語>を追加できます。
以下の magic コードを実行するには、まず以下の初期化コマンドを実行する必要があります:
%load_ext dlcmagic.kyuubikernel.magics.dlcenginemagics%load_ext dlcmagic.pythonkernel.magics
例を挙げて説明
マジックコマンド | 意味説明 | 使用例 |
%%py | 現在のセルをPySpark構文で実行します。使用前に以下の初期化コマンドを実行する必要があります |
|
%%scala | 現在のセルをScala構文で実行 |
|
%%sql | 現在のセルをSpark SQL構文で実行 |
|
注意:
上記のWeData Notebookの特殊魔法コマンドは、DLCエンジンの機械学習リソースグループに接続して使用する場合にのみ適用されます。
DLC Utilities(dlcutils)
dlcutilsは、WeDataがDLCエンジンに基づいて提供するユーティリティライブラリであり、主にNotebook環境でのさまざまな操作を簡素化するために使用されます。データ処理、パラメータの受け渡し、環境設定などの関連タスクをユーザーが実行するのに役立ちます。
Data utility(dlcutils.notebook)
関数名 | 意味説明 | 使用例 |
summarize(df: Object): void | DataFrameの統計指標を計算および表示し、データ構造を理解しやすくします。 Pythonコード、PySparkコードに適用されます。 |
|
Notebook utility(dlcutils.notebook)
関数名 | 意味説明 | 使用例 |
