AIカスタマーサポート
ダウンロード
フォーカスモード
フォントサイズ
シーン紹介
インテリジェント音声カスタマーサービスは、人工知能と音声認識技術を活用して自動化されたインタラクションと問題解決を実現する顧客サービスシステムです。AI大規模モデルが登場する以前は、インテリジェントカスタマーサービスは主に自然言語処理と機械学習アルゴリズムを利用して顧客の意図を理解し、事前に設定されたルールとナレッジベースに依存して問題解決を行っていました。LLMの発展に伴い、ますます多くのインテリジェントカスタマーサービスが大規模モデルの能力を取り入れています。LLM技術により、インテリジェント音声カスタマーサービスは対話の文脈をより深く理解できるようになり、一貫性のある対話交流を実現しています。
RTC技術の導入により、インテリジェント音声カスタマーサービスにリアルタイム通信の能力がもたらされました。これにより、インテリジェントカスタマーサービスは顧客のニーズにより迅速に対応し、即時のフィードバックと解決策を提供できるようになります。また、Tencent RTCは複数人通話や画面共有などの機能もサポートしており、カスタマーサービスの効率と品質をさらに向上させています。
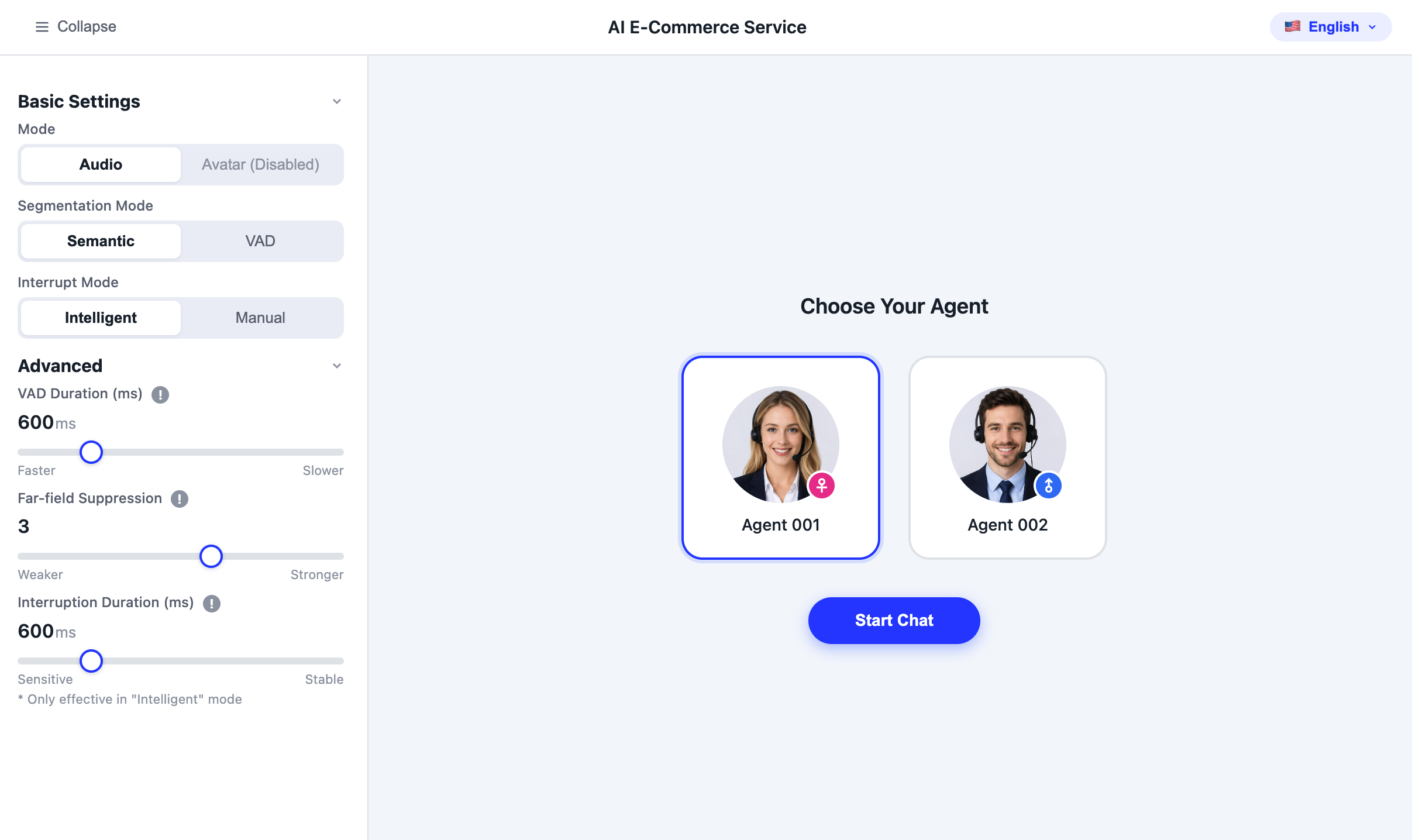
実現ソリューション
通常、完全なインテリジェントカスタマーサービスシーンを実現するには、複数のモジュールが関与します:TRTC、AIリアルタイム対話、STT、LLM、TTSなど。各モジュールのキーアクション及び機能ポイントは以下の表の通りです:
機能 | AIインテリジェントカスタマーサービスシーンへの応用 |
RTC | ストリーミング伝送技術により、音声とビデオデータの連続性と安定性が確保され、遅延やジッターが減少し、実際のカスタマーサービス通話に近い高品質な体験を提供できます。ユーザーはインテリジェントカスタマーサービスシステムとより自然に対話でき、あたかも実際のカスタマーサービスと話しているかのようで、このようなインタラクション体験はユーザー満足度を著しく向上させることができます。 |
Conversational AI | Tencent Conversational AIソリューションは、顧客が複数のAI大規模モデルサービスを柔軟に導入し、AIとユーザー間のRTCインタラクションを実現し、ビジネスシーンに適したConversational AI能力を構築します。Tencent Real-Time Communication(Tencent RTC)のグローバルな低遅延伝送を基盤に、音声対話の遅延は1秒以下で、対話効果は自然でリアル、接続は容易で即座に利用可能です。 |
STT | STTモジュールはユーザーの音声ストリームをリアルタイムでキャッチし、テキストに変換した後、LLMに送信して処理します。STTモジュールは、TRTCの超低遅延オーディオパイプラインと先進的なオーディオ処理能力、AIノイズリダクションとエコーキャンセルを活用し、騒がしい環境でもクリアで正確な文字起こしを提供します。 |
LLM | LLM技術により、インテリジェント音声カスタマーサービスは対話のコンテキストをよりよく理解できるようになり、一貫性のある対話が可能になります。LLMは会話中の意味や文脈情報を捉え、ユーザーの意図を認識し、前回の会話内容と現在の対話を関連付けることができます。 |
TTS | サードパーティのTTSの導入をサポートし、モデルに個性的なトレーニングデータを導入したり、モデルのパラメータを調整したりすることで、特定の要件に合致した音声出力を生成できます。インテリジェント音声カスタマーサービスは、ユーザーの好みや特定のシーンのニーズに応じて、異なる音声スタイルを提供することが可能です。 |
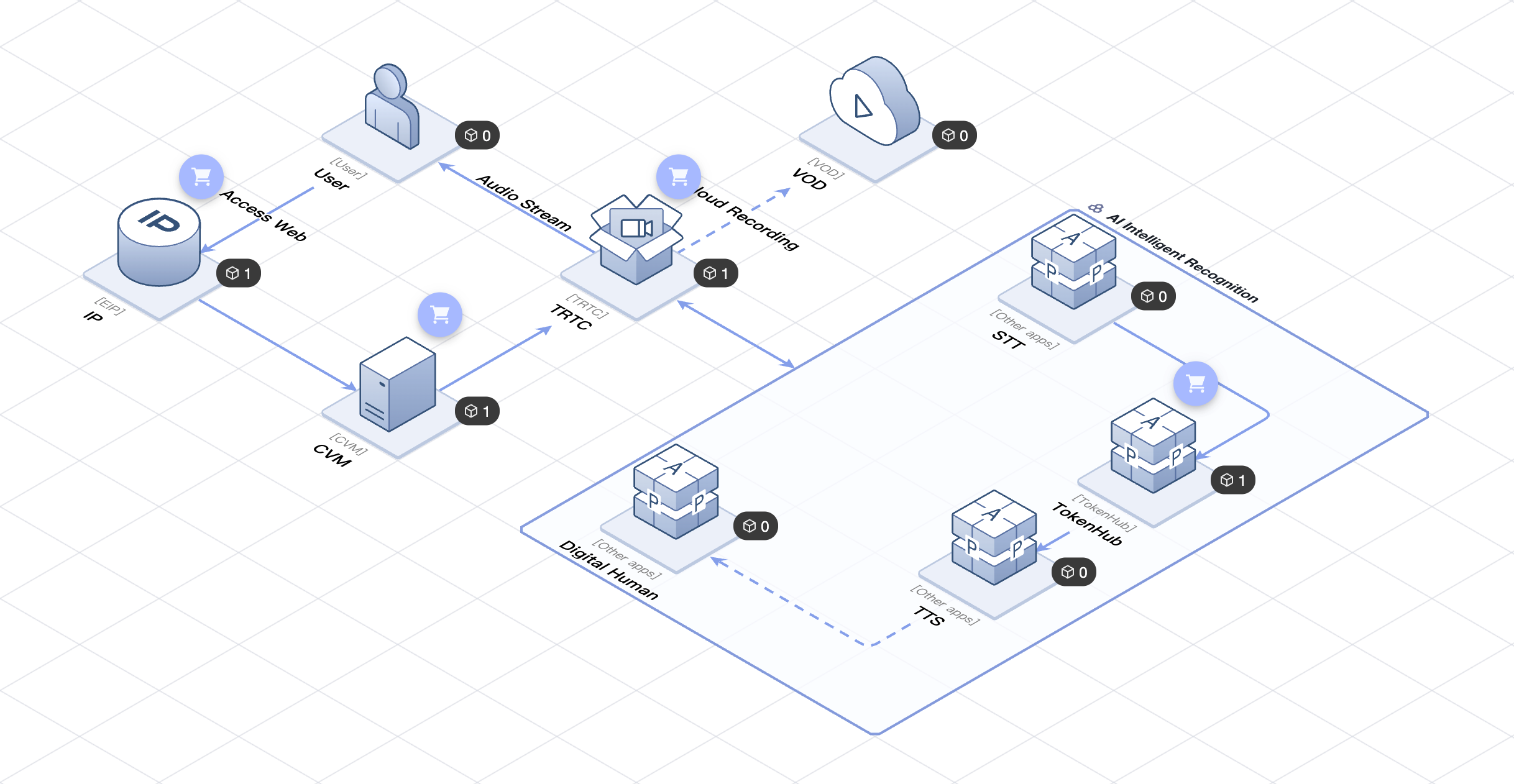
ソリューション・アーキテクチャ
以下は、Tencent Cloud TSAアーキテクチャガバナンスに基づいて構築されたAIインテリジェントカスタマーサービスソリューションの技術アーキテクチャです。TSAを通じて迅速にデプロイできます。
前提条件
RTC Engineの準備
RTC Engineアプリケーションを作成:Tencent RTCコンソール > アプリケーション > RTC Engineアプリケーションを作成。詳細な手順については対話型AIサービスの開通をご参照ください。
注意:
RTC Engine体験版はAIリアルタイム対話、AI II機能をサポートしており、発生した利用料金は従量課金のポストペイドとなります。具体的な課金ルールについてはAIリアルタイム対話の課金説明をご参照ください。
STTの準備
TRTCに組み込まれたTencent ASRを使用します:
Tencent ASRはTRTCに組み込まれた音声認識エンジンです。Azure、Deepgram、Sonioxなどのサードパーティプロバイダーとは異なり、CustomParamフィールドは不要で、STTConfigのトップレベルフィールドのみを設定すれば済みます。Tencent ASRの完全なパラメータリファレンスについては、ASRパラメータ設定ガイドをご参照ください。
サードパーティSTTを使用:現在サポートされているSTTプロバイダーについては利用可能なプロバイダーをご参照ください。
LLMの準備
TRTCの柔軟なフレームワークは、OpenAI互換モデル(OpenAI、Gemini、MiniMax、Hunyuan)やDify、Cozeなどのインテリジェントエージェントプラットフォームを含む、任意のメインストリームLLMの接続をサポートしています。具体的なシーンに応じて最適なエンジンを選択できます。具体的にサポートされているLLMプロバイダーについては利用可能なプロバイダーをご参照ください。
