SuperSQL 引擎说明
下载
聚焦模式
字号
DLC 的数据引擎是 DLC 的数据分析计算服务的基础,用户在 DLC 进行的所有计算都需要使用数据引擎。根据用户的使用场景不同,可选择共享引擎或独享引擎。
说明:
presto 引擎已下线,仅供存量用户使用。
共享引擎
共享引擎(public-engine)是 DLC 服务开通后自带的数据引擎,适合分析频率低、计算数据量较小的场景使用。用户无需配置、管理资源,按任务扫描量计费(具体资费参见 计费概述 ),不运行则不计费,具有高灵活、高可用的特点。
DLC 为 Serverless 架构,在一段时间内首次执行任务需要调度数据引擎,等待时间可能稍长。
独享引擎
按量计费:适合分析数据具有周期性,需根据业务峰谷进行弹性伸缩的用户,具有高灵活、高稳定性的特点,按 CU 使用量付费。
包年包月:适合长期大量稳定的数据分析需求,可根据业务峰谷进行弹性伸缩,无需等待资源拉起,随时可用,按集群规格按月付费。支持弹性伸缩的情况下,系统将根据弹性扩缩规则进行集群弹性扩缩容,弹性扩容集群按 CU 使用量计费。
计算引擎类型
根据不同的使用场景,独享引擎可以选择不同的计算引擎来应对不同场景。
SparkSQL:适用于稳定高效的离线 SQL 任务。
Spark 作业:适用于 Spark 原生的流式/批式数据作业处理。
Presto:适用于敏捷、快速的交互式查询分析。
注意:
不同计算引擎类型不影响独享引擎计费单价。
引擎弹性规则
弹性规则分为按负载弹性和按时间弹性两种,二者相互独立且支持用户同时设置。在定时弹性规则生效的时间段内,系统优先执行按时间弹性规则;其余时间则按照“按负载弹性”规则进行弹性调整。
按负载弹性
集群数量指的是引擎中常驻的集群数目,集群数目 + 弹性集群数量 = 引擎弹性时能达到的最大集群数目。
基本规则:当弹性集群数量大于0时,才会产生引擎扩缩容。
扩容规则:当数据引擎目前存在的排队任务>空闲的并发容量,任务排队时间超过任务排队时间上限,且没有正在初始化的集群时,系统将会按照配置规则对数据引擎进行扩容。
缩容规则:当数据引擎目前的集群数>常驻的集群数目时,集群整体平均负载低于20%且有集群处于闲置状态时,系统将会对数据引擎进行缩容。
如下图所示:购买时配置了集群数为2个、弹性集群数为3个、任务排队时间上限为5分钟。集群任务高并发时,排队任务超过2个且排队时间超过5分钟,则系统将对数据引擎进行扩容,缓解任务排队情况。扩容成功一段时间后,集群任务排队情况得到缓解,存在集群闲置且负载低,系统将对数据引擎进行缩容。
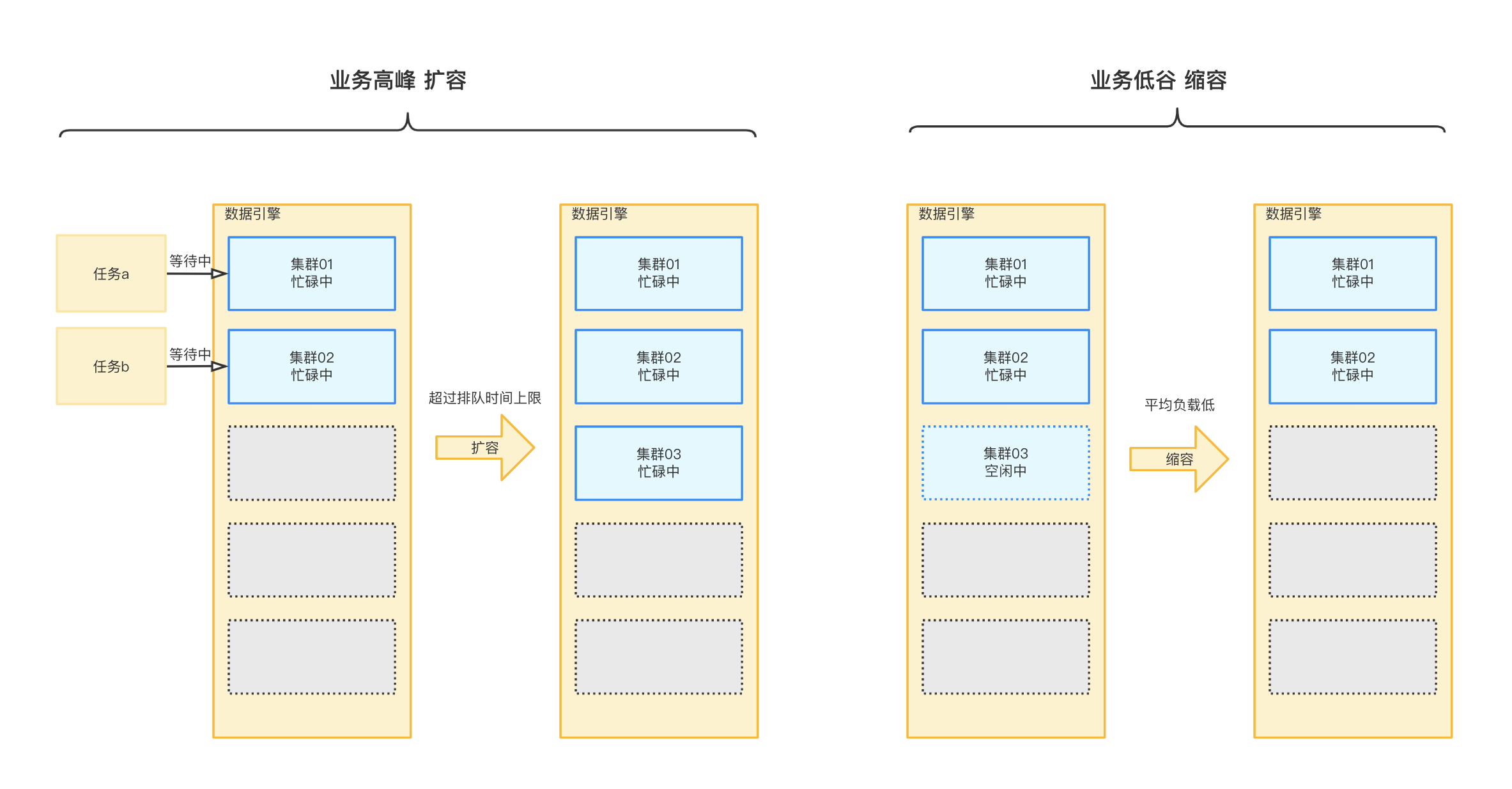