exit(value: String): void | 現在のnotebookを終了し、指定された戻り値を出力します。この方法でnotebookのパラメータを下流のタスクに渡すことができます。 |
|
run(path: String, timeoutSeconds: int, arguments: Map): String | ノートブックファイルを実行する path:notebookファイルのパスを指定します timeoutSeconds:タイムアウト時間 arguments:変数 |
|
Parameters utility(dlcutils.params)
関数名 | 意味説明 | 使用例 |
text(name: String, defaultValue: String, label: String): void | 変数の値を設定 |
|
get(name: String): String | 指定変数を取得 |
|
remove(name: String): void | 指定変数をクリア |
|
removeAll(): void | 現在のコンテキストに設定された変数をクリア |
|
注意:
上記のdlcutils関数は、DLCエンジンの機械学習リソースグループに接続して使用する場合にのみ適用されます。
MLFlow関数
MLFlowはオープンソースの機械学習プラットフォームで、データサイエンスライフサイクル全体(実験管理、モデルバージョン管理、モデルデプロイ、モデルモニタリングなど)を包括的にサポートしています。
テンセントクラウド WeData は MLFlow に基づいて機械学習実験管理とモデル管理機能を提供しています。Notebook ワークスペースで MLFlow サービスを有効にすると、実験中に MLFlow の関連関数を呼び出して各実験のパラメータ、指標、結果を記録し、WeData 機械学習モジュール > 実験管理とモデル管理で確認できるようになり、実験の追跡と再現性を実現します。
一般的なMLFlow関数には以下が含まれます:
MLFlow関数 | 関数名 | 関数の機能と使用方法 |
実験管理 | mlflow.create_experiment(name) | 新しい実験を作成します。 実験名の一意性を保証する必要があります。実験名が既に存在する場合、create_experimentは例外を発生させます。 |
| mlflow.set_experiment(name) | 現在の実験を設定します。 既存の実験名に直接使用でき、後続の実行でパラメータとメトリクスを記録することができます。 指定された実験が存在しない場合、新しい実験が自動的に作成されます。 |
| mlflow.start_run() | 新しい実行を開始します。 現在の実行コンテキストを表すRunオブジェクトを返します。 start_run() は通常、with ステートメントと一緒に使用され、実行終了時に自動的に end_run() が呼び出されるようにします。 |
パラメータと指標を記録する | mlflow.log_param(key, value) | パラメータとその値を記録する key (str): パラメータの名前。 value (str, int, float): パラメータの値。文字列、整数、または浮動小数点数を指定できます。 |
