
优势介绍
为什么选择腾讯云自动语音识别

价格低
腾讯云ASR提供行业内有竞争力的价格体系。
价格低
腾讯云ASR提供行业内有竞争力的价格体系。

语种多
已经支持中文、英文,后续将持续开放其他语种和语言的识别能力。
语种多
已经支持中文、英文,后续将持续开放其他语种和语言的识别能力。
效果好
字准率97%处于业界领先水平,与微信、王者荣耀的语音转文字使用一套服务,效果一样好。
效果好
字准率97%处于业界领先水平,与微信、王者荣耀的语音转文字使用一套服务,效果一样好。

算法强大
基于创新网络结构 TLC-BLSTM,利用 ATTENTION 机制有效地对语音信号进行建模,通过 Teacher-Student 方式提升系统鲁棒性,对通用以及垂直领域下场景有领先业界的识别精度和效率。
算法强大
基于创新网络结构 TLC-BLSTM,利用 ATTENTION 机制有效地对语音信号进行建模,通过 Teacher-Student 方式提升系统鲁棒性,对通用以及垂直领域下场景有领先业界的识别精度和效率。

自助提升准确率
针对垂直领域,上传词表或句子即可完成语言模型的自动优化,借助自训练平台,不懂算法也可轻松实现定制化模型,进一步提升识别准确率。
自助提升准确率
针对垂直领域,上传词表或句子即可完成语言模型的自动优化,借助自训练平台,不懂算法也可轻松实现定制化模型,进一步提升识别准确率。

支持场景丰富
经过内部微信、腾讯视频、王者荣耀等大流量产品的充分验证,在互联网、金融、教育等领域,基于海量数据实现分场景优化,积累了多行业的最佳实践。
支持场景丰富
经过内部微信、腾讯视频、王者荣耀等大流量产品的充分验证,在互联网、金融、教育等领域,基于海量数据实现分场景优化,积累了多行业的最佳实践。
应用场景
它在各种商业场景中的运作方式
传统语音电话质检严重受限于人的工作效率和人力成本,只能抽检不能全检,难以评估客服的真实工作质量。语音识别将电话语音识别为文本,再实时对文本进行分析,识别不符合规范的服务通话记录。大幅提升呼叫中心工作质量管控能力,完成人力不可能完成的超大规模电话质检工作,提升呼叫中心人员的服务质量。

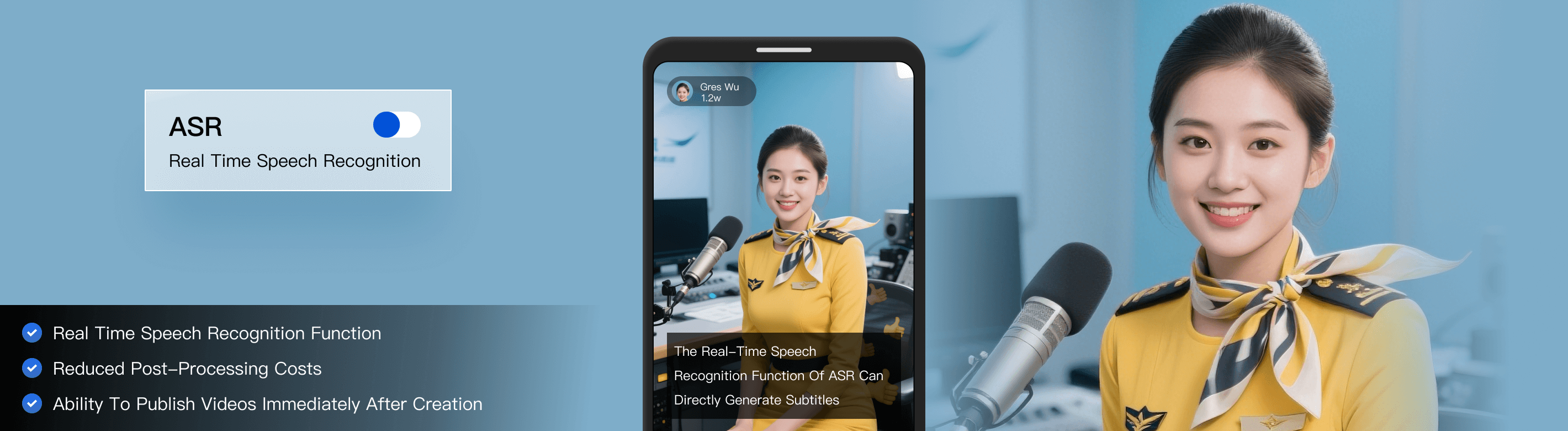
在拍摄 Vlog 的场景中,用户会边拍视频边说话;拍完视频还需要二次编辑,手动输入字幕才能将视频发布。通过实时语音识别,实现了用户边拍边说,将语音内容直接显示在视频上。大大减少了用户后期处理的成本,让用户拍摄后即可发布。
在直播、音频分享等平台,有海量音视频需要理解,用来做质检审核或者标签推荐,基于人力很难实现。实时语音识别可将视频中的音频(流)通过音视频专属模型进行转写,可满足多种输入、不同时延的需求。助力快速对平台海量音视频进行理解,极大降低人力成本,快速实现质检审核或精准推荐。
