存储引擎架构与数据模型
下载
聚焦模式
字号
本文档介绍 TDSQL Boundless 的存储引擎 TDStore 架构,以及核心的三级元数据模型和 KV 编码机制。
TDStore 存储引擎架构
TDStore 是 TDSQL Boundless 的核心存储引擎,它在 RocksDB 基础上构建了数据分片模块和分布式事务模块,下层增加了 Raft 共识协议模块,实现了高扩展、高可用、分布式事务、数据均衡调度、多副本强一致的分布式 KV 存储引擎。
整体架构
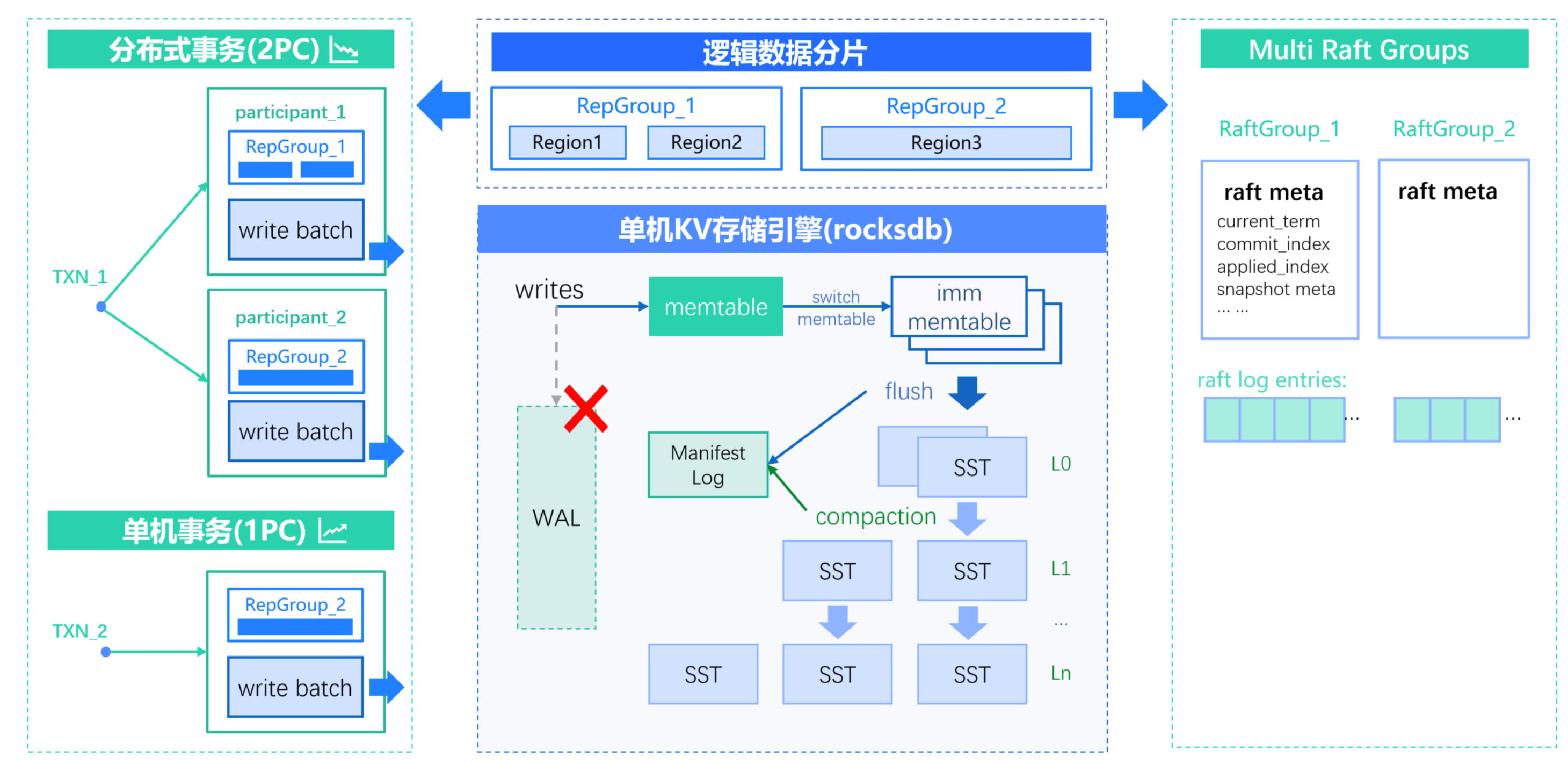
TDStore 存储引擎包含以下核心组件:
组件 | 功能 | 特性 |
RocksDB | 底层 KV 存储 | LSM-Tree 结构、高压缩比 |
Multi-Raft | 多副本容灾 | 数据强一致、高可用 |
分片模块 | 数据分片管理 | 灵活调度、亲和性支持 |
事务模块 | 分布式事务 | 2PC 下沉、协商式提交 |
分层说明
单机 KV 存储引擎(RocksDB)
接收计算层传递的 KV 请求
使用 LSM-Tree 结构存储数据