弹性扩缩容情况下,数据引擎的集群数量不会少于配置的集群数,不会大于配置的集群数和弹性集群数总和。
例如:购买时配置了集群数为2个,弹性集群数为3个,则弹性扩容后,集群数不会超过5个,弹性缩容后,集群数不会少于2个。
注意:
按量付费集群若无需使用,可对集群进行挂起操作,避免资源浪费。
按时间弹性
注意事项
1. 按时间弹性功能仅支持 SuperSQL Presto 和 Spark SQL 引擎。
2. 用户不可同时启用按时间弹性功能与集群定时启停功能。
配置路径
导航至:资源管理 > SuperSQL引擎 > 选中目标引擎 > 点击引擎名称进入引擎详情页 > 配置信息 > 更多 > 规模配置变更 > 弹性规则 > 启用定时弹性,即可进行按时间弹性配置。
配置完成并确认变更后,设置将立即生效。
配置说明
1. 执行类型
1.1 执行一次
用户可自助选择弹性时间段生效的时区。
生效时间段总时长不超过 24 小时。
弹性集群数量需填写最小值和最大值:
弹性时间段开始时,集群会根据最小数量进行扩容。
弹性时间段内,系统可根据负载动态扩容至最大数量。
常驻集群与弹性集群最大数量之和不得超过 10 个。
任务排队时间上限:
配置任务排队的最长等待时间。
可设置为 0,表示一旦产生排队即触发弹性扩容。
当排队时间超过配置值后,系统将启动弹性资源(启动时间视资源数量而定),触发集群弹性扩容。
1.2 重复执行
支持在同一执行频率下添加多条弹性计划,且各计划时间段不可重叠。
弹性计划将按照添加顺序依次执行。
1.2.1 执行频率支持:
每天
生效时间段总时长不超过 24 小时。
若结束时间早于开始时间,视为跨天执行。
每周
用户可选择具体的周几,支持多选。
每月
用户可选择具体日期,支持多选。
选择“月末”时,表示每月最后一天执行(无论当月天数多少)。
引擎运行状态
集群根据当前运行情况,分为启动中、运行、暂停、暂停中、变配中、隔离、隔离中、恢复中八个状态。
启动中:该集群资源正在被拉起,按量计费的独享引擎此时不计费。启动中的集群无法被数据计算选中使用。
运行:该集群正在运行,可被数据计算选中使用。
暂停:该集群暂停使用,无法被数据计算选中使用。
暂停中:该集群正在切换为暂停状态,会影响正在运行的任务,无法被数据计算选中使用。
变配中:该集群正在进行配置变更,配置变更期间将无法被数据计算使用。
隔离:由于账号欠费导致的集群被隔离,无法被数据计算选中使用。
隔离中:由于账号欠费导致,集群正在切换为隔离状态,会影响正在运行的任务,无法被数据计算选中使用。
恢复中:账号通过充值不再欠费后,集群由隔离状态恢复到运行状态的过程,无法被数据计算选中使用。
文档反馈