DLC + Wedata 分散型オフライン推論実践チュートリアル
Download
フォーカスモード
フォントサイズ
本稿ではアヤメのデータセットを例に、DLCとWedataの連携により、SparkMLlibフレームワークを活用した分散型オフライン推論を実現します。
説明:
現在、DLCの機械学習リソースグループとWeData Notebook探索はホワイトリスト機能となっており、ご利用の場合はチケットを提出してDLCとWeDataチームに機械学習リソースグループ、Notebook、MLFlowサービスの開通を依頼してください。
背景紹介
データレイクコンピューティングDLCは、機械学習リソースグループ内のSparkMLlibフレームワークを使用した分散型オフライン推論をサポートし、大規模データ(TB/PBレベル)シナリオでのモデルトレーニングをユーザーが実現するのを支援します。
オフライン推論(Batch Inference):モデルがバッチごとに分割された静的データに対して一度にバッチ予測を行う計算プロセスを指します。
分散型オフライン推論:オフライン推論の一種の実現方法であり、分散計算フレームワーク(Sparkなど)を使用してバッチ予測タスクを複数のマシンに分散して並列実行します。
事前準備
1. アカウントと製品の開通:メインアカウントを通じてDLCアカウント、Wedataアカウントおよび関連機能を開通します。
2. データアクセスポリシーの設定:ユーザーはアクセス管理(CAM)でデータアクセス権限のポリシー設定を行います。
DLCでリソースを設定し、データセットを準備します
手順1:計算リソースを購入し、リソースグループを作成します
準備作業が完了したら、データレイクコンピューティングDLCでコンピューティングリソースを購入し、機械学習をビジネスシナリオとするSparkMLlibを基盤としたリソースグループを作成します。
1. コンピューティングリソースの購入:
データレイクコンピューティングDLC > 標準エンジンページに進み、リソース作成をクリックします。このシナリオで購入する必要があるエンジンバージョンは標準エンジンで、エンジンタイプはSpark、カーネルバージョンはStandard-S 1.1を選択します。
説明:
アカウントの購入には財務権限またはプライマリアカウントが必要です。
課金モードは、ビジネスシナリオに応じて選択できます。
クラスタ仕様は64CU以上を選択することをお勧めします。
購入が成功した後、初回起動には数分の待ち時間があります。長時間起動が完了しない場合は、チケットを提出してください。
2. リソースグループを作成:
標準エンジン ページに戻り、このエンジンで機械学習をビジネスシナリオとし、SparkMLlibフレームワークに基づくリソースグループを作成し、分散型オフライン推論を実現する必要があります。リソースグループの作成手順については、機械学習リソースグループの作成を参照してください。ビジネスシナリオで機械学習を選択し、フレームワークタイプでSpark MLlibを選択し、組み込みイメージでStandard-S1.1を選択することに注意してください。
ステップ2:COS内のデータセットをDLCにアップロードする
データセットがCOSに保存されている場合、外部テーブルを作成してDLCにアップロードすることで、Wedataでそのデータセットを呼び出すことができます。操作手順の詳細については、機械学習データセットをCOSにアップロードを参照してください。
Wedataでオフライン推論を行う
リソースグループとデータセットの作成が完了したら、Wedataに移動してNotebookとMLFlowを使用してオフライン推論を行います。
ステップ1:WeDataプロジェクトを作成し、DLCエンジンを関連付ける
