TKE Serverlessクラスター関連
Download
フォーカスモード
フォントサイズ
ここではTKE Serverlessのクラスターに関するよくあるご質問をまとめ、クラスター関連のよくあるトラブルの原因とその解決方法をご紹介します。
Podの仕様が入力されたRequest/Limitと一致しないのはなぜですか。
Podのリソース量を割り当てる際、TKE Serverlessはワークロードによって設定されたRequestとLimit値に従ってリソース量を割り当てるのではなく、設定されたRequestとLimitについて計算を行い、Podの実行に必要なリソース量を自動的に判断します。Request、Limitの自動計算によってリソース仕様を指定する方法の詳細についてお知りになりたい場合は、CPU Pod仕様の計算方法およびGPU Pod仕様の計算方法をご参照ください。
TKE Serverlessクラスターのコンテナネットワークを追加または変更するにはどうすればよいですか。
クラスターを作成する際は、1つのVPCネットワークをクラスターネットワークとして選択し、同時に1つのサブネットをコンテナネットワークに指定します。詳細についてはコンテナネットワークの説明をご参照ください。ServerlessクラスターのPodはコンテナネットワークのサブネットIPを直接占有します。クラスターの使用中にコンテナネットワークを追加または変更したい場合は、スーパーノードの追加/除去操作によって実現できます。具体的な操作については次の手順をご参照ください。
ステップ1:スーパーノードを新規作成してコンテナネットワークを追加する
1. TKEコンソールにログインし、左側ナビゲーションバーのクラスターを選択します。
2. コンテナネットワークを変更したいクラスターIDをクリックし、クラスター基本情報ページに進みます。
3. 左側のスーパーノードを選択し、スーパーノードページで新規作成をクリックします。
4. スーパーノードの新規作成ページで、十分なIPを持つコンテナネットワークを選択し、OKをクリックすると作成が完了します。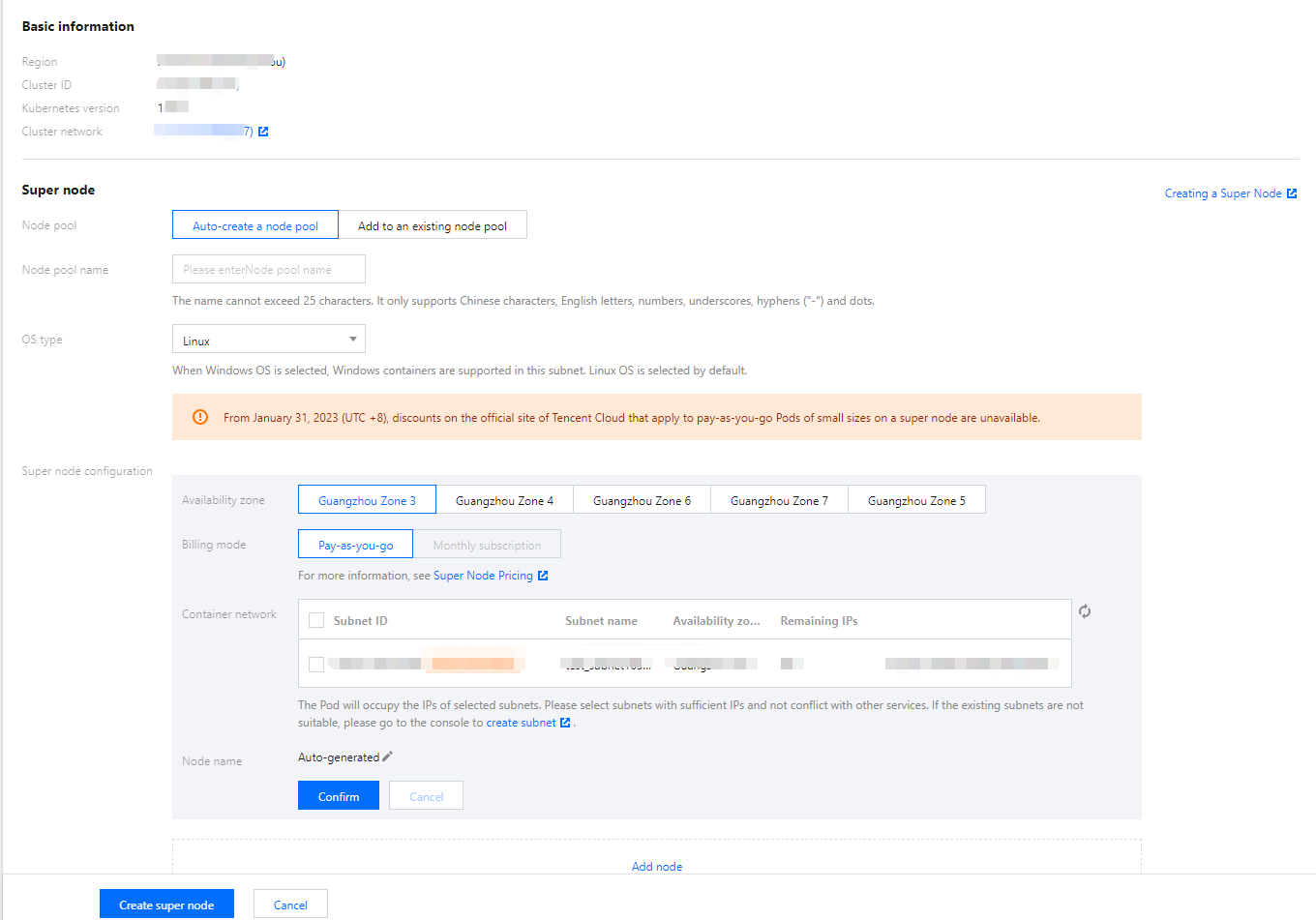
ステップ2:スーパーノードを除去してコンテナネットワークを削除する
注意
スーパーノードを除去した後に、Serverlessクラスターに少なくとも1つのスーパーノードが存在する必要があります。つまり、この時点でスーパーノードが1つしかない場合は、除去操作は実行できません。
スーパーノードを除去する前に、このスーパーノード上のPodをすべて他のスーパーノード上(DaemonSetの管理するPodを除く)にドレインする必要があります。ドレインが完了してからでなければ除去操作は実行できず、これに従わない場合はノードの除去に失敗します。具体的な操作については次の手順をご参照ください。
1. TKEコンソールにログインし、左側ナビゲーションバーのクラスターを選択します。
2. コンテナネットワークを変更したいクラスターIDをクリックし、クラスター基本情報ページに進みます。
3. 左側のスーパーノードを選択し、スーパーノードページでノード名の右側のその他 > ドレインを選択します。下の図をご覧ください。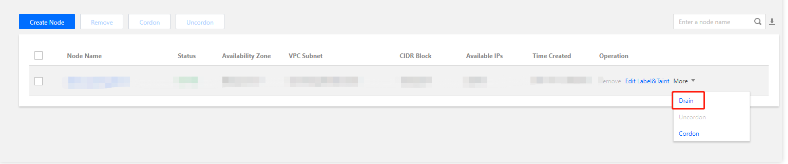
4. ノードのドレインページでノード情報を確認し、OKをクリックします。ドレイン後、このスーパーノードのステータスは「ロック済み」に変更され、このノード上へはPodをスケジューリングできなくなります。
注意
ドレインを行うとPodが再構築されますので、操作は慎重に行ってください。
5. スーパーノードページでノード名の右側の除去を選択します。
6. ノードの削除ページでOKをクリックすると、ノードの削除操作が完了します。
サブネットIPの枯渇によってPodのスケジューリングに失敗した場合はどうすればよいですか。