TTSの準備
TRTCに組み込まれたネイティブリアルタイムTTSを使用します:
TRTCに組み込まれたTTSサービスを使用する場合は、Text-to-Speech Configurationをご参照の上、StartAIConversation APIのTTSConfigフィールドに指定形式のJSON文字列を渡してください。外部アカウントやAPIキーは必要ありません。
サードパーティまたはカスタマイズTTSを使用:現在サポートされているTTSプロバイダーについては利用可能なプロバイダーをご参照ください。
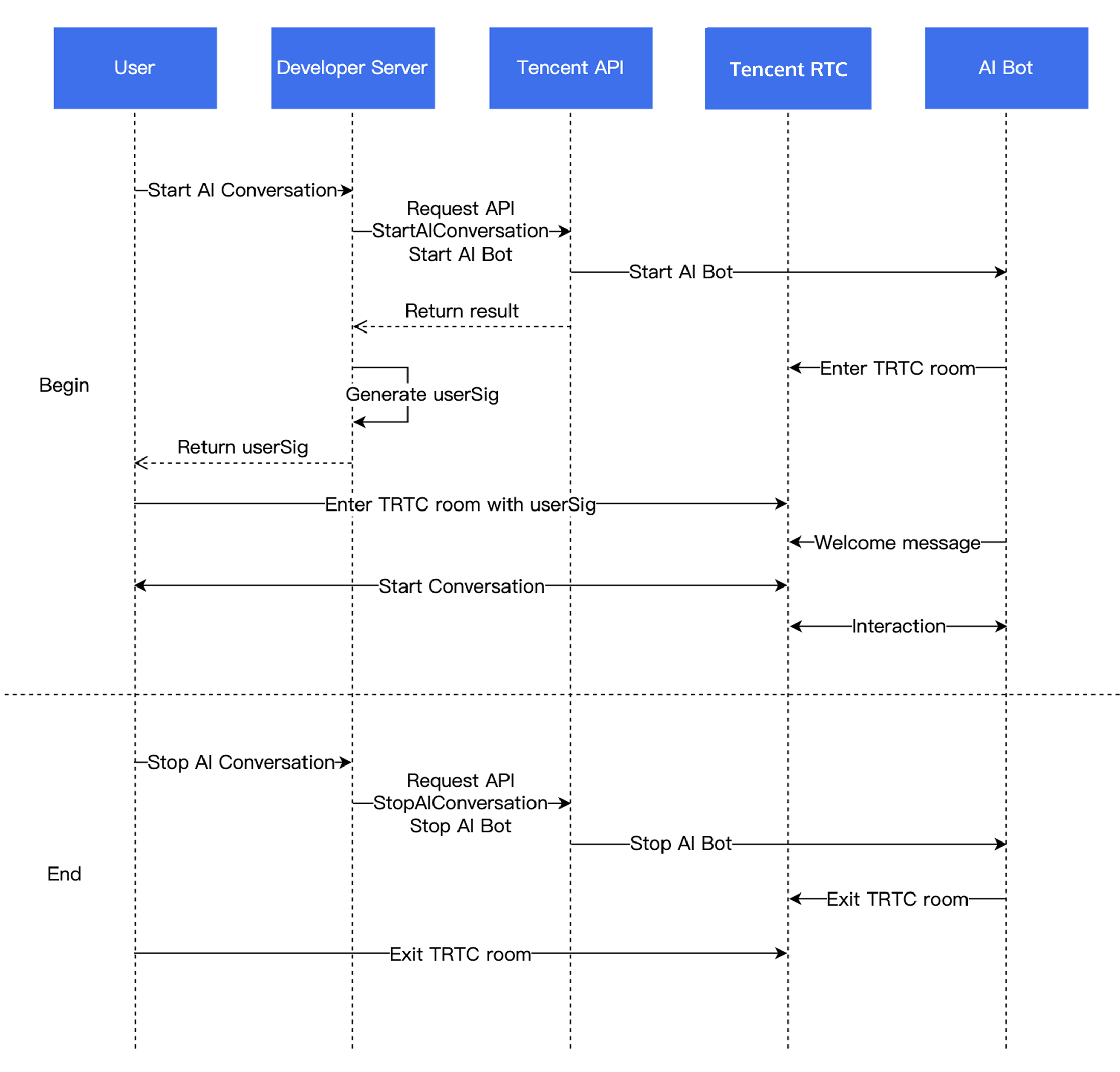
導入手順
業務プロセスフロー図
ステップ1:RTC Engine SDKの統合
RTC Engine SDKをプロジェクトにインポートし、TRTCルームに入室します。インテリジェントカスタマーサービスの入室シーンパラメータとしては、音声対話カスタマーサービス:
TRTCAppSceneAudioCallまたはデジタルヒューマンビデオカスタマーサービス:TRTCAppSceneVideoCallの使用をお勧めします。ステップ2:オーディオストリームを公開
startLocalAudioを呼び出してマイク収集を開始できます。このインターフェースでは、qualityパラメータを使用して収集モードを指定する必要があります。このパラメータの名前はqualityですが、品質が高いほど良いというわけではなく、異なるビジネスシーンに最適なパラメータ選択があります(このパラメータのより正確な意味はsceneです)。
AI対話シーンではSPEECHモードの使用をお勧めします。このモードでは、SDKのオーディオモジュールが音声信号の抽出に注力し、周囲の環境ノイズを最大限にフィルタリングします。また、このモードのオーディオデータは、劣悪なネットワーク品質に対する耐性も向上します。そのため、このモードは「ビデオ通話」や「オンライン会議」など、音声コミュニケーションを重視するシーンに特に適しています。
// マイク収集を開始し、現在のシーンを音声モード(高ノイズ抑制能力、強弱ネットワーク耐性)に設定しますmCloud.startLocalAudio(TRTCCloudDef.TRTC_AUDIO_QUALITY_SPEECH);
self.trtcCloud = [TRTCCloud sharedInstance];// マイク収集を開始し、現在のシーンを音声モード(高ノイズ抑制能力、強弱ネットワーク耐性)に設定します[self.trtcCloud startLocalAudio:TRTCAudioQualitySpeech];
// マイク収集を開始し、現在のシーンを音声モード(高ノイズ抑制能力、強弱ネットワーク耐性)に設定しますtrtcCloud.startLocalAudio(TRTCAudioQuality.speech);
trtc.startLocalAudio()メソッドを使用してマイクを有効化し、ルームに配信します。
await trtc.startLocalAudio({ option: { profile: TRTC.TYPE.AUDIO_PROFILE_STANDARD }});
// マイク収集を開始し、現在のシーンを音声モードに設定します// 高いノイズ抑制能力、強弱ネットワーク耐性を持ちますITRTCCloud* trtcCloud = CRTCWindowsApp::GetInstance()->trtc_cloud_;trtcCloud->startLocalAudio(TRTCAudioQualitySpeech);
// マイク収集を開始し、現在のシーンを音声モードに設定します// 高いノイズ抑制能力、強弱ネットワーク耐性を持ちますAppDelegate *appDelegate = (AppDelegate *)[[NSApplication sharedApplication] delegate];[appDelegate.trtcCloud startLocalAudio:TRTCAudioQualitySpeech];
ステップ3:AI対話を開始
AI対話を開始:StartAIConversation
業務バックエンドからAI対話タスク開始インターフェースを呼び出して、AIリアルタイム対話を開始します。呼び出しが成功すると、AIボットがRTC Engineルームに入室します。前提条件のSTT/LLM/TTS関連情報を
STTConfig、LLMConfig、TTSConfigに入力します。以下では、STTエンジンとしてTencent ASRを例に、
STTConfigの設定方法を説明します。設定説明
設定サンプル
{"Language": "zh","VadSilenceTime": 1000}
以下では、OpenAI標準プロトコルのLLMモデルを例に、
LLMConfigの設定方法を説明します。設定説明
フィールド | タイプ | 必須 | 説明 |
LLMType | String | はい | 大規模モデルタイプ。OpenAI APIプロトコルに準拠する大規模モデルは、すべて openaiと入力します。 |
Model | String | はい | 具体的なモデル名。例えば、 gpt-4o、deepseek-chatです。 |
APIKey | String | はい | 大規模モデルの APIKey。 |
APIUrl | String | はい | 大規模モデルの APIUrl。 |
