TDMQ for CKafka (CKafka) is a high-throughput scalable distributed messaging system that is fully compatible with Apache Kafka API 0.9–2.8 Based on the publish/subscribe pattern, CKafka allows producers and consumers to interact asynchronously without waiting for each other through message decoupling. It has many strengths, such as high availability, data compression, and offline/real-time data processing, making it suitable for scenarios such as compressed log collection, monitoring data aggregation, and stream data integration.
TDMQ for CKafka
Distributed high-throughput messaging system for log collection and data aggregation


Overview
Benefits

Open-Source Component Compatibility
Feature 100% compatibility with Apache Kafka v0.9–2.8, work well with upstream and downstream open-source components such as Kafka Streams and Kafka Connect, completely eliminating the costs associated with cloudification.

Upstream and Downstream Ecosystems
Connect to over 15 Tencent Cloud products, including TencentDB, ES, COS, TKE, Oceanus and CLS, thus deploying data flow linkage quickly at lower costs.

High Reliability
Surpass the productivity of open-source solutions and provide a distributed deployment to ensure cluster stability.

High Scalability
Support automatic horizontal scaling of clusters and seamless upgrade of instances without affecting the user experience.

Business Security
Isolate tenants at the network level among different accounts, and support CAM for management streams and SASL for data streams to enhance security.

Unified OPS Monitoring
Provide a comprehensive set of Ops services, including multidimensional monitoring and alarm services such as tenant isolation, access control, message retention query, and consumer details query.
Features
Message Decoupling
CKafka effectively decouples the relationship between message producer and consumer, allowing you to independently scale or modify the production/consumption processing procedure as long as they follow the same API constraints.
Peak Shifting
CKafka can withstand access traffic surges instead of completely crashing due to sudden overwhelming requests, which effectively boosts system robustness.
Sequential Read/Write
CKafka can guarantee the order of messages in a partition. Just like most message queue services, it can also ensure that data is processed in order, greatly improving disk efficiency.
Async Communication
In the scenario where the business does not need to process messages immediately, CKafka provides an async message processing mechanism, that is, when the traffic is high, messages will be put into the queue only and processed after the traffic drops, which significantly relieves the system pressure.
Scenarios
Log Analysis System
Streaming Data Processing Platform
Message storage
Data reporting and query
Database change subscription
Data integration
Data ETL and dumping
CKafka can work with EMR to create a complete log analysis system. The client-side agent collects logs and aggregates them to CKafka, where the data is computed and consumed repeatedly by the backend big data suite, such as Spark. The original logs are then cleaned, stored, or graphically displayed.

CKafka can work with Stream Compute Service (SCS) to process data in a real-time or offline manner and detect exceptions in various scenarios:
- Analyze real-time data for exception detection to troubleshoot system issues.
- Store historical consumption data and analyze it offline for secondary processing and trend report generation.

With SCF integrated, CKafka supports customized data processing to meet your message dumping requirements in different scenarios such as log consumption, microservices, and big data analysis.

CKafka Connector supports a wide range of data reporting scenarios, such as operation behavior analysis on mobile applications, bug log reporting on frontend pages, and business data reporting. In general, reported data needs to be dumped to downstream storage and analysis systems like Elasticsearch and HDFS for processing. Traditionally, this requires setting up a server, purchasing a storage system, and performing data integration, processing, and dumping while customizing code along the way. This is cumbersome and costly in terms of long-term system Ops.
By going SaaS, CKafka Connector allows you to create a complete linkage in just two steps: configure in the console and report data in the SDK. It is designed to be serverless and pay-as-you-go, removing the need to estimate the capacity in advance and saving costs in development and use.