コンテナネットワークのサブネットIPの枯渇によってPodのスケジューリング失敗が起こった場合、ノードのログで下図のような2つのイベントが観察されます。
イベント1:
イベント2:

TKEコンソールで、またはコマンドラインで次のコマンドを実行することで、スーパーノードのYAMLを照会できます。
kubectl get nodes -oyaml
返された結果は次の通りです:
spec:taints:- effect: NoSchedulekey: node.kubernetes.io/network-unavailabletimeAdded: "2021-04-20T07:00:16Z"
- lastHeartbeatTime: "2021-04-20T07:55:28Z"lastTransitionTime: "2021-04-20T07:00:16Z"message: eklet node has insufficient IP available of subnet subnet-bok73g4creason: EKLetHasInsufficientSubnetIPstatus: "True"type: NetworkUnavailable
この場合、PodはコンテナネットワークのサブネットIPが枯渇したことによってスケジューリングに失敗したことがわかります。上記の状況が発生した場合は、新しいスーパーノードを作成してサブネットを追加し、それによってクラスターPodの利用可能なネットワークセグメントを拡張する必要があります。スーパーノードの新規作成操作については、スーパーノードの新規作成をご参照ください。
TKE Serverlessのセキュリティグループの使用ガイドおよび説明にはどのようなものがありますか。
ServerlessクラスターPodを作成する際にセキュリティグループを指定しない場合は、defaultセキュリティグループを使用します。もしくは
Annotation eks.tke.cloud.tencent.com/security-group-id : セキュリティグループIDによってPodにセキュリティグループを指定することもできます。同一のリージョンにこのセキュリティグループIDがすでに存在することを確認してください。このAnnotationの詳細な説明については、Annotationの説明をご参照ください。コンテナ終了のメッセージを設定するにはどうすればよいですか。
KubernetesはterminationMessagePathによってコンテナ終了のメッセージソースを設定することができます。コンテナ終了の際、KubernetesはコンテナのterminationMessagePathフィールド内で指定された終了メッセージファイルから終了メッセージを検索し、この内容を使用してコンテナの終了メッセージを入力します。メッセージのデフォルト値は
/dev/termination-logです。また、コンテナのterminationMessagePolicyフィールドを設定することで、コンテナ終了メッセージをさらにカスタマイズすることもできます。このフィールドのデフォルト値は
File、すなわち終了メッセージファイルからのみ終了メッセージを検索します。ニーズに応じてFallbackToLogsOnErrorに設定することができ、これはコンテナがエラーによって終了した場合、終了メッセージファイルが空であれば、コンテナログを使用して最後の一部分の内容を終了メッセージとして出力できるものです。サンプルコードは次のとおりです:
apiVersion: apps/v1beta2kind: Deploymentmetadata:name: nginxspec:containers:- image: nginximagePullPolicy: Alwaysname: nginxresources:limits:cpu: 500mmemory: 1Girequests:cpu: 250mmemory: 256MiterminationMessagePath: /dev/termination-logterminationMessagePolicy: FallbackToLogsOnError