1. プロジェクトを作成するか、既存のプロジェクトを選択してください。詳細については、プロジェクトリストを参照してください。
2. 構成済みのストレージおよびコンピューティングエンジンから必要なDLCエンジンを選択します。
ステップ2:実行リソースグループを購入し、プロジェクトに関連付けます
Notebookタスクをオーケストレーションスペースで定期的にスケジュールする必要がある場合は、スケジューリングリソースグループを購入し、指定されたプロジェクトに関連付けてください。具体的な操作手順の詳細については、実行リソースグループの購入とプロジェクトの関連付けを参照してください。
手順3:オフライン推論Notebookファイルを実行する
1. Notebookワークスペースを作成する:
プロジェクトでデータガバナンス機能を選択し、Notebook機能をクリックしてNotebook探索ページに進み、ワークスペースを作成をクリックします。
ワークスペース作成ページで、標準sparkエンジン(standard-S 1.1バージョン)を購入し、機械学習オプションとMFlowサービスにチェックを入れて選択してください。このページの設定操作の詳細については、Notebookワークスペースの作成を参照してください。
2. Notebook ファイルの作成:左側のエクスプローラーでフォルダーとNotebook ファイルを作成できます。注意:Notebook ファイルは(.ipynb)で終わる必要があります。エクスプローラーには、あらかじめ2つのビッグデータシリーズチュートリアルが組み込まれており、ユーザーはすぐに使用できます。
3. カーネル(kernel)を選択:
カーネルを選択をクリックします。

ドロップダウンオプションで「DLCリソースグループ」を選択します。
次のオプションレベルで、DLCデータエンジン内のあなたが作成したSpark MLlibリソースグループを選択してください。
4. 実行ボタンをクリックすると、カーネル設定ウィンドウが表示され、Sparkセッション名(ここではtest2と命名)をカスタマイズできます。この名前はDLCでセッションを検索するために使用され、自動解放時間を設定したり、高度なパラメータを編集して計算リソースを調整したりできます。
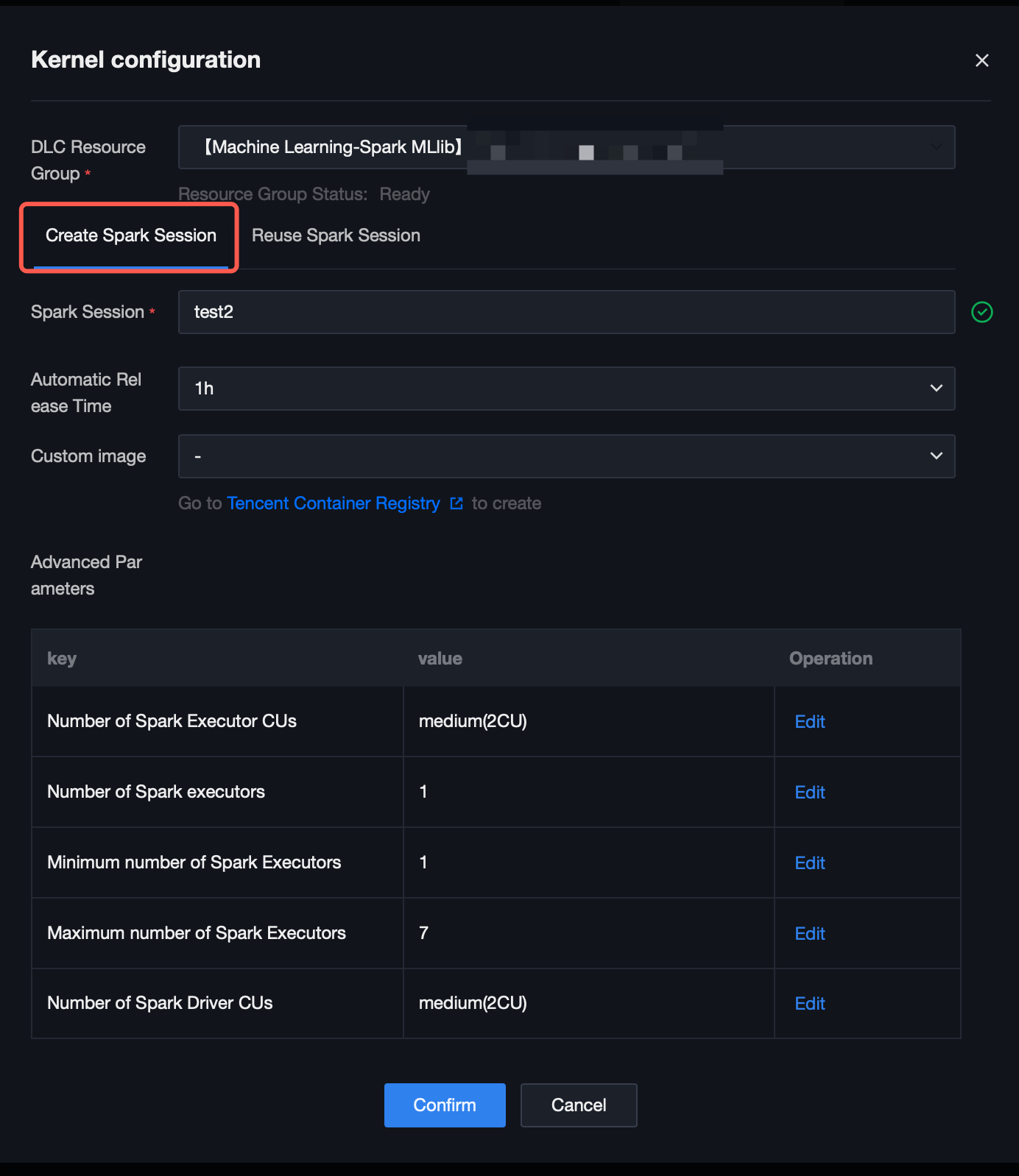
実践チュートリアルの実行:2つの方法でデータセットをロードし、K近傍アルゴリズムを使用して異なる種類の花を分類し、分類結果を出力します。
from pyspark.sql import SparkSessionfrom sklearn import datasetsfrom sklearn.neighbors import KNeighborsClassifierimport mlflowfrom mlflow.models import infer_signaturespark = SparkSession.builder.getOrCreate()#データセットをロードする#方法1:機械学習ライブラリを使用してデータセットをロードするX, y = datasets.load_iris(as_frame=True, return_X_y=True)#方法2:tencentcloud-dlc-connectorを使用してDLCのデータをロードする#ドライバをインストールする!pip install tencentcloud-dlc-connector!pip install --upgrade 'sqlalchemy<2.0'#バージョンをインストールする!pip install --upgrade pandas==2.2.3!pip install numpy!pip install matplotlibimport pandas as pdimport