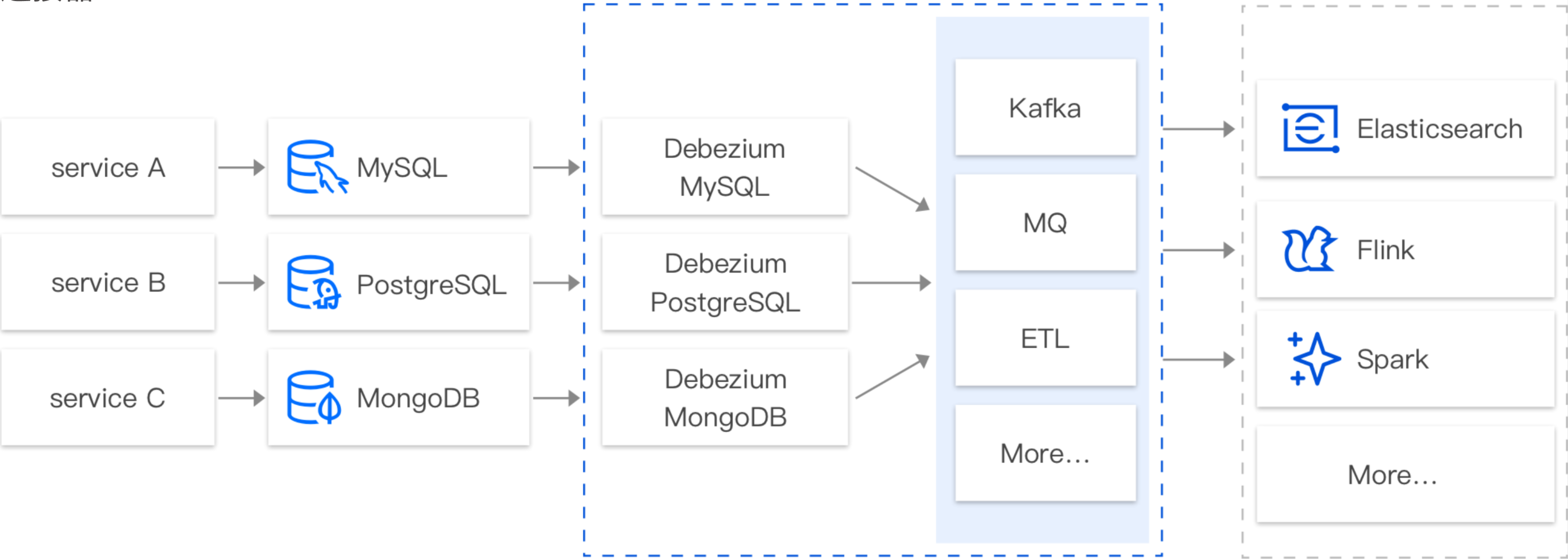
Using the CDC mechanism, CKafka Connector can subscribe to data changes in various databases such as binlog of TencentDB for MySQL, change stream of TencentDB for MongoDB, and row-level change of TencentDB for PostgreSQL/SQL Server. In real-world business scenarios, you often need to subscribe to MySQL binlogs to get the change history (INSERT, UPDATE, DELETE, DDL, DML, etc.), as well as perform business logic processing such as query, failure recovery, and analysis.
CDC to subscribe to data changes. These components are labor-intensive to build and maintain. You also need to have a complete monitoring system in place to ensure that the subscription component runs smoothly.
In contrast, CKafka Connector provides SaaS components that enable data subscription, processing, and dumping through simple UI configurations.
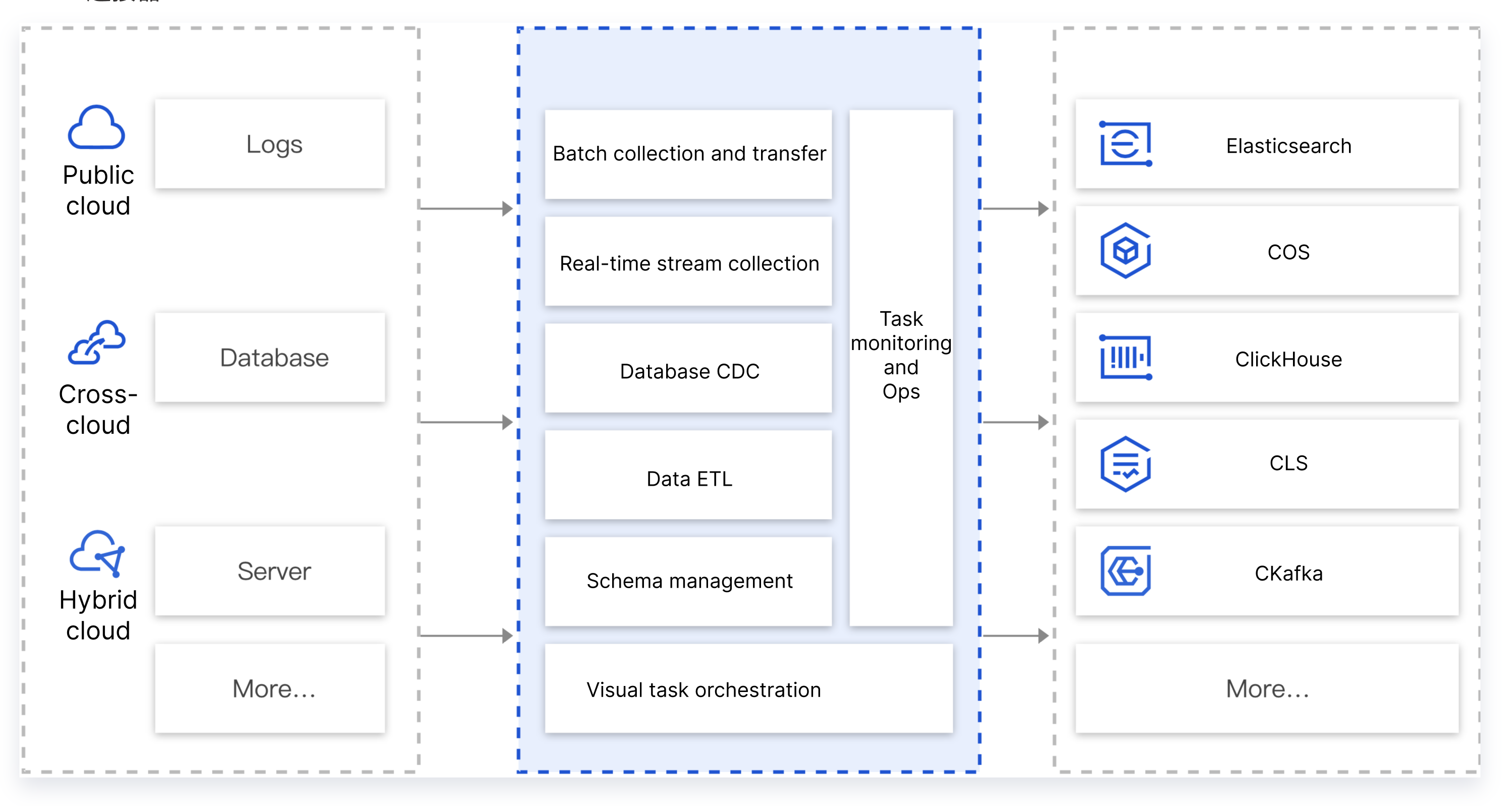
CKafka Connector can integrate data from different sources (database, middleware, log, application system, etc.) in different environments (Tencent public cloud, self-built IDC, cross-cloud environment, hybrid cloud, etc.) to CKafka for convenient processing and distribution. In practice, database data, business client data from an application, and log data often need to be aggregated into a message queue for unified dumping, analysis, and processing after ETL.
CKafka Connector offers robust data aggregation, storage, processing, and dumping capabilities. In short, it can easily integrate data by connecting different data sources to downstream data targets.
In some use cases, data from a cache layer component such as Kafka needs to be stored in a downstream system such as CKafka, ES, or COS after ETL. The common practice is to process the data with Logstash, Flink, or custom code and monitor those components to ensure their stable operation. However, in order to operate and maintain the components, it requires learning their syntax, specifications, and technical principles. This incurs significant costs which are unnecessary if all you need is simple data processing.
CKafka Connector comes with lightweight, UI-based, data ETL and dumping capabilities that are simple to configure, making it easier for you to process and dump data to downstream storage systems.
Pricing
CKafka supports two billing modes: pay-as-you-go and monthly subscription. For more information, see Billing Overview.