| mlflow.log_metric(key, value, step=None) | 指標とその値を記録する。 |
| mlflow.log_artifact(local_path, artifact_path=None) | ローカルファイルまたはディレクトリ(モデルの設定ファイル、データファイル、結果ファイルなど)を記録する。 local_path:記録するローカルファイルまたはディレクトリのパス; artifact_path:MLflowサーバー上でこのファイルまたはディレクトリを保存するパス。 |
モデル管理 | mlflow.sklearn.log_model(model, artifact_path) | Scikit-learnモデルを記録します。 |
| mlflow.pyfunc.log_model(artifact_path, python_model) | カスタムPythonモデルを記録します。 |
| mlflow.register_model(model_uri, name) | モデルをモデルレジストリに登録します。モデルレジストリはMLflowが提供するモデル管理とバージョン管理機能で、モデルの共有、デプロイ、管理を容易にします。 |
モデルデプロイ | mlflow.pyfunc.serve(model_uri) | モデルをREST APIサービスとしてデプロイします。登録されたMLflowモデルの予測サービスを提供するために、ローカルでHTTPサーバーを起動します。サーバー起動後、HTTP Postリクエストでデータを送信して予測を行うことができます。 model_uri:登録済みモデルを指すURIで、モデルレジストリ内のURIまたは記録済みモデルのパスを指定できます。 |