Streaming | Boolean | いいえ | ストリーミング形式かどうか。デフォルトは falseで、trueを入力することを推奨します。 |
SystemPrompt | String | いいえ | システムプロンプト。 |
Timeout | Float | いいえ | タイムアウト時間。有効範囲 [1、50]、デフォルトは 3 秒(単位:秒)。 |
History | Integer | いいえ | LLMのコンテキストラウンド数を設定。デフォルト値:0(コンテキスト管理を提供しません)、最大値:50(最近50ラウンドのコンテキスト管理を提供)。 |
MaxTokens | Integer | いいえ | 出力テキストの最大 token 制限。 |
Temperature | Float | いいえ | サンプリング温度。 |
TopP | Float | いいえ | サンプリングの選択範囲で、出力 token の多様性を制御。 |
UserMessages | Object[] | いいえ | ユーザープロンプト。 |
MetaInfo | Object | いいえ | カスタムパラメータは、リクエストの body 内に置かれ、大規模モデルに透過転送します。 |
設定サンプル
{"LLMType": "openai","Model": "gpt-4o","APIKey": "api-key","APIUrl": "https://api.openai.com/v1/chat/completions","Streaming": true,"SystemPrompt": "あなたは個人アシスタントです","Timeout": 3.0,"History": 5,"MetaInfo": {},"MaxTokens": 4096,"Temperature": 0.8,"TopP": 0.8,"UserMessages": [{"Role": "user","Content": "content"},{"Role": "assistant","Content": "content"}]}
以下では、TRTC組み込みTTSを例に、
TTSConfigの設定方法を説明します。設定説明
フィールド | タイプ | 必須 | 説明 |
TTSType | String | はい | 固定値:"flow"。 |
VoiceId | String | はい | |
Model | String | はい | TTSモデルバージョンです。現在のデフォルト:flow_01_turbo。 |
Speed | Float | いいえ | 話速です。範囲:[0.5、2.0]。デフォルト値:1.0。 |
Volume | Float | いいえ | 音量です。範囲:[0、10]。デフォルト値:1.0。 |
Pitch | Integer | いいえ | ピッチ調整です。範囲:[-12、12]。デフォルト値:0。 |
Language | String | いいえ | 言語ID:zh(中国語)、en(英語)、yue(広東語)。 |
設定サンプル
{"TTSType": "flow","VoiceId": "v-female-R2s4N9qJ","Model": "flow_01_turbo","Speed": 1.0,"Volume": 1.0,"Pitch": 0,"Language": "zh"}
現在サポートされている
STTConfig、LLMConfig、TTSConfigの設定説明:注意:
RoomIdはクライアント側で入室するRoomIdと一致している必要があり、ルーム番号のタイプ(数字ルーム番号、文字列ルーム番号)も同じでなければなりません(即ち、ボットとユーザーが同じルームにいることを確認する必要があります)。TargetUserIdはクライアント側のユーザーが入室時に使用するUserIdと一致している必要があります。LLMConfigとTTSConfigはどちらもJSON文字列であり、Conversational AIを正常に開始するには、正しく設定する必要があります。ステップ4:AI対話字幕とAI状態の受信
リアルタイム字幕を受信
メッセージ形式:
{"type": 10000, // 10000はリアルタイム字幕の配信を示します"sender": "user_a", // 発言者のuserid"receiver": [], // 受信者useridリスト、このメッセージは実際にはルーム内でブロードキャストされます"payload": {"text":"", // 音声認識されたテキスト"translation_text":"", // 翻訳されたテキスト"start_time":"00:00:01", // この文の開始時間"end_time":"00:00:02", // この文の終了時間"roundid": "xxxxx", // 一連の対話を一意に識別します"end": true // trueの場合、これは完全な文であることを示します}}
AIボットステータスを受信
メッセージ形式:
{"type": 10001, // AIボットのステータス"sender": "user_a", // 送信者userid、ここはボットのidです"receiver": [], // 受信者useridリスト、このメッセージは実際にはルーム内でブロードキャストされます"payload": {"roundid": "xxx", // 一連の対話を一意に識別します"timestamp": 123,"state": 1, // 1 聴取中 2 思考中 3 発言中 4 中断された}}
サンプルコード