逻辑数据分片
支持以数据分片为单位进行调度迁移
实现数据在集群节点间的灵活调度
分布式事务
维护分布式事务在各数据分片上的参与者上下文以及事务状态等信息
支持将相关性数据调度至同一数据分片
多副本容灾层(Multi-Raft)
把每个数据分片以 Raft Group 方式在不同 TDStore 节点上创建多副本
每个数据分片作为独立日志流进行同步
低成本海量存储
TDStore 存储层基于 LSM-Tree + SSTable 结构存放和管理数据:
极高压缩率:有效降低海量数据的存储成本
PB 级支持:单实例可支撑 PB 级别的存储量
多级压缩:在每一层数据都提供压缩算法
三级元数据模型
说明:
核心概念:TDSQL Boundless 通过三级元数据模型实现数据的精细化管理与智能调度。
面对分布式架构三大挑战:感知缺失、调度受限、规则固化,TDSQL Boundless 通过三级元数据模型破局:
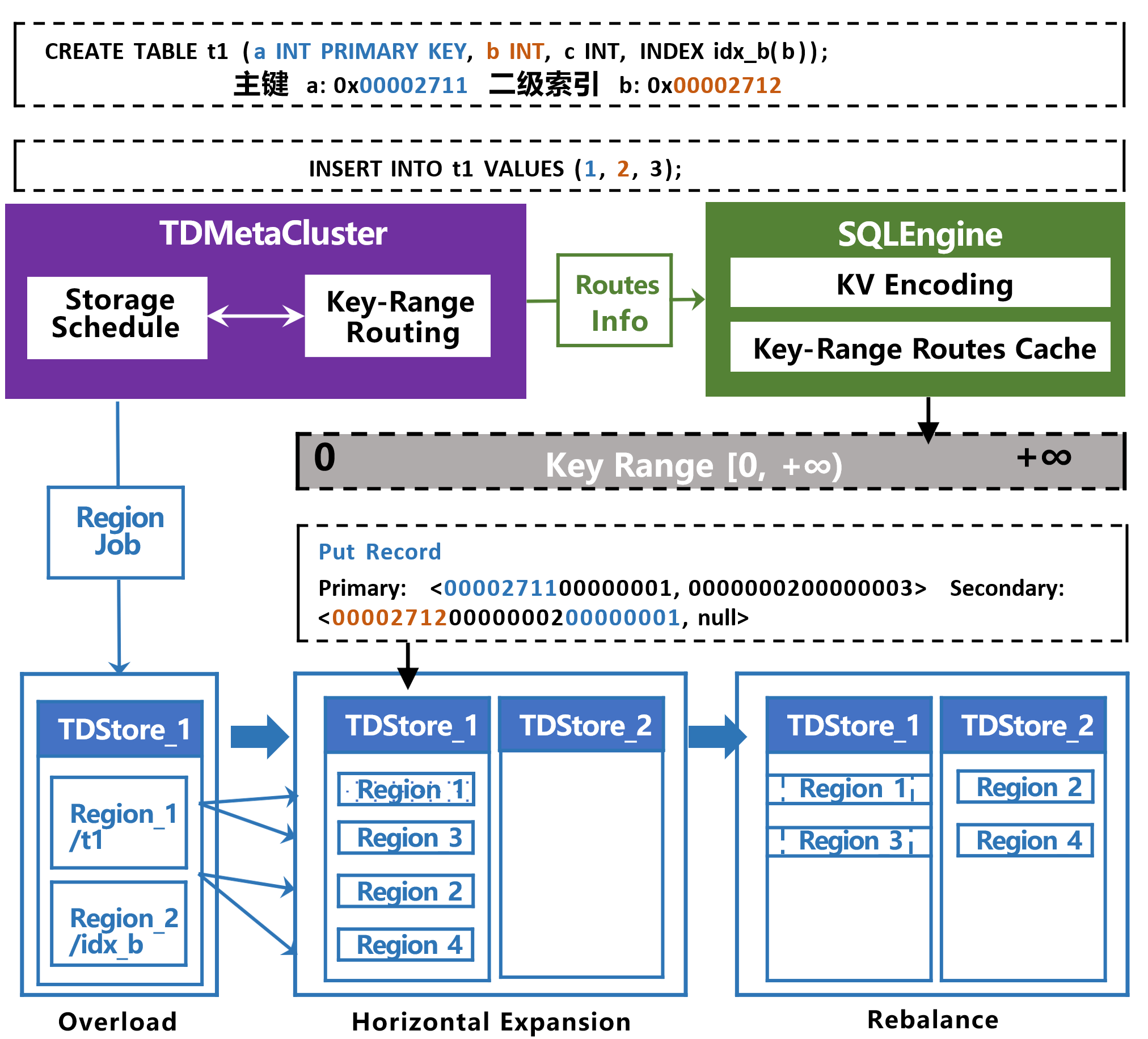
DataObject(数据对象)
定义:表、索引、分区、自增值等逻辑层面的概念抽象。
层级结构:
