云服务器 CVM 日志接入
Download
聚焦模式
字号
前提条件
已创建腾讯云账号,创建账号可参考 注册腾讯云。
如使用子账号登录,请确保该账号具备 ES 的读写权限。
操作步骤
登录控制台
1. 登录 ES 控制台。
2. 在顶部菜单栏,选择地域,当前已支持北京、上海、广州、南京、中国香港地域。
3. 在左侧导航栏 Serverless 模式下选择日志分析。
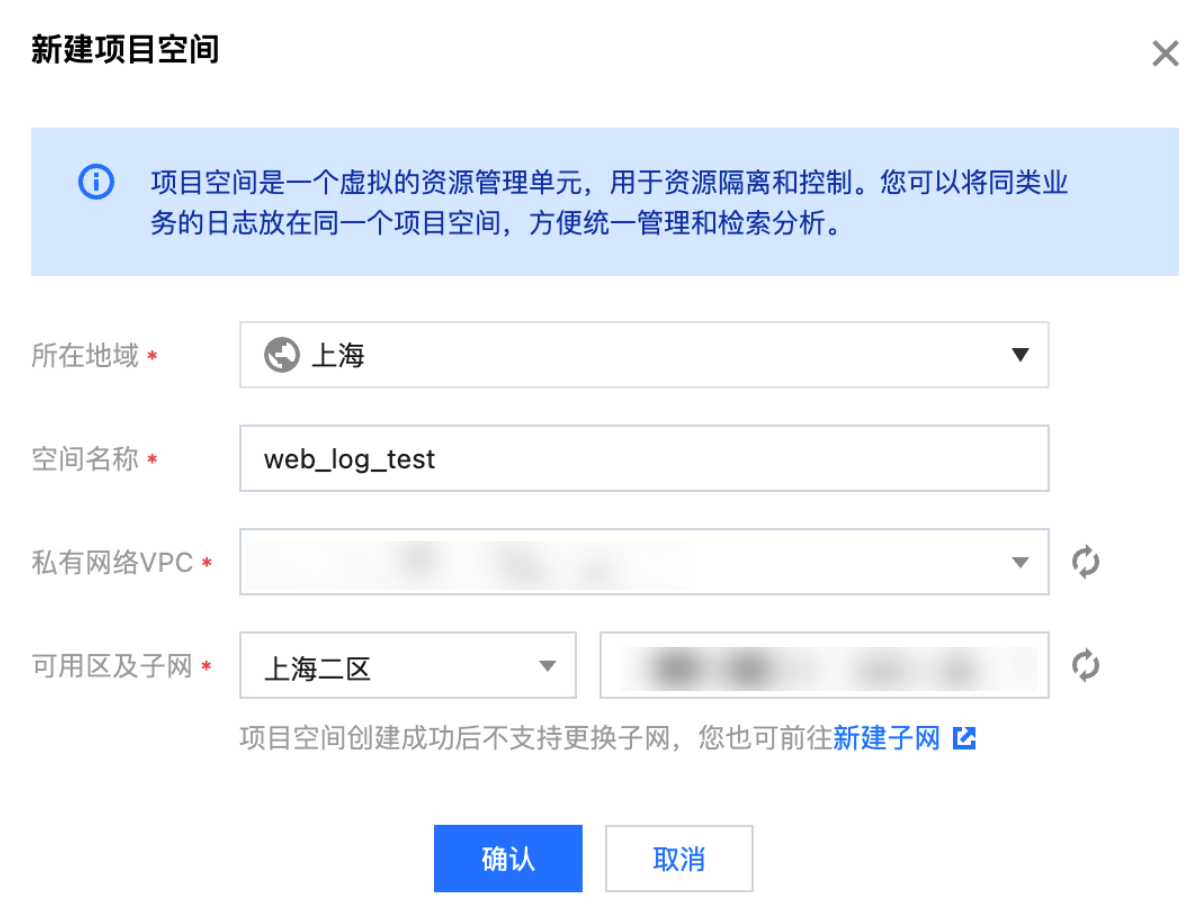
创建项目空间
1. 单击新建空间。
2. 输入项目空间名称,支持1 - 20个中文、英文、数字、下划线或分隔符"-"。
3. 单击确认,校验无误即可成功创建项目空间。
说明:
在 ES Serverless 日志分析中,您可仅 创建索引,后续通过 API 进行数据写入或者在对应索引的“数据接入”Tab 页进行 CVM 或 TKE 等数据源接入。您也可在创建索引时同时进行数据接入,完成一站式的 CVM 日志接入、TKE 日志接入。以下为您介绍一站式的 CVM 日志接入操作。
云服务器 CVM 日志接入
在 ES Serverless 日志分析首页选择云服务器 CVM,进入 CVM 日志接入页面。