@Overridepublic void onRecvCustomCmdMsg(String userId, int cmdID, int seq, byte[] message) {String data = new String(message, StandardCharsets.UTF_8);try {JSONObject jsonData = new JSONObject(data);Log.i(TAG, String.format("receive custom msg from %s cmdId: %d seq: %d data: %s", userId, cmdID, seq, data));} catch (JSONException e) {Log.e(TAG, "onRecvCustomCmdMsg err");throw new RuntimeException(e);}}
func onRecvCustomCmdMsgUserId(_ userId: String, cmdID: Int, seq: UInt32, message: Data) {if cmdID == 1 {do {if let jsonObject = try JSONSerialization.jsonObject(with: message, options: []) as? [String: Any] {print("Dictionary: \\(jsonObject)")} else {print("The data is not a dictionary.")}} catch {print("Error parsing JSON: \\(error)")}}}
trtcClient.on(TRTC.EVENT.CUSTOM_MESSAGE, (event) => {let data = new TextDecoder().decode(event.data);let jsonData = JSON.parse(data);console.log(`receive custom msg from ${event.userId} cmdId: ${event.cmdId} seq: ${event.seq} data: ${data}`);if (jsonData.type == 10000 && jsonData.payload.end == false) {// 字幕中間状態} else if (jsonData.type == 10000 && jsonData.payload.end == true) {// 一言で完了}});
void onRecvCustomCmdMsg(const char* userId, int cmdID, int seq,const uint8_t* message, uint32_t msgLen) {std::string data;if (message != nullptr && msgLen > 0) {data.assign(reinterpret_cast<const char*>(message), msgLen);}if (cmdID == 1) {try {auto j = nlohmann::json::parse(data);std::cout << "Dictionary: " << j.dump() << std::endl;} catch (const std::exception& e) {std::cerr << "Error parsing JSON: " << e.what() << std::endl;}return;}}
void onRecvCustomCmdMsg(String userId, int cmdID, int seq, String message) {if (cmdID == 1) {try {final decoded = json.decode(message);if (decoded is Map<String, dynamic>) {print('Dictionary: $decoded');} else {print('The data is not a dictionary. Raw: $decoded');}} catch (e) {print('Error parsing JSON: $e');}return;}}
説明:
TRTCは、さらに多くのAI対話クライアントのコールバックを提供します。詳細は以下をご参照ください:AI対話状態コールバック、AI対話字幕コールバック、AI対話指標コールバック、AI対話エラーコールバック。
ステップ5:AI対話を停止し、RTC Engineルームを退出します
1. サーバー側でAI対話タスクを停止します。業務バックエンドからAI対話停止インターフェースを呼び出し、この対話タスクを停止します。
2. クライアント側でRTC Engineルームを退出する際は、ルーム退出を参照することをお勧めします。
高度な機能
クライアント側でのカスタムメッセージ送信
端側でカスタムシグナリングを送信することで、ASRプロセスをスキップし、直接AIとテキストコミュニケーションを行ったり、中断シグナリングを送信して中断を行ったりできます。
type | 説明 |
20000 | カスタマイズしたテキストを送信し、ASRプロセスをスキップして、直接AI Serviceと文字でコミュニケーションを行います。 |
20001 | 中断シグナリングを送信して中断を行います。 |
アップリンクシグナルを送信し、ASRプロセスをスキップして、直接AIとテキストコミュニケーションを行います。