上記の設定により、コンテナがエラーによって終了し、かつメッセージファイルが空の場合、Get Podがstderrの出力を発見するとcontainerStatusesに表示します。
Hostパラメータを使用するにはどうすればよいですか。
Serverlessクラスターを使用する際は次の事項に注意する必要があります。
Serverlessクラスターにはノードはありませんが、Hostpath、Hostnetwork: true、DnsPolicy: ClusterFirstWithHostNetなどのHost関連パラメータとの間に互換性があります。ノードがないため、ご使用の際は、これらのパラメータが提供する機能が標準のk8sと完全には一致しない点にご注意ください。
例えば、Hostpathを使用してデータを共有したい場合でも、同一のスーパーノード上にスケジューリングされた2つのPodには異なるサブマシンのHostpathが表示されます。また、Podの再構築後はHostpathのファイルも同時に削除されます。
CFS/NFSをマウントするにはどうすればよいですか。
Serverlessクラスターでは、Tencent CloudのCloud File Storage(CFS)を使用するほか、ご自身で構築したNFSファイルストレージを使用して、Volume形式でPod上にマウントすることで、永続的なデータストレージを実装することが可能です。PodにCFS/NFSをマウントするYAMLの例は次のとおりです。
apiVersion: v1kind: Podmetadata:name: test-pdspec:containers:- image: k8s.gcr.io/test-webservername: test-containervolumeMounts:- mountPath: /cachename: cache-volumevolumes:- name: nfsnfs:path: /dirserver: 127.0.0.1---
spec.volumes:データボリューム名、タイプ、データボリュームのパラメータを設定します。
spec.volumes.nfs:NFS/CFSディスクを設定します。
spec.containers.volumeMounts:データボリュームのPod上のマウントポイントを設定します。
イメージの再利用によってコンテナの起動を高速化するにはどうすればよいですか。
TKE Serverlessは、次回同じイメージを使用してコンテナを起動する際に起動を高速化できるよう、コンテナイメージのキャッシュをサポートしています。
再利用の条件:
1. 同一のワークロードのPodの場合、キャッシュ時間内に同一のアベイラビリティーゾーン(Zone)でPodが作成され、かつ破棄された場合、新しく作成されるPodはデフォルトで同じイメージを再度プルしません。
2. 異なるワークロード(Deployment、Statefulset、Jobを含む)のPodでイメージを再利用したい場合は、次のannotationを使用できます。
eks.tke.cloud.tencent.com/cbs-reuse-key
同一ユーザーのアカウントで、同一のannotation valueを持つPodは、キャッシュ時間内において可能な限り起動イメージを再利用します。annntation valueにイメージ名
eks.tke.cloud.tencent.com/cbs-reuse-key: "image-name"を入力することをお勧めします。キャッシュ時間:2時間。
イメージの再利用に異常が発生した場合はどうすればよいですか。
