- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- CKafka 连接器
- 最佳实践
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- DataHub APIs
- ACL APIs
- Topic APIs
- BatchModifyGroupOffsets
- BatchModifyTopicAttributes
- CreateConsumer
- CreateDatahubTopic
- CreatePartition
- CreateTopic
- CreateTopicIpWhiteList
- DeleteTopic
- DeleteTopicIpWhiteList
- DescribeDatahubTopic
- DescribeTopic
- DescribeTopicAttributes
- DescribeTopicDetail
- DescribeTopicProduceConnection
- DescribeTopicSubscribeGroup
- FetchMessageByOffset
- FetchMessageListByOffset
- ModifyDatahubTopic
- ModifyTopicAttributes
- DescribeTopicSyncReplica
- Instance APIs
- Route APIs
- Other APIs
- Data Types
- Error Codes
- SDK 文档
- 通用参考
- 常见问题
- 服务等级协议
- 联系我们
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- CKafka 连接器
- 最佳实践
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- DataHub APIs
- ACL APIs
- Topic APIs
- BatchModifyGroupOffsets
- BatchModifyTopicAttributes
- CreateConsumer
- CreateDatahubTopic
- CreatePartition
- CreateTopic
- CreateTopicIpWhiteList
- DeleteTopic
- DeleteTopicIpWhiteList
- DescribeDatahubTopic
- DescribeTopic
- DescribeTopicAttributes
- DescribeTopicDetail
- DescribeTopicProduceConnection
- DescribeTopicSubscribeGroup
- FetchMessageByOffset
- FetchMessageListByOffset
- ModifyDatahubTopic
- ModifyTopicAttributes
- DescribeTopicSyncReplica
- Instance APIs
- Route APIs
- Other APIs
- Data Types