L0级:Database(数据库)
L1级:Table(表),隶属于某个 Database
L2级:Index/Partition(索引或分区),隶属于某个 Table
作用:
定义不同类型的数据结构
用于拓扑感知数据亲和性关系
记录表结构及二级索引等元数据
示例:对象 ID
10010 可明确表示:数据库(id:1) 中分区表(id:1001) 的一级分区(id:1003) 下的一个二级索引。Replication Group(复制组)
定义:基于 Raft 协议的物理存储单元,一主 N 备,保证数据一致性。
角色类型:
角色 | 说明 |
Leader | 主副本,处理所有读写请求 |
Follower | 从副本,同步数据并可参与选举 |
Learner | 学习者,仅同步数据不参与选举 |
Witness | 见证者,参与选举但不存储数据 |
特点:
对应一个 Raft 日志流
管理多个不同 Region 的数据
支持数据亲和性调度
Region(数据分片)
定义:一段连续范围的 Key Range,是数据物理存储的最小单元。
容量标准:
最大256MB
或最多10万行数据
规则:
一个 RG 可以包含多个 Region
每个 Region 承载某个 DataObject 的一部分实际数据
单个分片最多包含一个数据对象的数据
KV 编码与数据空间
编码规则
在 TDSQL Boundless 中,所有数据都编码为 Key-Value 形式。编码后的 Key 具有 mem-comparable(内存可比较)特性。
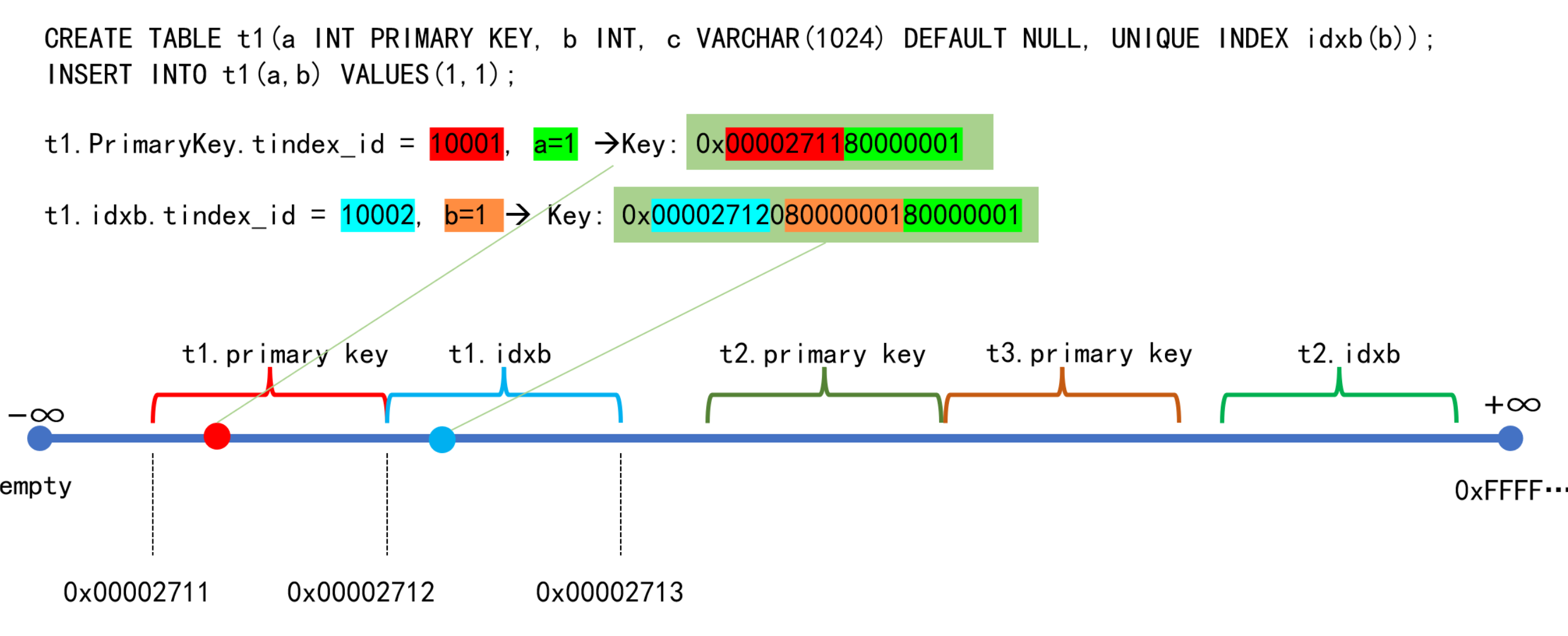
编码特性:
系统为每个索引分配全局递增的唯一 ID
同一索引的所有数据共享相同前缀
编码后的数据在逻辑上连续
数据分片和复制组
在逻辑数据空间中,每个 Key 对应一个离散的点,但物理上每个 Key-Value 都需要存储空间。当数据量增大时,单个节点无法承载所有数据,因此数据被分割成多个分片(Region)。
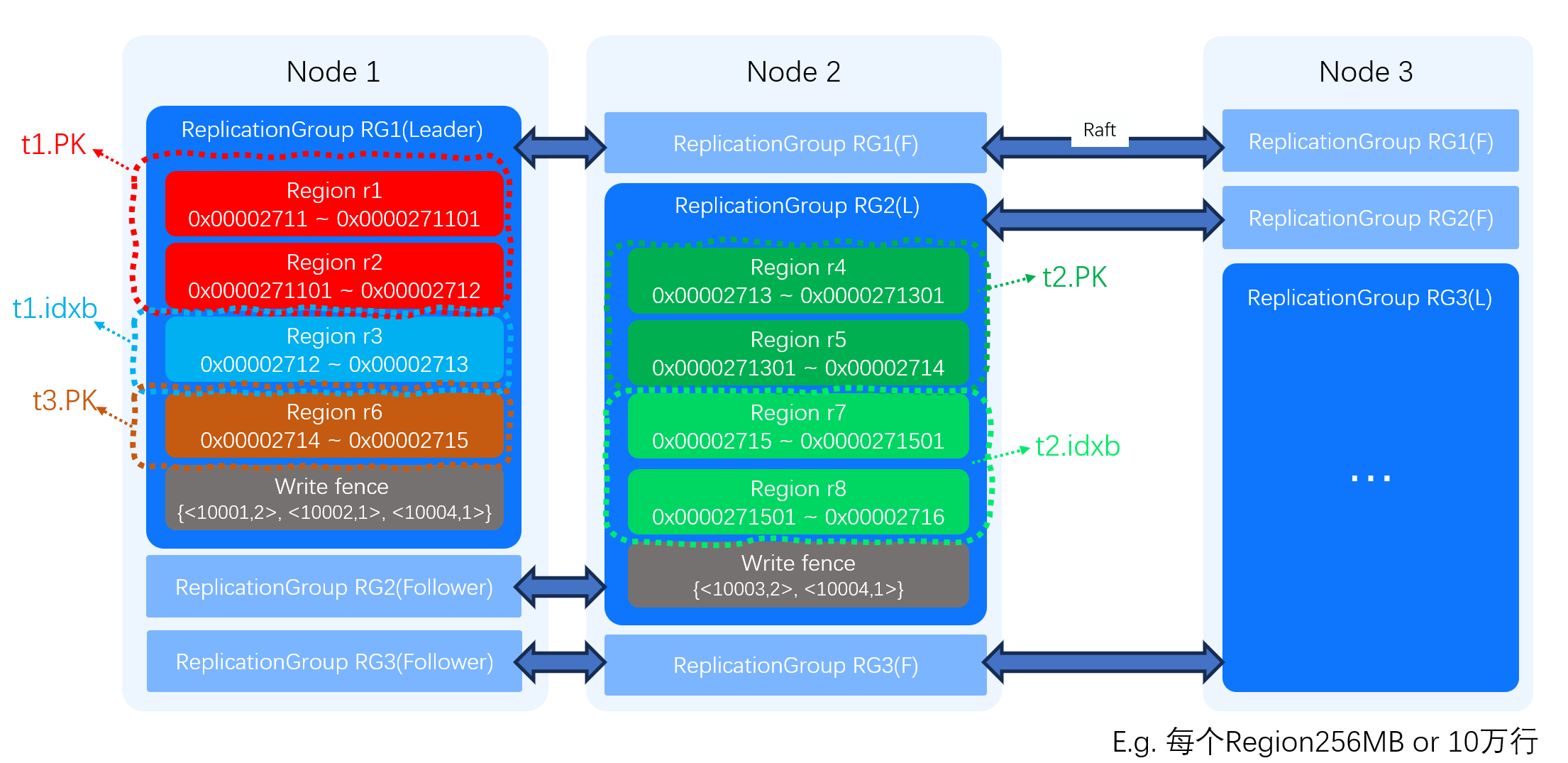
重要特性:
同一索引的数据在空间上连续
同一张表的不同索引可能分布在不同的、不连续的 Region 中
通过复制组可以将关联 Region 调度到相同节点
文档反馈