イメージ再利用機能を有効にしている場合、Pod作成の際に
$kubectl describe podで次のようなエラーが表示される場合があります。no space left on device: unknownWarning FreeDiskSpaceFailed 26m eklet, eklet-subnet-xxx failed to garbage collect required amount of images. Wanted to free 4220828057 bytes, but freed 3889267064 bytes復旧方法:
操作は何も行う必要はありません。数分待つとPodは自動的にrunningとなります。
原因:
no space left on device: unknown
Podがデフォルトでシステムディスクを再利用する際、システムディスク内にもともとあったイメージでディスク容量が一杯の場合、ディスクに新しいイメージをダウンロードする容量がないため、「no space left on device: unknown」というエラーが表示されます。TKE Serverlessはイメージを定期的に回収するメカニズムをサポートしており、ディスク容量が一杯の場合、システムディスク内にある余分なイメージを自動的に削除し、現在のディスクに利用可能な容量を作ります。(数分かかります)Warning FreeDiskSpaceFailed 26m eklet, eklet-subnet-xxx failed to garbage collect required amount of images. Wanted to free 4220828057 bytes, but freed 3889267064 bytes
このログは、現在のPodにイメージをダウンロードするために4220828057の容量が必要であるのに、現時点で3889267064の容量のデータしかクリアできていないことを表しています。このeventが生成された理由は、ディスク上に複数あるイメージのうち、現時点でその一部しかクリアされていないためです。TKE Serverlessの時間指定イメージ回収メカニズムは、新しいイメージのプルに成功するまでイメージのクリーンアップを継続します。自作したnfsをマウントした際、イベントOperation not permittedが表示されましたが、どうすればよいですか。
自作したnfsを使用して永続ストレージを実装する場合、接続の際にイベントOperation not permittedが表示されます。自作nfsの/etc/exportsファイルを変更し、/<path><ip-range>(rw,insecure)パラメータを追加する必要があります。次に例を示します。
/data/ 10.0.0.0/16(rw,insecure)
Podのディスク容量が一杯になりました(ImageGCFailed)が、どうすればよいですか。
TKE ServerlessのPodは、デフォルトで20Gの利用可能なシステムディスク容量を無料で提供しています。システムディスク容量が一杯になった場合は次の方法で対処できます。
1. 使用していないコンテナイメージをクリーンアップする
使用容量が80%に達すると、TKE Serverlessバックエンドはコンテナイメージの回収フローをトリガーし、使用していないコンテナイメージを回収してディスク容量を解放しようと試みます。容量をまったく解放できなかった場合は、ImageGCFailed: failed to garbage collect required amount of imagesというイベントが表示され、ディスク容量が不足していることをユーザーに通知します。
ディスク容量不足には一般的に次のような原因があります。
業務に大量の一時的な出力があった。duコマンドによって確認できます。