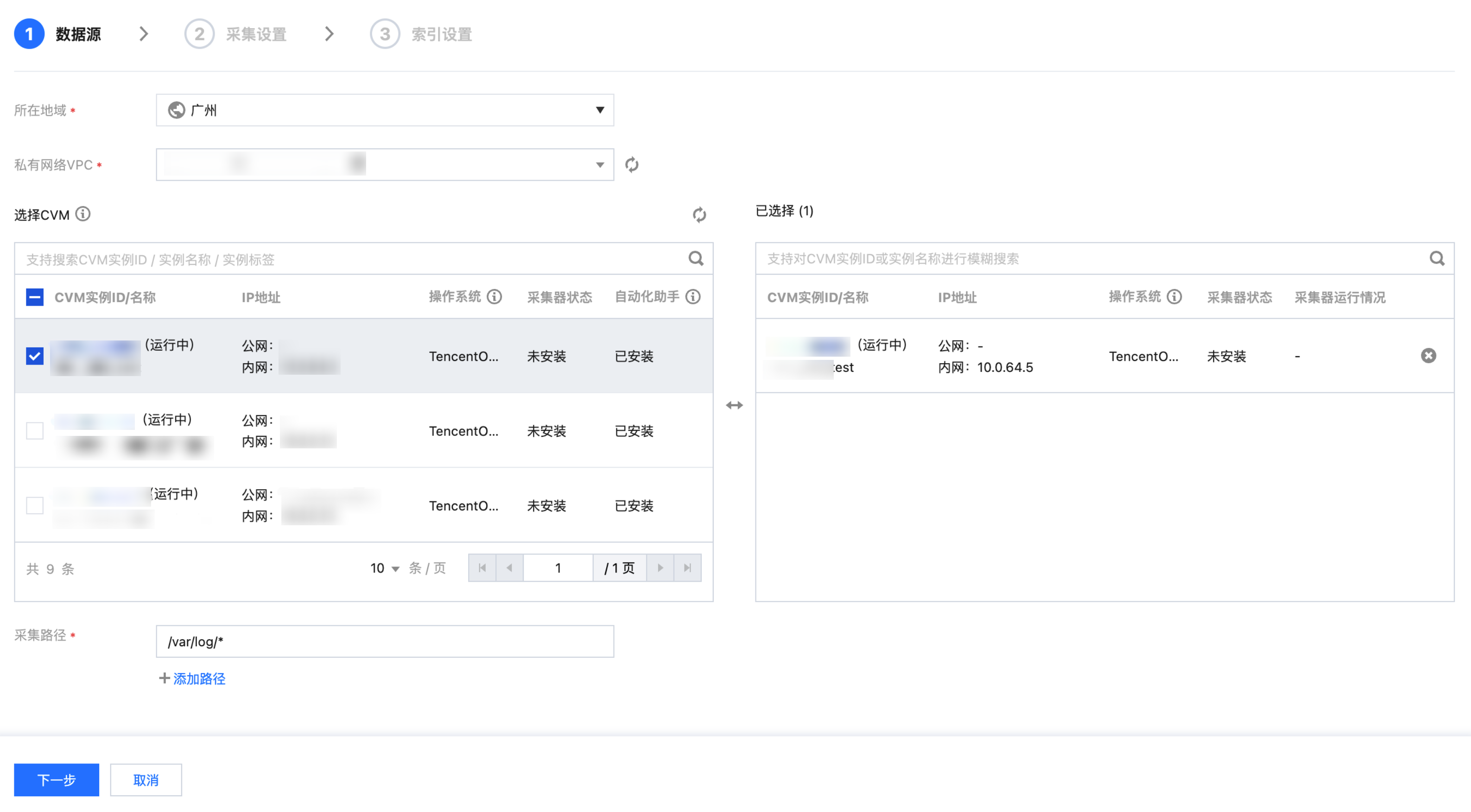
数据源设置
所在地域:必选,云服务器 CVM 所在的地域。
私有网络 VPC:必选。云服务器 CVM 所在的私有网络,确认后将把该 VPC 下的服务器拉取出来。
选择 CVM:选择要进行日志采集的 CVM 实例,当前仅支持 Linux 系统的 CVM,同时必须 安装自动化助手后才能采集数据。
采集路径:根据日志在服务器上的位置,设置日志目录和文件名称,支持一条或多条。目录名和文件名支持完整名称和通配符模式。
采集设置
基本设置
采集策略:支持全量采集与增量采集,创建完成后,不支持修改采集策略。全量采集会将历史以及 Filebeat 配置生效后生成的日志文件采集上来;增量采集则仅采集 Filebeat 配置生效后生成的日志文件。
采集解析
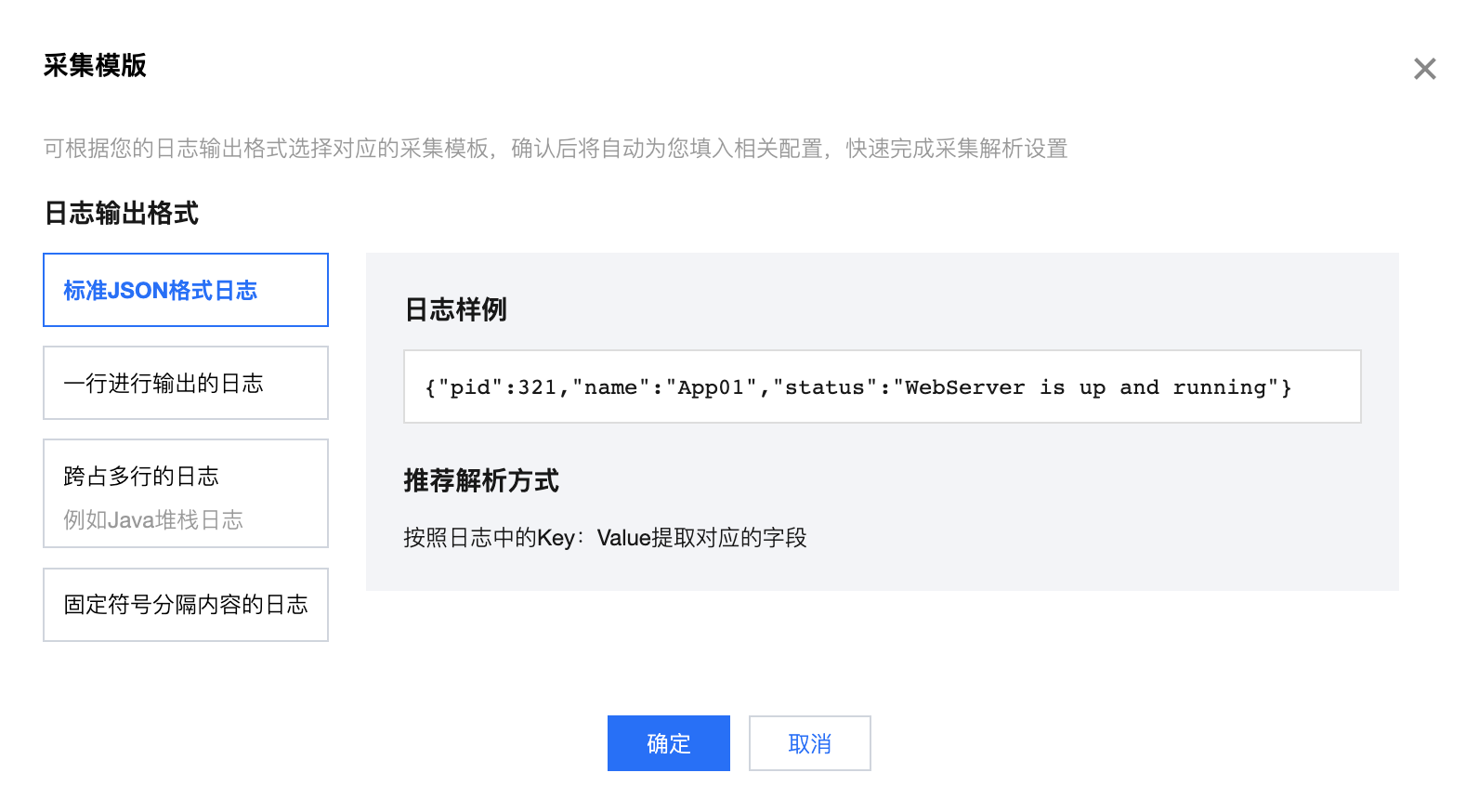
采集模板:如您需快速进行设置或是体验,可根据您的日志输出格式选择对应的采集模板。确认后,您可返回界面,将日志样例修改为实际的日志数据,快速完成采集解析设置。
采集模式:支持单行以及多行,创建完成后,不支持修改采集模式。