Notebookパラメータの使用例
Notebookでプロジェクトパラメータを使用する
1. プロジェクト管理 > パラメータ設定画面に移動し、追加をクリックして、プロジェクトパラメータの新規作成を完了します。
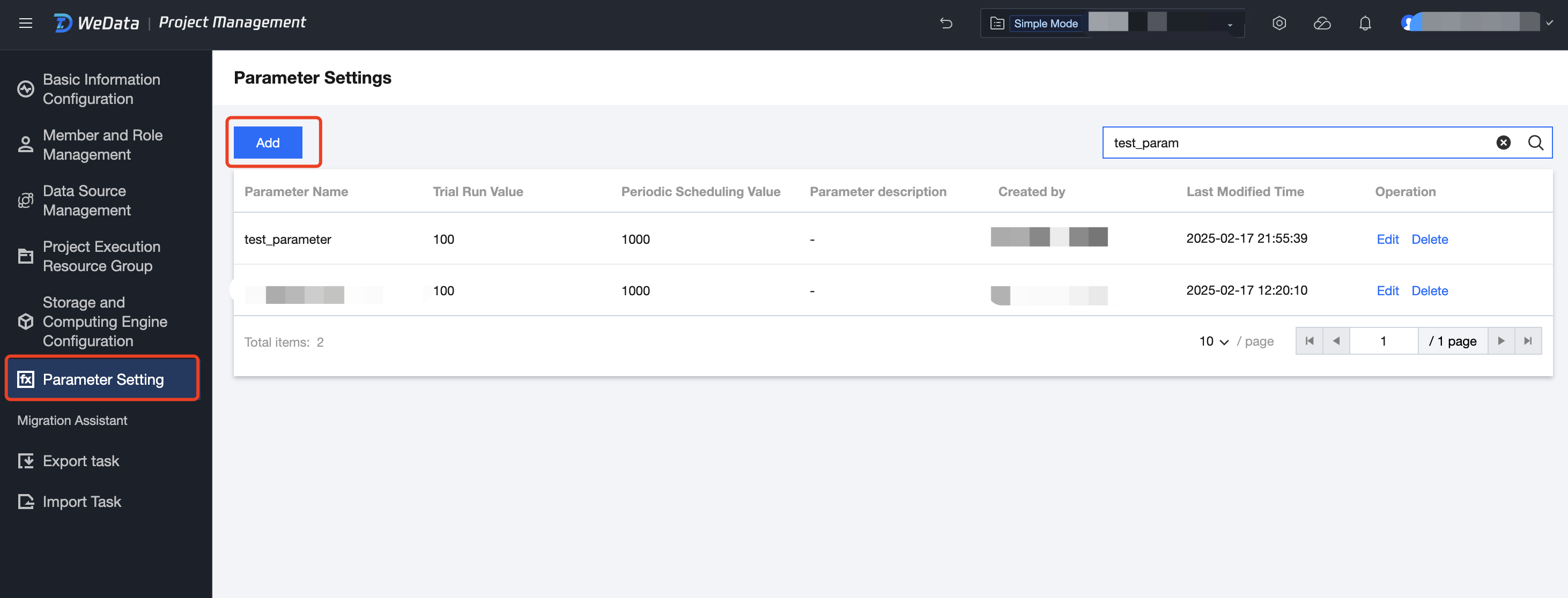
2. プロジェクト管理のパラメータで既にパラメータが定義されている場合、例えばパラメータ名 test_parameter で値が100の場合、notebook で直接プロジェクトパラメータを試用できます。
# print project parametersprint(dlcutils.params.get("test_parameter"))# output 100
Notebookでワークフローパラメータまたはタスクパラメータを使用する
NotebookスペースでNotebookファイルをデバッグ実行する場合、Notebookはまだタスクやワークフローに関連付けられていないため、テスト中にデフォルト値を設定できます。Notebookの定期スケジュール時には、ワークフローとタスクで設定された値を使用します。
ワークフローパラメータはワークフローの共通設定で構成できます。
タスクパラメータはタスクのタスク属性で構成できます。
例えば、タスクにはタスクパラメータtask_test_paramが構成され、タスクのワークフローにはworkflow_test_paramが構成されています。
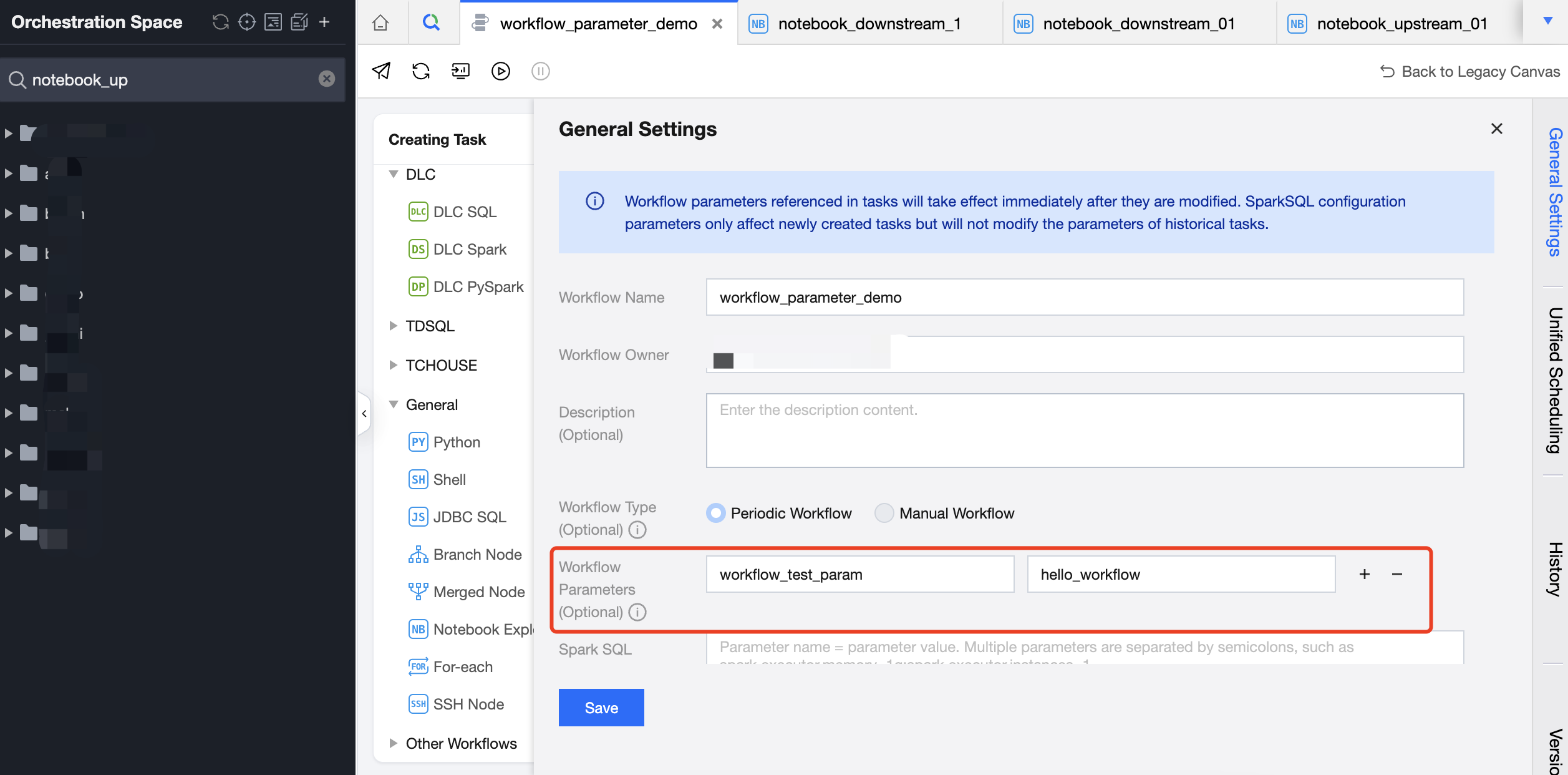
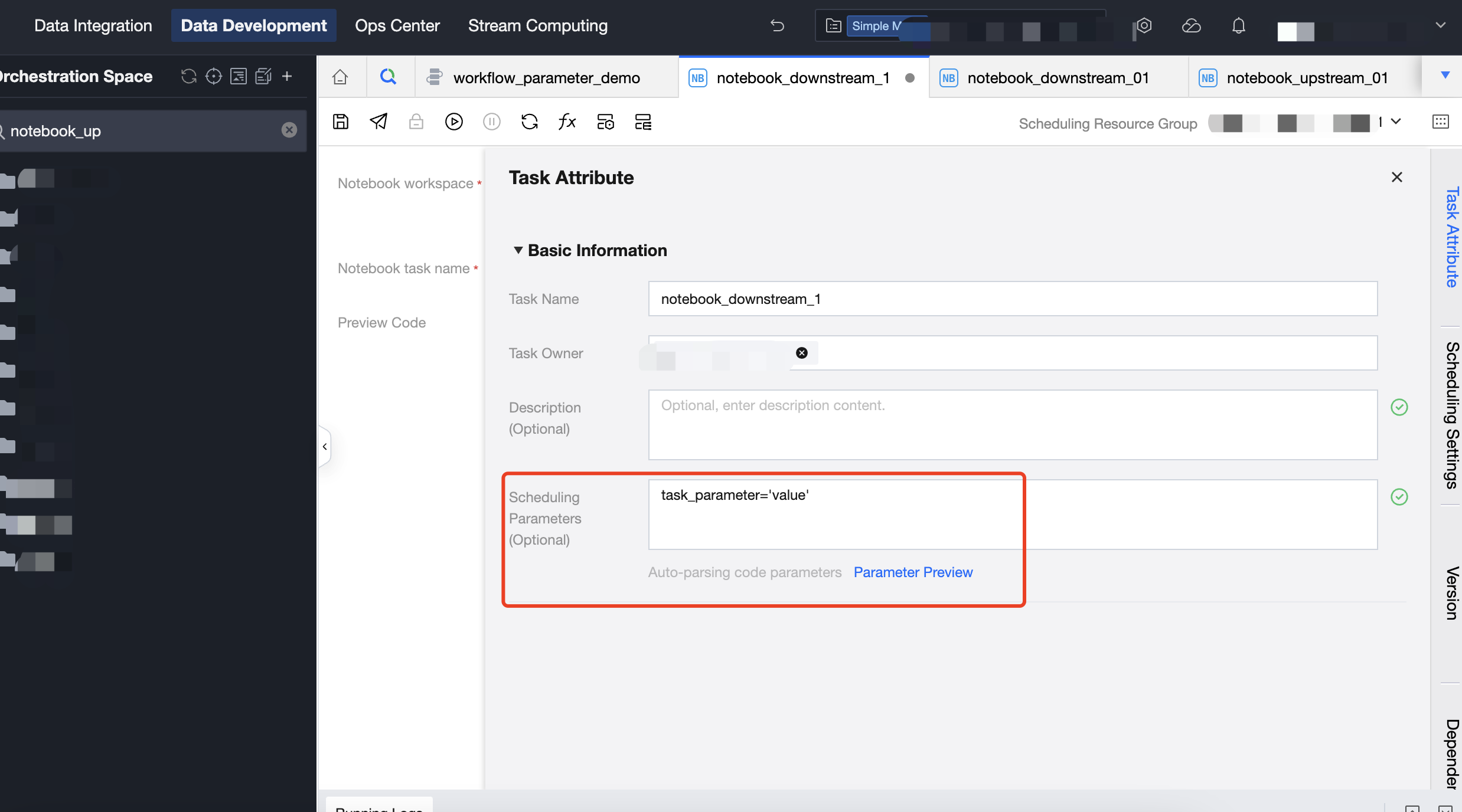