{"type": 20000, // 側でカスタムテキストメッセージを送信"sender": "user_a", // 送信者userid、サーバー側ではこのuseridが有効かどうかをチェックします"receiver": ["user_bot"], // 受信者のuseridリスト、ボットのuseridのみ記入してください。サーバー側ではこのuseridが有効かどうかをチェックします"payload": {"id": "uuid", // メッセージidであり、uuidを使用可能、問題の調査に使用"message": "xxx", // メッセージ内容"timestamp": 123 // タイムスタンプ、問題の調査に使用}}
中断シグナリングを送信して中断を行います。
{"type": 20001, // 側で中断シグナリングを送信"sender": "user_a", // 送信者userid、サーバー側ではこのuseridが有効かどうかをチェックします"receiver": ["user_bot"], // 受信者のuseridリスト、ボットのuseridのみ記入してください。サーバー側ではこのuseridが有効かどうかをチェックします"payload": {"id": "uuid", // メッセージidであり、uuidを使用可能、問題の調査に使用"timestamp": 123 // タイムスタンプ、問題の調査に使用}}
注意:
現在、ミニプログラム側ではカスタムメッセージの受信と送信はサポートされていません。ミニプログラム側で字幕の受信やメッセージの送信などの機能を実現したい場合は、Chatが提供するインスタントメッセージングを使用する必要があります。詳細はAI対話Chatシグナリングソリューションをご参照ください。Chatシグナリングチャネルの開通は、ビジネス担当者への連絡またはチケットの提出当社へのお問い合わせを通じて行えます。
デジタルヒューマンビデオカスタマーサービスの実装
TCADHサービスを使用してAIインテリジェントカスタマーサービスの可視化デジタルヒューマンイメージを生成することで、デジタルヒューマンビデオカスタマーサービスを実現し、インタラクション体験を強化できます。
デジタルヒューマンサービスの開通
1. サービスを開通します。クラウドインテリジェントデジタルヒューマン購入ページにアクセスし、イメージレンタルまたはイメージカスタマイズを通じて2Dまたは3Dデジタルヒューマンイメージアセットを取得します。同時に、クラウドレンダリングセッションインタラクションの同時実行を購入する必要があります。
2. インタラクティブプロジェクトを作成します。デジタルヒューマンサービスプラットフォームにログインし、インタラクティブシナリオを選択し、新規プロジェクトを作成をクリックします。
3. イメージと音声を設定します。編集ボタンをクリックし、タブを切り替えてイメージ、ポーズ、音声、出力形式を変更します。
4. プロジェクトキーを取得します。API Integrationに切り替え、View Keyをクリックし、キーパラメータ
appkey、accesstoken、virtualmanProjectIdを取得します。デジタルヒューマンパラメータの設定
{"AvatarType" : "tencent", // デジタルヒューマンタイプ、現在はtencentのみサポート"Appkey" : "appkey", // デジタルヒューマンサービスのappkey"AccessToken" : "accesstoken", // デジタルヒューマンサービスのaccesstoken"VirtualmanProjectId" : "virtualmanProjectId", // デジタルヒューマンサービスのvirtualmanProjectId"AvatarUserID" : "robot_xxxx", // TRTCデジタルヒューマンユーザーuserID"DriverType": 1, // デジタルヒューマンドライブ方式(純粋テキストドライブ)"AvatarUserSig" : "eJw1xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" // TRTCデジタルヒューマンユーザー署名}
クライアント側でのRTCビデオストリームサブスクリプション
AI対話タスクが正常に開始されると、デジタルヒューマンは独立したユーザーとしてRTCルームに入室し、ストリーミングを開始します。クライアントはリモートのデジタルヒューマンビデオストリームを監視、サブスクライブ、再生するだけで済みます。
1. ルーム入室前にTRTC.EVENT.REMOTE_VIDEO_AVAILABLEイベントを監視し、すべてのリモートユーザーのビデオ公開イベントを受信します。
2. このイベントを受信した際、trtc.startRemoteVideo()を使用してリモートビデオストリームを再生します。
trtc.on(TRTC.EVENT.REMOTE_VIDEO_AVAILABLE, ({ userId, streamType }) => {// To play the video image, you need to place an HTMLElement in the DOM,// which can be a div tag, assuming its id is `${userId}_${streamType}`const view = `${userId}_${streamType}`;trtc.startRemoteVideo({ userId, streamType, view });});
1. ルーム入室前にonUserVideoAvailableを監視し、
onUserVideoAvailable(userId, true)通知を受信した場合、その画面には再生可能なビデオフレームが到達していることを示します。2.