- Error Codes
- SDK 文档
- 通用参考
- 常见问题
- 服务等级协议
- 联系我们
- 词汇表
操作场景
数据接入平台(DataHub)是腾讯云上的数据接入和处理平台,一站式提供对数据的接入、处理和分发功能。数据在互联网业务中至关重要,而数据接入上报是整个链路中,介于数据产生和计算、存储、分析的桥梁,简单高效的数据接入是至关重要的。我们在业务经常有一些数据(业务指标、流程信息、监控信息等)需要上报到后台进行存储、分析、计算、搜索。其处理链路通常如下:
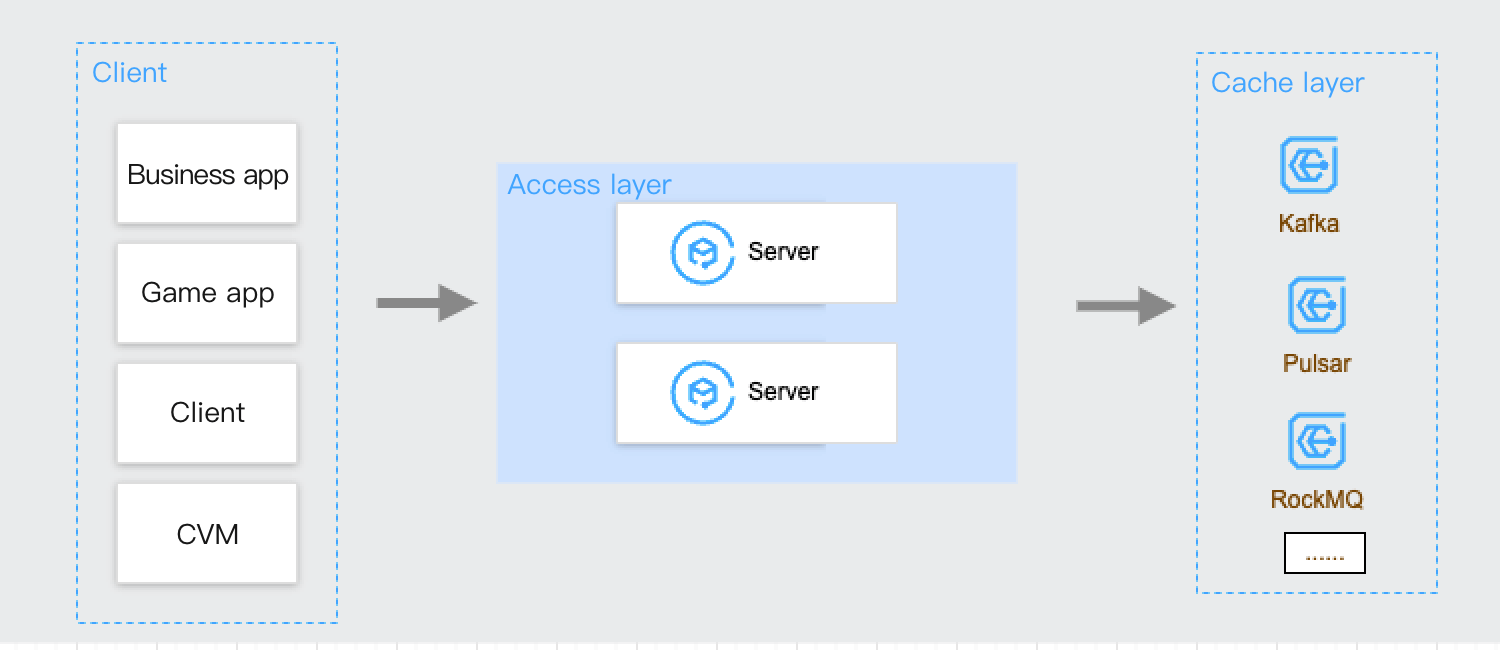
在经典数据上报架构中,通常需要有如下几个步骤:
1. 搭建/购买存储引擎,用来存储上报的数据。
2. 开发部署数据接收的 Server、定义 API、运行服务。
3. 定义客户端和服务端的接口协议、鉴权等信息
4. 客户端根据协议信息编写相应的代码完成数据上报。
在这四步中,Server 端的工作量是最大的,需要考虑代码逻辑开发、Server 本身扩缩容和稳定性、下游存储的扩缩容和稳定性等,而当数据量大时,Server 端问题会更加明显,需要消耗大量的人力物力来进行维护。但这部分工作通用性很高,DataHub 希望可以满足这种场景,提供稳定、弹性、高可靠、高吞吐的数据接入服务。
运行原理
DataHub 提供了 Java、Python、GoLang、PHP、NodeJs、C++、.Net 等各语言的 SDK 来方便客户端进行数据上报。通过3步即可将数据上报到存储引擎中,例如 Kafka(后续会支持 RocketMQ,Pulsar,RabbitMQ,CMQ 等多种消息队列)。具体步骤如下:
1. 在 DataHub 控制台创建接入点。
2. 通过 SDK 上报数据。
3. 数据查询。
操作步骤
1. 在 DataHub 控制台创建接入点。可参见 HTTP上报 创建接入点。
2. 通过 SDK 进行数据上报。使用步骤可参见 数据上报 SDK。
3. 数据查询。当数据上报到 DataHub 后,可以实时查询消息内容,详情请参见 消息查询。
数据赋能
当通过 DataHub 简单快速的完成数据接入后,如何让数据产生价值才是最重要的事情。DataHub 提供的两个核心功能:
数据处理
DataHub 提供了简单的数据 ETL 引擎,提供了可以满足大部分数据清洗需求的处理引擎,对数据进行简单的格式化和处理,以便进行后续的使用。
数据流出
当完成数据处理后,DataHub 可以满足以下多种场景的数据处理需求:
实时搜索: 当需要对数据进行搜索时,可以将数据流式实时导出到:Elasticsearch、CLS 等搜索服务进行实时搜索。
OLAP 分析:让需要对数据进行分析时,可以将数据流式实时导出到 ClickHouse、TDW 等引擎进行分析。
持久存储:当需要对数据进行持久存储时,可以将数据流式实时导出到 HDFS、COS 等持久化引擎进行存储。
流计算:当业务需要通过自定义代码处理数据时,可以通过标准的 Kafka 协议,使用 FLink、Spark、各语言代码对数据进行处理。
至此,数据经过数据上报、接入、处理、流出四个环节后,简单快速的满足通用的数据上报、分析类需求,用极低的成本让数据体现出价值。

 是
是
 否
否
本页内容是否解决了您的问题?