業務が削除済みのファイルディスクリプタを保有していて、ディスク容量が解放されない。lsofコマンドによって確認できます。
業務上、コンテナイメージ回収の閾値を調整したい場合は、次のannotationを使用できます。
eks.tke.cloud.tencent.com/image-gc-high-threshold: "80"
2. 終了したコンテナをクリーンアップする
業務でインプレースアップグレードを実施した場合、またはコンテナが異常終了したことがある場合、終了したコンテナはそのまま維持され、ディスク容量が85%に達しないとクリーンアップされません。クリーンアップの閾値は次のAnnotationを使用して調整できます。
eks.tke.cloud.tencent.com/container-gc-threshold: "85"
終了したコンテナを自動的にクリーンアップしたくない場合(終了情報のさらなるトラブルシューティングが必要な場合など)は、次のAnnotationによってコンテナの自動クリーンアップを無効化することができます。ただし、ディスク容量が自動的に解放されないという副作用があります。
eks.tke.cloud.tencent.com/must-keep-last-container: "true"
説明
この機能のリリース日は2021-09-15のため、これ以前に作成されたPodにはこの機能はありません。
3. ディスク使用量の大きいPodを再起動する
業務上、コンテナ内のシステムディスク使用量があるパーセンテージを超えるとそのままPodを再起動させたい場合は、次のAnnotationによって設定できます。
eks.tke.cloud.tencent.com/pod-eviction-threshold: "85"
Podの再起動のみを行い、サブマシンの再構築は行いません。終了と起動の際はどちらも正常なgracestop、prestop、ヘルスチェックを行います。
説明
この機能のリリース日は2022-04-27のため、これ以前に作成されたPodでこの機能を有効化する場合は、Podの再構築が必要です。
ポート9100の問題
TKE ServerlessのPodはデフォルトでポート9100によってモニタリングデータを外部に公開します。ユーザーは次のコマンドを実行し、9100/metricsにアクセスしてデータを取得できます。
すべてのメトリクスを取得する場合:
curl -g "http://<pod-ip>:9100/metrics"
大きなクラスターではipvsメトリクスを除外することをお勧めします。
curl -g "http://<pod-ip>:9100/metrics?collect[]=ipvs"
業務自体の必要性によりポート9100をリッスンする場合は、Podの作成の際に9100以外のポートを使用してモニタリングデータを収集するようにすることで、業務のポート9100との競合を避けることができます。設定方法は次のとおりです。
eks.tke.cloud.tencent.com/metrics-port: "9110"
モニタリング用の公開ポートを変更しなかった場合、業務がポート9100を直接リッスンするため、TKE Serverlessの新しいネットワークソリューションではユーザーに対し、ポート9100がすでに使用されているというエラーが通知されます。
listen() to 0.0.0.0:9100, backlog 511 failed (1: Operation not permitted)
エラー通知が表示された場合は、PodにAnnotation:
metrics-portを追加してモニタリングポートを変更し、Podを再構築する必要があります。注意
Podがパブリックeipを持っている場合はセキュリティグループを設定する必要があります。ポート9100の問題に注意し、必要なポートを許可してください。
フィードバック