startRemoteViewインターフェースを呼び出すことで、リモートユーザーのビデオ画面を再生できます。// リモートユーザーrobot_xxxxのメインストリームビデオ画面を再生しますtrtcCloud.startRemoteView("robot_xxxx", TRTCVideoStreamType.big, remoteViewId);
1. ルーム入室前にonUserVideoAvailableを監視し、
onUserVideoAvailable(userId, true)通知を受信した場合、その画面には再生可能なビデオフレームが到達していることを示します。2.
startRemoteViewを呼び出して、リモートビデオ画面を再生します。// リモート画面を再生しますTXCloudVideoView cameraVideo = findViewById(R.id.txcvv_main_local);mCloud.startRemoteView("robot_xxxx", TRTCCloudDef.TRTC_VIDEO_STREAM_TYPE_BIG, cameraVideo); // 高精細大画面でリモートビデオコンテンツを再生します
1. ルーム入室前にonUserVideoAvailableを監視し、
onUserVideoAvailable(userId, YES)通知を受信した場合、その画面には再生可能なビデオフレームが到達していることを示します。2.
startRemoteViewを呼び出して、リモートビデオ画面を再生します。- (void)startRemoteView {// リモート画面を再生しますAppDelegate *appDelegate = (AppDelegate *)[[UIApplication sharedApplication] delegate];[appDelegate.trtcCloud startRemoteView:@"robot_xxxx" streamType:TRTCVideoStreamTypeBig view:self.remoteVideoView];}
オペレーターへの転送
人的サービスはインテリジェントカスタマーサービスシステムに不可欠な要素の一つです。AIカスタマーサービスがユーザーのニーズを満たせない場合、オペレーターへの転送機能を提供することで、ユーザーの使用体験を大幅に向上させることができます。
Cloud Contact Centerは、企業が電話、オンラインコミュニケーション、オーディオ・ビデオ通話を統合したカスタマー連絡プラットフォームを迅速に構築することを支援します。Cloud Contact Center SDKは、通信ワークベンチを企業独自の業務システムに組み込むことをサポートし、企業に安定した柔軟な融合通信基盤を提供します。オペレーターサービスの導入にはCloud Contact Centerの採用をお勧めします。
トリガー判定
1. ボタンによるトリガー。ユーザーが「オペレーターに転送」ボタンをクリックすると、クライアント側で直接オペレーターへの転送業務フローがトリガーされます。
2. 意図識別。LLM Function Callによるセマンティック解析を通じて、ユーザーがAIカスタマーサービスとの対話中に表現したオペレーター転送意図を判定します。ヒットした場合、LLMはtool_callsを返し、業務層がオペレーター転送アクションを実行します。
オペレーター転送ツール関数を定義します。例は以下の通りです:
{"type": "function","function": {"name": "transfer_to_agent","description": "ユーザーが明確にオペレーターを要求した場合、または問題がAIの能力を超えている場合、苦情・返金・紛争に関連する場合に呼び出します。単なる雑談や不満の場合は呼び出しません""parameters": {"type": "object","properties": {"reason": { "type": "string", "description": "オペレーター転送の理由" },"department": { "type": "string", "enum": ["アフターサービス", "技術", "苦情"], "description": "ターゲットスキルグループ" },"urgency": { "type": "string", "enum": ["low", "high"], "description": "緊急度" }},"required": ["reason"]}}}
LLMは生成時にセマンティック判定を行います:ユーザーの真の意図を理解し、各ツールのdescriptionを参照し、「今回、特定のツールを呼び出すべきかどうか」を決定します。
判定の結果、呼び出すべきと判断された場合、LLMは通常のテキストを返さず、構造化されたtool_calls(関数名および対話から自ら抽出したパラメータを含む)を返します。
業務中間層はfinish_reason === 'tool_calls'をキャッチし、オペレーター転送アクションを実行します。
説明:
転送実行
1. 業務バックエンドはStopAIConversationを呼び出してAI対話タスクを停止します。
2. 業務バックエンドはTCCCを起動し、departmentに基づいてターゲットスキルグループにルートします。
3. TCCCはオペレーター席を割り当てます(IVRからオペレーター転送ノード → スキルグループ → 空いている席)。
4. オペレーターが対話を引き継ぎます(SIP電話 / ウェブワークベンチ / SDK統合)。
説明:
カスタムナレッジベースとRAG
インテリジェントカスタマーサービスシーンにおいて、企業は通常、自社のナレッジベース(様々なドキュメント、Q&A素材など)をアップロードする必要があり、これにはRAG(検索拡張生成)の能力が活用されます。TRTC AIリアルタイム対話(Conversational AI)ソリューションでは、TRTC自体はナレッジベースを保存せず、検索も行いません。ナレッジベースとRAGはどちらもLLMのレイヤーで発生します。
コアメカニズム
TRTCはStartAIConversationインターフェースの
LLMConfigフィールドを通じて、STT書き起こし後のテキストを外部LLMまたはインテリジェントエージェントプラットフォームに転送します。したがって、「カスタムナレッジベースの注入/RAGの実現」の本質は、LLMの段階で検索能力を持つバックエンドまたはプラットフォームに接続することです。TRTCは各LLMリクエストに以下のHTTPリクエストヘッダーを自動的に注入し、業務バックエンドでのユーザーレベルのナレッジベースルーティング、認証、ログ記録などに利用できます。リクエストヘッダ | 説明 |
X-Task-Id | 現在のAIセッションの一意のタスク識別子。 |
X-Request-Id | リクエスト識別子は、同一リクエストの再試行時に一貫性を保ちます。 |
X-Sdk-App-Id | あなたのTRTCアプリケーションのSdkAppIdです。 |
X-User-Id | 現在のセッションにおけるユーザーIDです。 |
X-Room-Id | 現在のTRTCセッションのルームIDです。 |
X-Room-Id-Type | ルームIDのタイプです。 "0" = 数字型、"1" = 文字列型。 |
利用可能なパス
現在、利用可能なナレッジベース注入およびRAG実現の3つのパスが提案されており、以下では複数の異なる次元から各実現パスの違いを比較します。