单行文本日志:一行日志内容为一条日志,即在日志文件中,以换行符分隔两条日志。
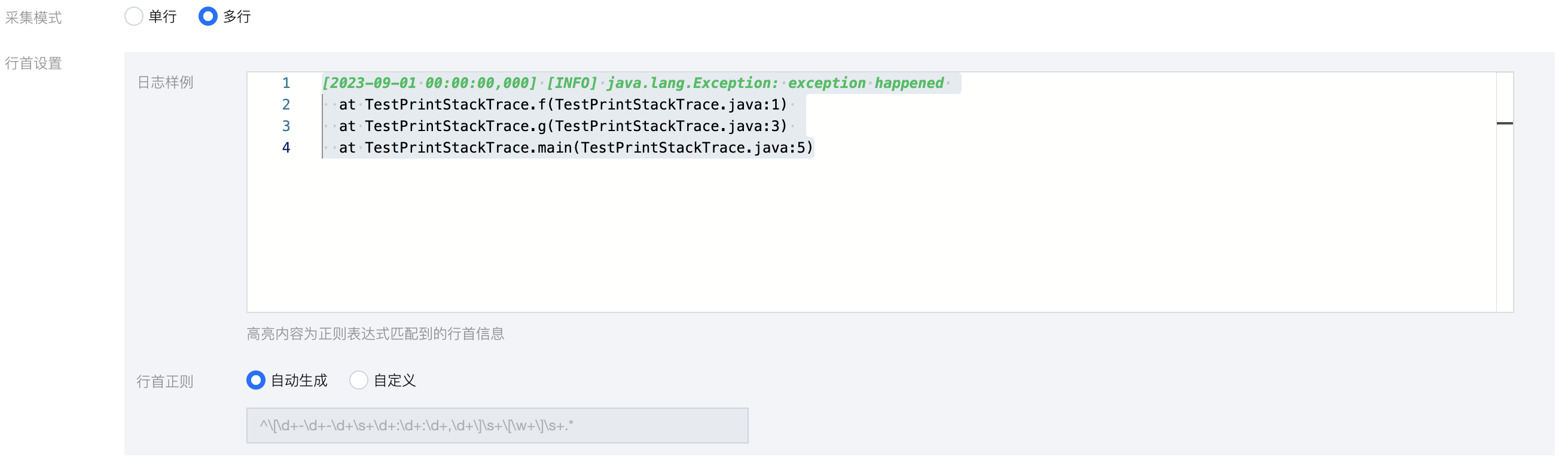
多行文本日志:一条日志由多行组成,例如 Java 堆栈日志。该模式下,您需配置日志样例和行首正则表达式,Filebeat 通过行首正则表达式去匹配一条日志的行首,即确认一条日志的开头,将未匹配部分作为该条日志的一部分,直到下一个行首出现。输入日志样例后,系统将默认自动生成行首正则表达式,您也可选择自定义生成,输入框内的高亮内容为正则表达式匹配到的行首信息。
注意:
请务必使用实际场景的日志,便于自动提取行首正则表达式。
提取设置:支持将提取模式设置为全文日志、JSON 格式、分隔符,创建完成后,不支持修改提取模式。详情如下:
日志数据不做任何键值提取,日志内容将存储到名称为"message"的字段中,您可通过自动分词能力进行检索分析。
例如一条单行日志原始数据为:
Tue Jan 01 00:00:00 CST 2023 Running: Content of processing something
则采集到索引中的数据为:
