Multi-Level Service Synchronized Horizontal Scaling (Workload Triggers)
Download
Modo Foco
Tamanho da Fonte
Workload Triggers
Kubernetes-based Event-Driven Autoscaler (KEDA) supports Kubernetes Workload triggers, enabling scaling based on the number of Pods in one or more workloads. This is very useful in multi-level service call scenarios. For details, please refer to KEDA Scalers: Kubernetes Workload.
Use Cases
Multi-level Service Simultaneous Scaling
The picture shows multi-level microservice call:
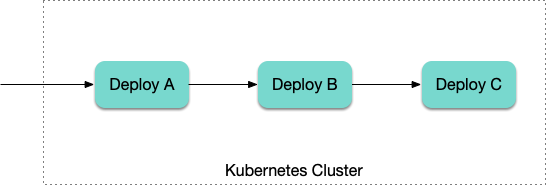
The services A, B, and C usually have a fixed proportional quantity.
If the pressure on A suddenly increases, forcing a scale-out, B and C can also scale out almost simultaneously with A by using KEDA's Kubernetes Workload triggers, without waiting for pressure to propagate slowly.
First, configure the scale-out for A, which can be based on CPU and memory pressure. For example:
apiVersion: keda.sh/v1alpha1kind: ScaledObjectmetadata:name: aspec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: apollingInterval: 15minReplicaCount: 10maxReplicaCount: 1000triggers:- type: memorymetricType: Utilizationmetadata:value: "60"- type: cpumetricType: Utilizationmetadata:value: "60"
Then, configure the scale-out for B and C, assuming a fixed ratio of A:B:C = 3:3:2. For example:
apiVersion: keda.sh/v1alpha1kind: ScaledObjectmetadata:name: bspec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: bpollingInterval: 15minReplicaCount: 10maxReplicaCount: 1000triggers:- type: kubernetes-workloadmetadata:podSelector: 'app=a' # Select service Avalue: '1' # A/B=3/3=1
apiVersion: keda.sh/v1alpha1kind: ScaledObjectmetadata:name: cspec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: cpollingInterval: 15minReplicaCount: 3maxReplicaCount: 340triggers:- type: kubernetes-workloadmetadata:podSelector: 'app=a' # Select service Avalue: '3' # A/C=3/2=1.5
With the above configuration, when the pressure on A increases, A, B, and C will scale out almost simultaneously without waiting for the pressure to propagate step by step. This allows for faster adaptation to pressure changes, improving system elasticity and performance.
Ajuda e Suporte
Esta página foi útil?
Você também pode entrar em contato com a Equipe de vendas ou Enviar um tíquete em caso de ajuda.
comentários