1. 自社構築のOpenAI互換中間層:業務側がOpenAI仕様に準拠した
/v1/chat/completionsインターフェースを独自に実装し、TRTCはそれを通常のOpenAIモデルとして呼び出します。業務インターフェース内部で「ナレッジベースの検索 → コンテキストの結合 → 実際の大規模モデルの呼び出し → ストリーミング返信」が完了し、RAGロジックは完全に自主管理可能です。2. Difyプラットフォーム:DifyのKnowledgeはそのRAG実装であり、公式にはRetrieval → Augmented → Generationのプロセスに明確に従っています。Difyプラットフォームでナレッジベースの作成、アプリケーションの作成、ナレッジベースのマウントなどのステップを通じてナレッジベースの設定と検索を完了し、最終的に
LLMConfigを介してTRTC Conversational AIに接続します。3. Cozeプラットフォーム:CozeのKnowledge(ナレッジベース)はそのRAG実装であり、同様にRetrieval → Augmented → Generationのプロセスに従います。Cozeプラットフォームでナレッジベースの新規作成、Botの作成とナレッジベースのバインド、Botの公開などのステップを通じてナレッジベースの設定と検索を完了し、最終的に
LLMConfigを介してTRTC Conversational AIに接続します。注意:
コンテキスト管理とパーソナライズドメモリ
インテリジェントカスタマーサービスシーンにおいて、ユーザーの問題相談は通常連続性を持ち、過去の対話履歴を新たな対話に取り入れることで、AIカスタマーサービスはユーザー相談の背景情報をより深く理解し、ユーザーの問題をより適切に解決できます。RAGはAIを「より博識に」(ドメイン知識を理解)、記憶/コンテキストはAIを「よりあなたを理解するように」(ユーザーを記憶)します。両方ともStartAIConversationの
LLMConfigフィールドを通じて注入され、重ねて使用できます。以下では、LLMConfig内のコンテキストに関連する3つのフィールド、すなわち3層の記憶体系について説明します。3層メモリシステム
フィールド | メモリ階層 | コンテンツ | 精度 | 時間範囲 | 管理主体 |
SystemPrompt | 長期記憶 | ベースとなる人物設定 + ユーザーの長期的な嗜好のLLMサマリー | 中(サマリー) | 長期 | 業務側はサマリーをメンテナンスし、結合します。 |
UserMessages | 短期記憶 | 直近のN件の外部履歴メッセージの原文 | 高さ(原文) | 短期 | ビジネス側は対話を起動する際に注入します。 |
History | 通話内記憶 | 現在のTRTC通話中のマルチターンディアログのターン数 | 高さ(原文) | 当該通話 | TRTCは自動管理され、最大50ターンです。 |
コンテキストインジェクションの例
AI ECカスタマーサービスを例にとると:
SystemPromptにはカスタマーサービスの人物設定およびそのユーザーの長期プロファイル要約を書き込み、UserMessagesにはユーザーの最近の相談原文を注入し、Historyは今回の音声通話内での複数回の連続性を実現します。{"LLMType": "openai","Model": "gpt-5.5","APIKey": "<your_openai_api_key>","APIUrl": "https://api.openai.com/v1/chat/completions","Streaming": true,"SystemPrompt": "あなたはあるECプラットフォームのAIカスタマーサービスアシスタントであり、注文照会、返品交換、物流追跡、商品相談を担当し、簡潔で親しみやすい回答を提供します。\\n\\n【ユーザー長期記憶要約】\\n- ユーザーニックネーム:小明、ブラックカード会員、簡潔で直接的な返信を好む\\n- よく購入するカテゴリー:デジタル3C、過去に返品トラブルなし\\n- 前回の通話では『Bluetoothイヤホンの右耳が無音』について相談し、再ペアリングを提案済み"Timeout": 3.0,"History": 10,"UserMessages": [{ "Role": "user", "Content": "先週購入したイヤホンを返品したいです" },{ "Role": "assistant", "Content": "承知いたしました。ご注文番号NO.20260528001(Bluetoothイヤホン)は7日間返品保証期間内ですので、返品手続きを承ります。" },{ "Role": "user", "Content": "返金はいつ頃振り込まれますか" },{ "Role": "assistant", "Content": "商品返送受領後、1~3営業日以内にご利用の決済口座へ返金されます。" }]}
履歴データの取得
UserMessagesの短期相談原文、およびSystemPromptの長期要約データはどのように取得しますか。Chatテキストチャットは1対1チャット履歴メッセージのプルを通じて取得でき、そのコンテンツはユーザーとカスタマーサービスがChatの1対1チャットで生成した過去のチャット履歴です。
TRTC AIリアルタイム対話で生成された対話記録は、サーバー側903コールバックイベントを通じてリアルタイムに受信・保存できます。そのコンテンツは、ASR(STT)で識別されたユーザー音声テキストとLLMで生成された返信テキストです。
要約更新タイミング:長期要約は、各AIリアルタイム対話終了後に非同期で更新することを推奨します。これにより、通話起動速度への影響を回避できます。
プライバシーコンプライアンス要件:長期記憶要約は、重要な事実情報のみを保存し、元の対話全文は保持せず、ユーザー規約で明確に告知する必要があります。
注意:
注入する
UserMessagesの件数が多いほど、LLMの各呼び出しにおけるToken消費量が増加し、処理時間も長くなります。実際の要件とコストに基づいて適切に設定する必要があります。注入する
SystemPrompt要約は、300 Token以内に制御することを推奨します。長すぎると対話コンテキストウィンドウを圧迫し、LLMの最初のToken遅延に影響を与える可能性があります。インテリジェント割り込み遅延最適化
AIリアルタイム対話プロセス中のインテリジェント中断遅延を調整したい場合は、AI対話インターフェース開始内の
AgentConfig.InterruptSpeechDurationおよびSTTConfig.VadSilenceTimeパラメータを設定することで、中断遅延を高くまたは低く調整できます。誤った中断の確率を下げるために、遠距離人声抑制機能を同時に有効にすることをお勧めします。遠距離人声抑制
AIカスタマーサービスとの対話中、AIカスタマーサービスがユーザー側の他の背景音声をユーザーの発話として認識し、誤った中断や返信が発生する場合があります。このような状況をできるだけ避けるために、遠距離人声抑制機能を有効にする必要があります。AI対話タスク開始インターフェースを呼び出す際に、
STTConfig.VadLevelを2または3に設定すると、優れた遠距離人声抑制能力が得られます。パラメータ設定の説明
パラメータ | タイプ | 説明 |
AgentConfig.InterruptSpeechDuration | Integer | InterruptModeが0の場合に使用され、単位はミリ秒で、デフォルトは500msです。サーバー側でInterruptSpeechDurationミリ秒継続する人声を検出すると、中断を行うことを示します。 サンプル値:500 |