# get task_test_param value# When testing and running in the notebook space,# default values need to be set because the notebook file has not yet been associated with a task.try:task_test_param_value = dlcutils.params.get("task_test_param")if not task_test_param_value: # 取得した値が空文字列の場合task_test_param_value = 'task_default_value'except Exception: # パラメータを完全に取得できない場合task_test_param_value = 'task_default_value'print(f"Using toy value: {task_test_param_value}")
# get workflow_test_param value# When testing and running in the notebook space,# default values need to be set because the notebook file has not yet been associated with a workflow.try:workflow_test_param_value = dlcutils.params.get("workflow_test_param")if not workflow_test_param_value: # 取得した値が空文字列の場合workflow_test_param_value = 'workflow_default_value'except Exception: # パラメータを完全に取得できない場合workflow_test_param_value = 'workflow_default_value'print(f"Using toy value: {workflow_test_param_value}")
notebook間のパラメータ受け渡し
1. Notebookスペースで、parameter_test_up.ipynbとparameter_test_down.ipynbの2つのNotebookファイルを作成し、ファイルの内容は次のとおりです:
parameter_test_up.ipynb
# Exit the notebook and output parametersdlcutils.notebook.exit('this is output parameter values')
parameter_test_down.ipynb
# get task_input_param value# When testing and running in the notebook space,# default values need to be set because the notebook file has not yet been associated with a task.try:task_input_param = dlcutils.params.get("task_input_param")if not task_input_param: # 取得した値が空文字列の場合task_input_param = 'task_input_default_value'except Exception: # パラメータを完全に取得できない場合task_input_param = 'task_input_default_value'print(f"Using toy value: {task_input_param}")
2. また、オーケストレーションスペースで2つのタスク「notebook_upstream_01」と「notebook_downstream_01」を作成し、それぞれ上記の2つのノートブックファイルを選択します。
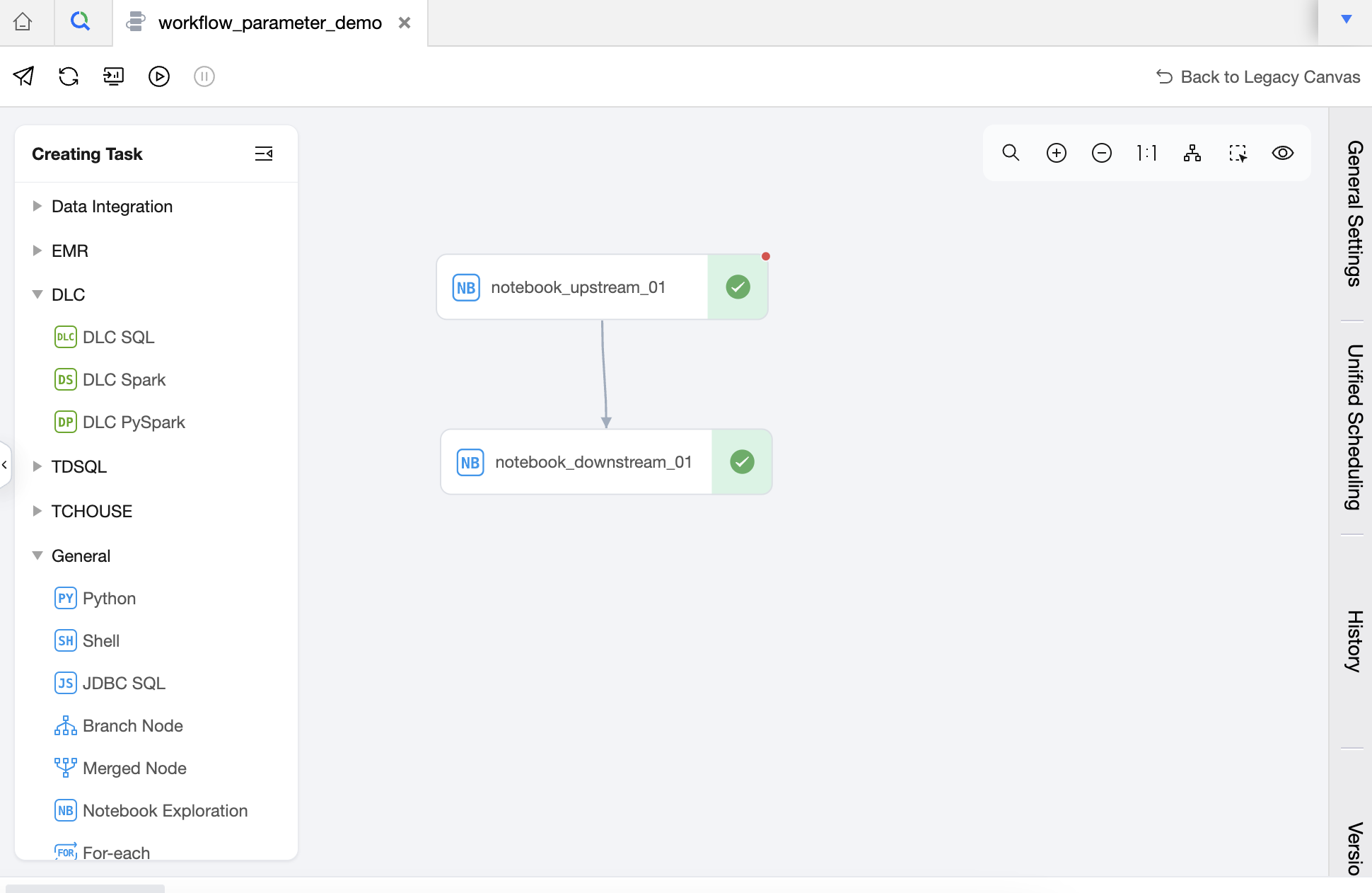
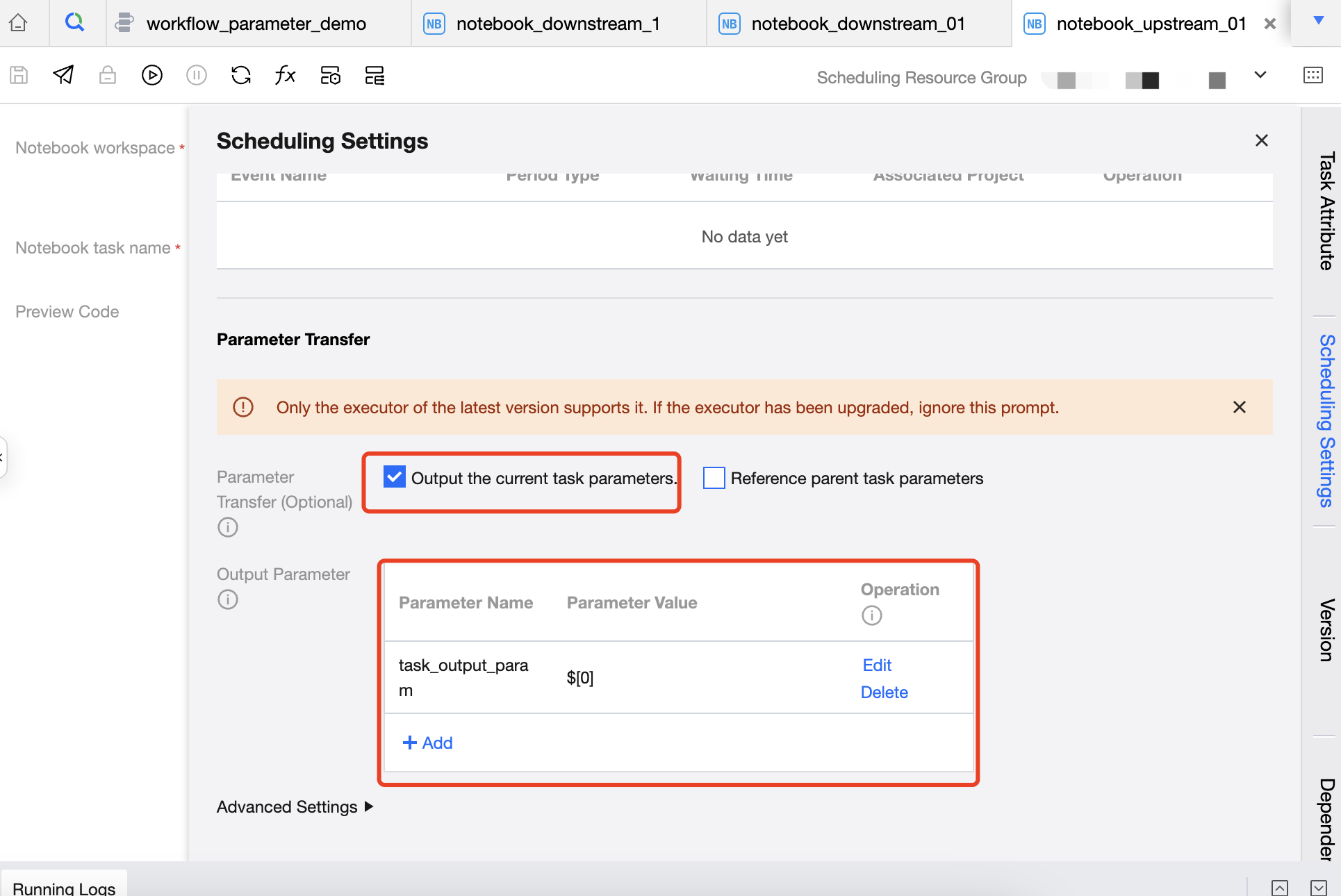
3. タスク notebook_upstream_01 のスケジュール設定で、現在のタスクパラメータ task_output_param を$[0]に設定します。
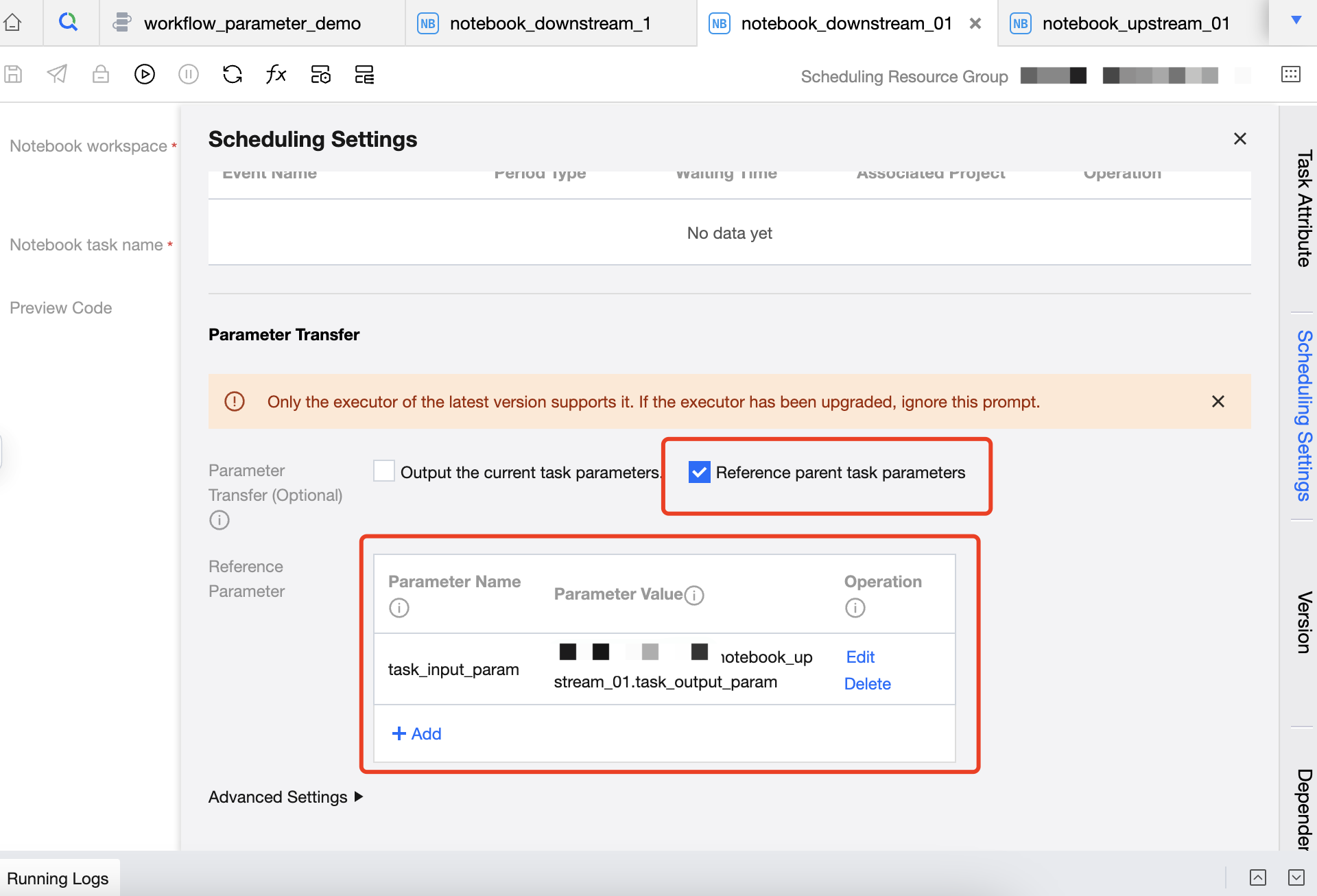
4. タスク notebook_downstream_01 のスケジュール設定で、現在のタスクパラメータ task_output_param を$[0]に設定します。
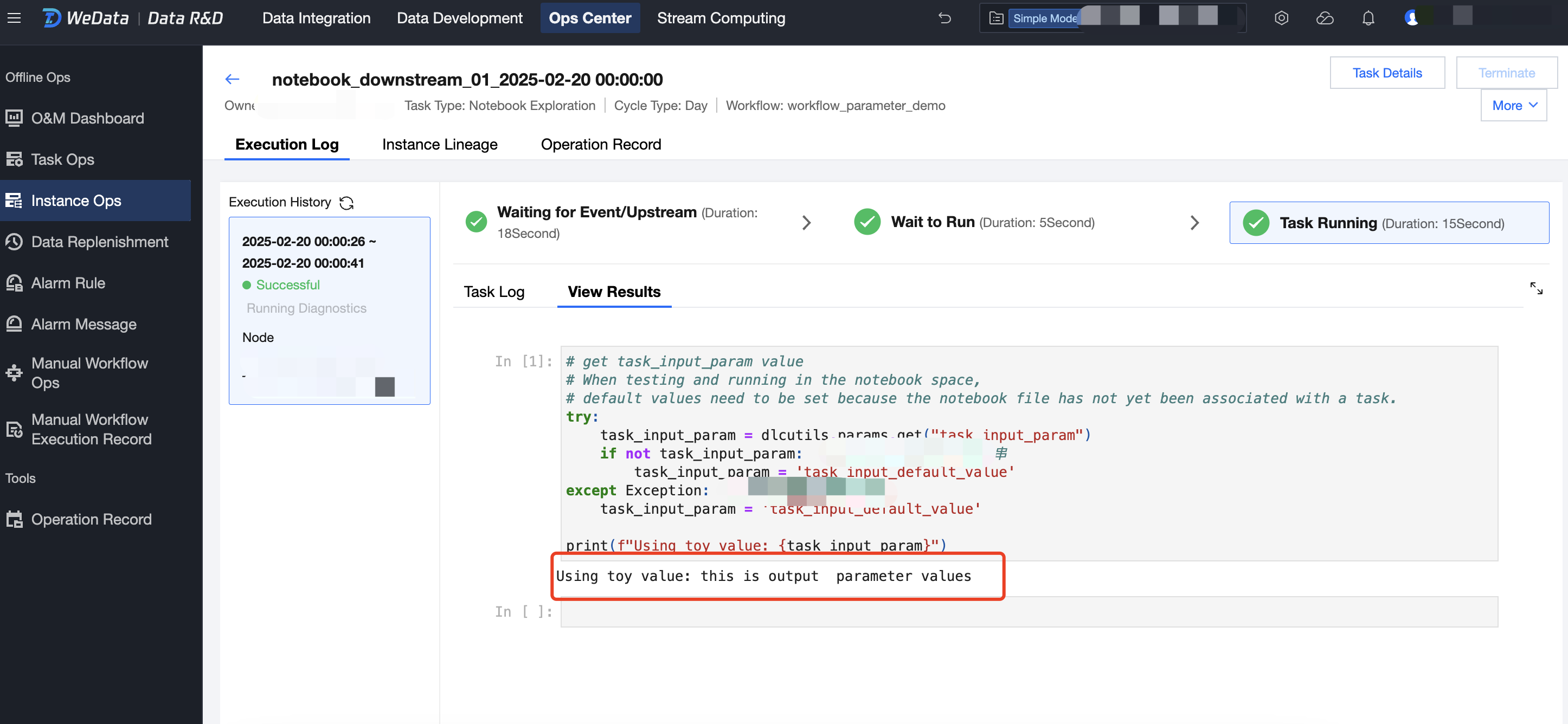
5. 最後に、ワークフローのデバッグ実行またはスケジュール実行で、notebook_downstream_01 の出力が「this is output parameter values」であることを確認できます。
フィードバック