config set client-output-buffer-limit 'slave 0 0 0'
问题2
问题现象
在使用 DTS 迁移过程中,提示如下错误信息:
[launch]state:8 #rdb rdbfile:./tmp1600395232_34851.rdb rdbsize:107994104 rdb_writed_size:107994104 rdb_parsed_size:107994104 rdb_parsed_begin:1600395238 rdb_parsed_time:5 #replication master_replid:995dba8ccffb7cc32a7c85de7b1632b952b74496 repl_offset:23851025 write_command_count:940765 finish_command_count:940763 last_replack_time:1600395298 #queue send_write_pos:440766 send_read_pos:440765 response_write_pos:440765 response_read_pos:440764 errtime:1600395297 errmsg:get rsp error:ERR value is not an integer or out of range command:*2 $4 INCR $35 APP_API_ORDER_CREATION_USER_4260882
问题原因
分别在该地区的两个 DTS Syncer 上进行抓包,发现 key 的 value 为字符,而非数字,导致 INCR 执行时失败。
解决方法
请删除相关 key 后,重新发起 DTS 迁移。
问题3
问题现象
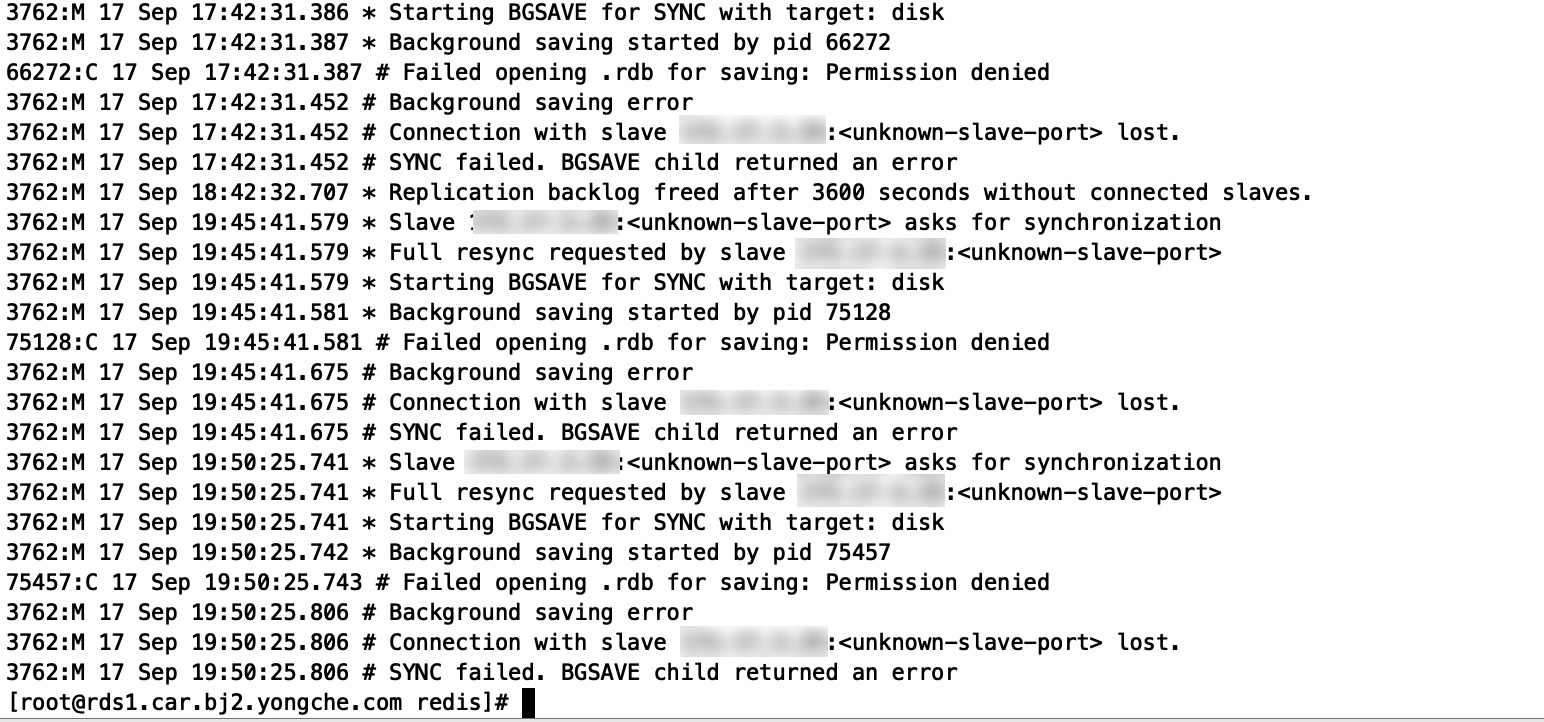
在使用 DTS 迁移过程中,提示如下错误信息:
errmsg:Error reading bulk length while SYNCing:Operation now in progress read rdb length from src fail save rdb fail ready shutdown dts
问题原因
查看源实例的报错信息,可发现 rdb 文件没有目录的访问权限。
解决方法
执行如下命令,设置“无盘复制”,重新发起 DTS 任务。
config set repl-diskless-sync yes
问题4
问题现象
在使用 DTS 迁移过程中,提示如下错误信息:
[launch]state:6 #rdb rdbfile:./tmp1597977351_20216.rdb rdbsize:24282193511 rdb_writed_size:18683334200 rdb_parsed_size:0 rdb_parsed_begin:0 rdb_parsed_time:0 #replication master_replid:1b0da9f595cc40b795803eba3c9bea3aad1a1d68 repl_offset:921330115650 write_command_count:0 finish_command_count:0 last_replack_time:0 #queue send_write_pos:0 send_read_pos:0 response_write_pos:0 response_read_pos:0 errtime:1597978778 errmsg:write rdb data fail:456!=1696 error:No space left on device save rdb fail ready shutdown dts
问题原因
DTS Syncer 机器上的磁盘空间不足。
解决方法
清理 DTS Syncer 机器上的磁盘,或者挂一块新盘,然后重新发起 DTS 任务。
问题5
问题现象
