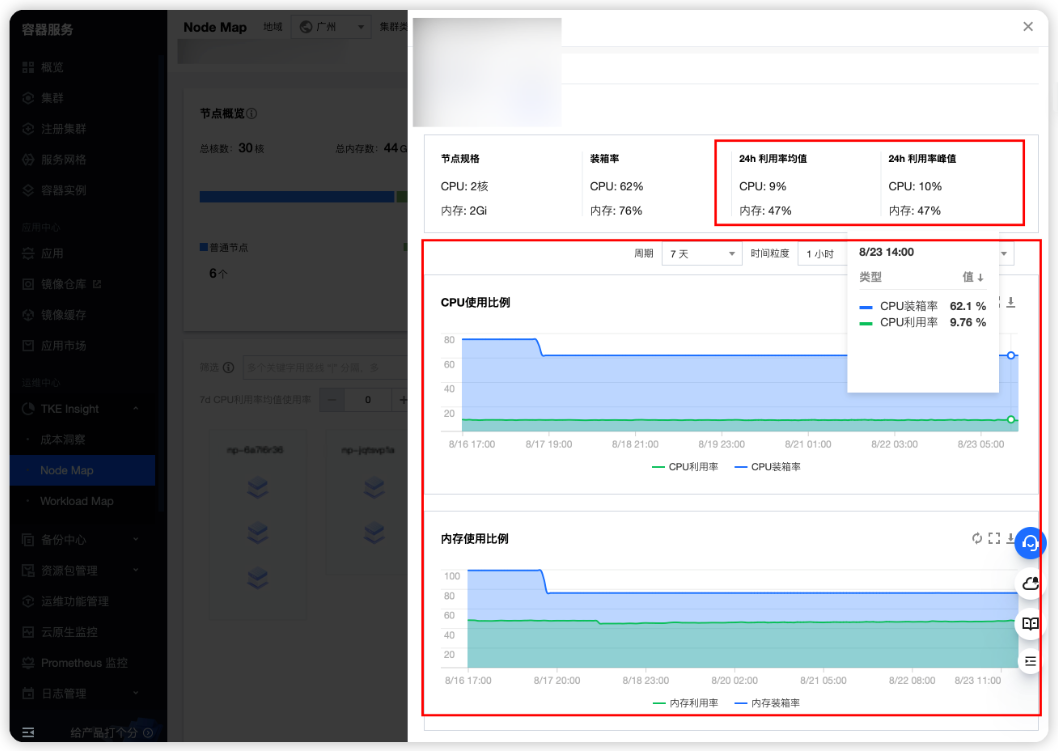
当前 CPU 利用率峰值为10%,内存利用率峰值为47%。假设 CPU 目标利用率为50%,内存目标利用率为90%。
则 CPU 的放大系数为5(注意不要设置得太高,以免 CPU 够用但节点内存出现瓶颈);内存的放大系数为2。
确定目标利用率后,可以根据目标来设置水位线。例如:
调度时水位:建议设置小于等于目标利用率,以允许未达到目标利用率的节点持续调度 Pod。设置得太高可能导致节点过负载。例如,如果目标 CPU 利用率为50%,可以将 CPU 的调度时水位设置为40%。
运行时水位:建议设置大于等于目标利用率,以防止利用率过高导致节点过负载。例如,如果目标 CPU 利用率为50%,可以设置 CPU 的运行时水位为60%。
步骤4:往放大的节点调度 Pod
只有将 Pod 调度到放大的节点上,才能提升节点的资源利用率。有两种方式可以实现:
1. 封锁其他节点:将新需要调度的 Pod 仅调度到放大的节点上,阻止其他节点接收新的 Pod 调度请求。
2. 使用 Workload 的标签选择器能力:通过标签选择器,将 Pod 指定调度到放大的节点上。
建议:
在进行节点放大时,最好选择那些容易下线的节点,将这些节点上的 Pod 重新调度到放大的节点上。这些节点可能包括:
Pod 数量很少的节点。
按量计费节点。
快到期的包年包月的节点。
如果您指定了节点的 CPU 和内存放大系数,可以通过查看与放大系数相关的 Annotation:expansion.scheduling.crane.io/cpu,expansion.scheduling.crane.io/memory来确认。示例如下:
kubectl describe node10.8.22.108
...
Annotations: expansion.scheduling.crane.io/cpu: 1.5# CPU 放大系数
expansion.scheduling.crane.io/memory: 1.2# 内存放大系数
...
Allocatable:
cpu: 1930m # 该节点原始可调度资源量
ephemeral-storage: 47498714648
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 1333120Ki
pods: 253
...
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 960m (49%) 8100m (419%)# 该节点 Request 和 Limit 占用量
memory 644465536(47%)7791050368(570%)
ephemeral-storage 0(0%)0(0%)
hugepages-1Gi 0(0%)0(0%)
hugepages-2Mi 0(0%)0(0%)
...
说明:
当前节点的原始 CPU 可调度量为1930m,节点上所有 Pod 的 CPU 请求总量为960m。在正常情况下,该节点最多只能调度970m的 CPU 资源(1930m - 960m)。然而,通过虚拟放大,该节点的 CPU 可调度量已经增加到2895m(1930m * 1.5),实际剩余的 CPU 可调度资源为1935m(2895m - 960m)。
此时,如果创建一个工作负载,只有一个 Pod,其 CPU 请求量为1500m,如果没有节点放大的能力,则无法将该 Pod 调度到该节点上。
在 步骤4 中选择的节点上,当节点上的非 DaemonSet 的 Pod 全部移出后,可以将该节点移出并删除,从而用更少的节点承载相同的业务量。
通过以上方式,可以对集群中的 Pod 进行规整。例如,假设集群中有20个原生节点和20个普通节点,规格相同,整体资源利用率为 CPU 10%和内存 40%。通过将20个原生节点的 CPU 和内存放大一倍,可以将20个普通节点上的 Pod 迁移至原生节点上。这样,原生节点的资源利用率将提高到 CPU 20%和内存 80%。同时,普通节点上将没有 Pod 存在,因此可以将这些普通节点从集群中移除,从而减少了一半的节点规模。