numpy as npimport tdlc_connectorfrom tdlc_connector import constantsmlflow.sklearn.autolog()# tdlc-connectorを使用してテーブル方式でアクセスしますconn = tdlc_connector.connect(region="ap-***", #正しいアドレスを入力してください、例:ap-Singapore,ap-Shanghaisecret_id="*******",secret_key="*******",engine="your engine",#購入したエンジン名を入力してくださいresource_group=None,engine_type=constants.EngineType.AUTO,result_style=constants.ResultStyles.LIST,download=True)query = """SELECT `sepal.length`, `sepal.width`,`petal.length`,`petal.width`,species FROM at_database_testnotebook.demo_test_sklearn"""iris = pd.read_sql(query, conn)spark_iris = spark.createDataFrame(iris)#特徴列とターゲット列の分割feature_cols = ["sepal_length", "sepal_width", "petal_length", "petal_width"]X = spark_iris.select(feature_cols)X = spark_iris.select(feature_cols)y = spark_iris.select("species")#K近傍法を使用した分類model = KNeighborsClassifier()model.fit(X, y)predictions = model.predict(X)signature = infer_signature(X, predictions)with mlflow.start_run():model_info = mlflow.sklearn.log_model(model, artifact_path="model", signature=signature)infer_spark_df = spark.createDataFrame(X)pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_info.model_uri)result = infer_spark_df.select(pyfunc_udf(*X.columns).alias("predictions")).toPandas()print(result)
ステップ4:実行結果の確認とモデル管理
1. 実行結果のリンクをクリックしてモデル実験インターフェースに入ると、モデルの詳細情報が表示され、モデル登録をクリックすると、そのモデルをモデル管理に保存できます。
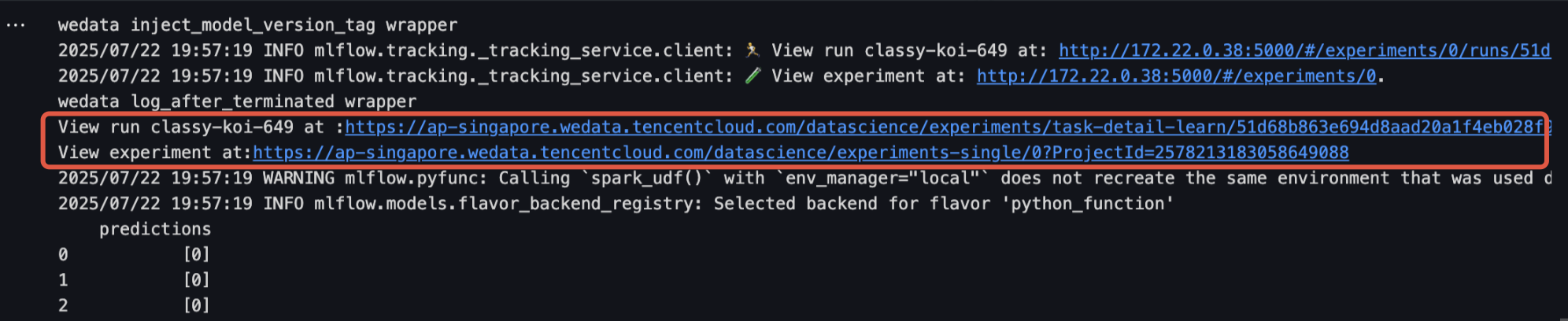
2. モデル管理インターフェースでは、登録されたモデルおよびモデルのバージョンを確認できます。
DLCでSparkセッションを確認する
1. 標準エンジン ページに戻り、購入したエンジンの詳細ページに移動し、リソースグループ管理を選択します。
2. SparkMLlibフレームワークに基づいて作成されたリソースグループをクリックし、Sparkセッションを選択します。Sparkセッションの自動破棄時間を確認し、操作欄のKillを使用してSparkセッションを破棄できます。
フィードバック