在使用 DTS 迁移过程中,提示如下错误信息:
[launch]state:5 #rdb rdbfile: rdbsize:0 rdb_writed_size:0 rdb_parsed_size:0 rdb_parsed_begin:0 rdb_parsed_time:0 #replication master_replid:d3e707ec0e72c3908b0ce70dd2460f48086c5386 repl_offset:683087907631 write_command_count:0 finish_command_count:0 last_replack_time:0 #queue send_write_pos:0 send_read_pos:0 response_write_pos:0 response_read_pos:0 errtime:1654369638 errmsg:Error reading bulk length while SYNCing:Operation now in progress read rdb length from src fail save rdb fail ready shutdown dts
44:M 05 Jun 03:31:06.728 * Starting BGSAVE for SYNC with target: disk
44:M 05 Jun 03:31:06.978 * Background saving started by pid 89
89:C 05 Jun 03:32:08.417 # Error moving temp DB file temp-89.rdb on the final destination 20617.20324.rdb (in server root dir /opt/data/dump): No such file or directory
44:M 05 Jun 03:32:08.698 # Background saving error
44:M 05 Jun 03:32:08.698 # Connection with slave 10.xx.xx.119:<unknown-slave-port> lost.
44:M 05 Jun 03:32:08.698 # SYNC failed. BGSAVE child returned an error
44:M 05 Jun 03:50:24.626 * Slave 10.xx.xx.119:<unknown-slave-port> asks for synchronization
44:M 05 Jun 03:50:24.626 * Full resync requested by slave 10.xx.xx.119:<unknown-slave-port>
44:M 05 Jun 03:50:24.626 * Starting BGSAVE for SYNC with target: disk
44:M 05 Jun 03:50:24.880 * Background saving started by pid 90
90:C 05 Jun 03:51:22.585 * DB saved on disk
90:C 05 Jun 03:51:22.739 * RDB: 280 MB of memory used by copy-on-write
44:M 05 Jun 03:51:23.008 * Background saving terminated with success
44:M 05 Jun 03:51:27.898 * Synchronization with slave 10.xx.xx.119:<unknown-slave-port> succeeded
44:M 05 Jun 03:52:19.531 # Connection with slave client id #317862457 lost.



 是
是
 否
否
本页内容是否解决了您的问题?