STTConfig.VadSilenceTime | Integer | ASR VADの時間であり、範囲は[240, 2000]で、デフォルトは1000、単位はmsです。より小さい値にするとASRの文切れが速くなります。 サンプル値:1000 |
STTConfig.VadLevel | Integer | VADの遠距離人声抑制機能(ASRの識別効果に影響を与えません)であり、範囲は[0, 5]で、デフォルトは0、遠距離人声抑制機能を有効化しないことを示します。2に設定することを推奨し、良好な遠距離人声抑制機能が得られます。騒がしいオフィス環境では3に設定でき、さらに騒がしい環境では4または5に設定できます。高いVadLevelは単語をノイズとしてフィルタリングする可能性があることに注意してください。 サンプル値:2 |
LLMパススルーカスタムメッセージ
大規模モデルがTTSプロセスに参加しないコンテンツを返す必要がある場合、大規模モデルの返すコンテンツにカスタムフィールド
metainfoを追加できます。AIサービスがmetainfoを検出すると、カスタムメッセージを通じてクライアントSDKに配信し、metainfoのパススルーを完了します。大規模モデル側での送信方法:大規模モデルが
chat.completion.chunkオブジェクトをストリーミング返信する際に、同時にmeta.infoのchunkを返します。{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-xxxx", "system_fingerprint": "fp_xxxx", "choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":null}]}{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-xxxx", "system_fingerprint": "fp_xxxx", "choices":[{"index":0,"delta":{"content":"Hello"},"logprobs":null,"finish_reason":null}]}// 以下のカスタムメッセージを追加{"id":"chatcmpl-123","type":"meta.info","created":1694268190,"metainfo": {}}{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-xxxx", "system_fingerprint": "fp_xxxx", "choices":[{"index":0,"delta":{},"logprobs":null,"finish_reason":"stop"}]}
クライアント側での受信方法:AIサービスが
metainfoを検出した後、RTC Engineのカスタムメッセージを通じて配信します。クライアント側ではSDKコールバックのonRecvCustomCmdMsgインターフェースを通じて受信できます。{"type": 10002, // カスタムメッセージ"sender": "user_a", // 送信者userid、ここはボットのidです"receiver": [], // 受信者useridリスト、このメッセージは実際にはルーム内でブロードキャストされます、"roundid": "xxxxxx","payload": {} // metainfo}
よくある質問
AIカスタマーサービスが応答しない / 音声再生がない
クライアントがマイク収集を開始しオーディオストリームを公開しているか、またはマイク権限が正常に付与されているかを確認します。
StartAIConversation内のRoomIdがクライアント側での入室時のRoomIdと一致し、かつルーム番号のタイプ(RoomIdType)も一致していることを確認します。LLMConfigとTTSConfigのJSON文字列形式が正しいか確認します。TencentCloud API鍵(
SecretId / SecretKey)が有効であり、かつQcloudTRTCFullAccessの全読み書きアクセス権限の付与が完了していることを確認します。サービスカテゴリ | エラーコード | エラー説明 |
STT(ASR) | 30100 | リクエストタイムアウトです。 |
| 30102 | 内部エラーです。 |
LLM | 30200 | LLMへのリクエストがタイムアウトしました。 |
| 30201 | LLMへのリクエストが頻度制限されました。 |
| 30202 | LLMサービスが失敗を返しました。 |
TTS | 30300 | TTSサービスへのリクエストがタイムアウトしました。 |
| 30301 | TTSへのリクエストが頻度制限されました。 |
| 30302 | TTSサービスが失敗を返しました。 |
LLM長時間出力なしまたはタイムアウトエラー
LLM Timeoutエラーが発生した場合、例えば
llm error Timeout on reading data from socketというメッセージが表示された場合、通常はLLMリクエストがタイムアウトしたことを意味します。LLMConfig内のTimeoutパラメータ値を適切に高く設定することができます(デフォルトは3秒)。また、LLMの先頭パケット処理時間が3秒を超える場合、比較的に高い対話遅延がAI対話の体験に影響を与えます。特別な要件がない場合は、LLMの先頭パケット処理時間を最適化することをお勧めします。詳細は対話遅延最適化をご参照ください。単一テキスト返信時の無応答
ユーザーが「はい」、「いいえ」などの単一文字で回答した場合、AIカスタマーサービスが応答しない(LLMにリクエストしない)場合は、AI対話インターフェースを起動する際の
AgentConfig.FilterOneWordパラメータがfalseに設定されているか確認してください(デフォルトはtrueで、ユーザーが一文字のみ発話した文をフィルタリングすることを意味します)。パラメータ | タイプ | 説明 |
FilterOneWord | Boolean | ユーザーが一文字しか発話していない文をフィルタリングするかどうか。trueはフィルタリングを、falseはフィルタリングしないことを示し、デフォルト値はtrueです。 サンプル値:true |
TRTC関連エラーのトラブルシューティング
RTC Engine SDKが回復不能なエラーに遭遇すると、
onErrorコールバックでエラーをスローします。一般的なエラーは以下の表をご参照ください:エラー | エラーコード | エラー説明 |
ERR_TRTC_USER_SIG_CHECK_FAILED | -100018 | UserSigの検証に失敗しました。署名が正しいか、または期限切れかどうかを確認してください。 |
ERR_TRTC_CONNECT_SERVER_TIMEOUT | -3308 | 入室リクエストがタイムアウトしました。ネットワーク接続が切断されているか、VPNが有効になっているか確認してください。 |
ERR_TRTC_INVALID_SDK_APPID | -3317 | 入室パラメータ SDKAppID が誤っています。TRTCParams.sdkAppId が空でないか確認してください。 |
ERR_MIC_NOT_AUTHORIZED | -1317 | マイクデバイスが未承認です。 |
フィードバック