massage:Tue Tue Jan 01 00:00:00 CST 2023 Running: Content of processing something
对于内容为标准 JSON 格式的日志,我们可按照日志中的 Key:Value 提取对应的字段。
假设您的一条 JSON 日志原始数据为:
{"pid":321,"name":"App01","status":"WebServer is up and running"}
经过结构化处理后,该条日志将变为如下:
{ "pid":321, "name":"App01", "status":"WebServer is up and running" }
对于固定分隔符分割内容的日志,我们可按照指定分隔符对日志进行键值提取。分隔符支持单个字符或者是字符串,可在控制台选择或输入分隔符。
假设您的一条日志原始数据为:
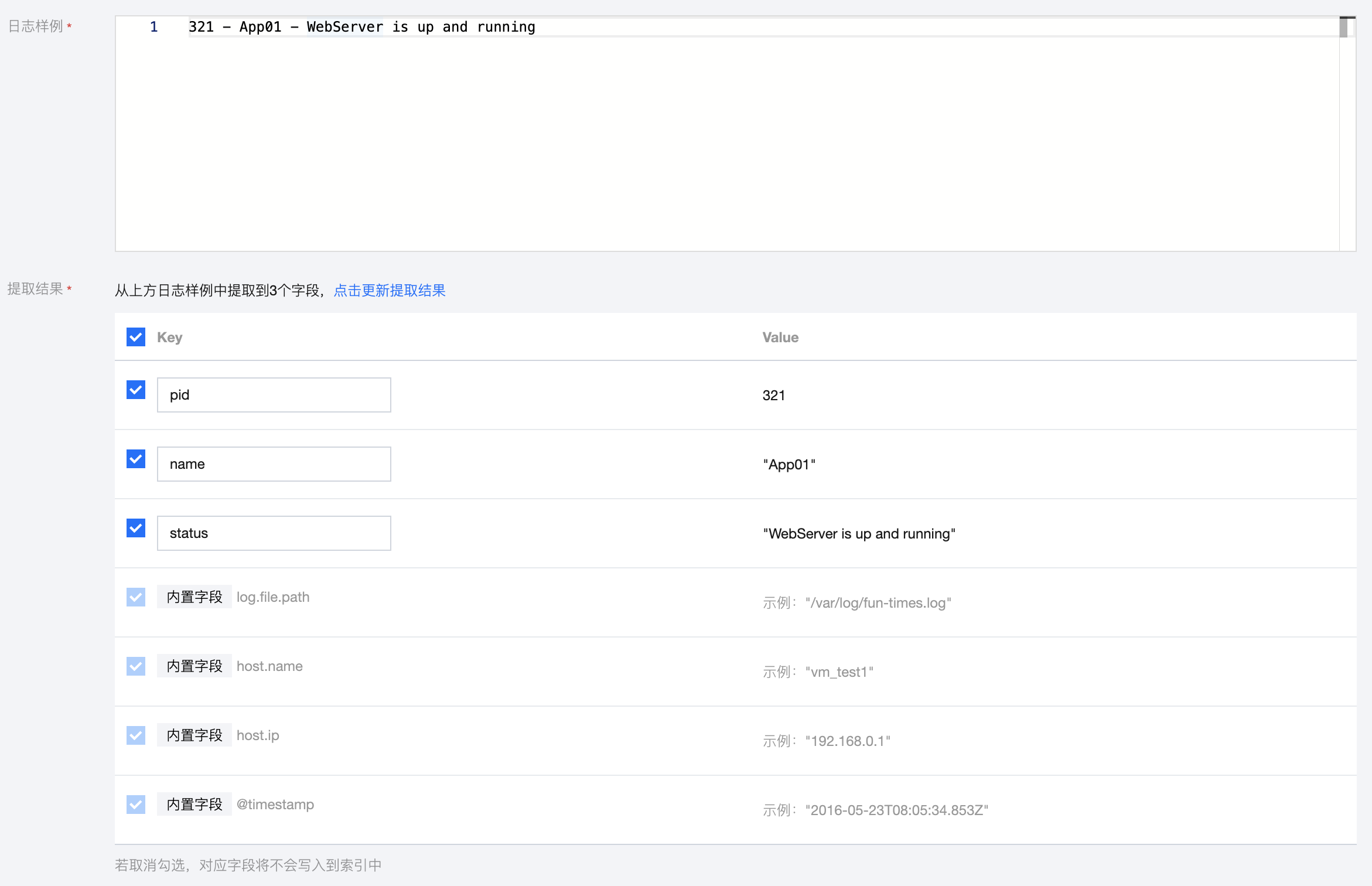
321 - App01 - WebServer is up and running
将分隔符指定为"-" ,该条日志会被分割成3个字段,我们可在提取结果中为这3个字段定义唯一的 Key,如下所示:
pid: pidname: App01status: WebServer is up and running
提取结果:如提取模式选择为 "JSON 格式"或者"分隔符",我们可输入日志样例,系统将自动对样例进行提取:
如提取模式为 JSON 格式,系统默认填充提取到的 Key 与 Value,如取消勾选,对应字段将不会写入到索引中。
如提取模式为分隔符,系统将默认填充提取到 Value,您可为每个 Value 定义唯一的 Key,如取消勾选,对应字段将不会写入到索引中。
内置字段:在控制台配置 CVM 日志采集时,Filebeat 会将日志来源、时间戳等信息以 Key-Value 对的形式写入到日志中,这些字段是内置字段。如您业务日志中的 Key 名称与内置字段名称重复,将优先采集业务日志的字段内容,对应的内置字段则将不会写入到索引中。内置字段的含义如下:
内置字段名称 | 含义 |
log.file.path | 日志所存放的路径 |
host.name | 日志所在的服务器的机器名称 |
host.ip | 日志所在的服务器的 IP |
@timestamp | 采集到该条日志的时间 |
保留原始日志:勾选后,解析提取前的原始日志内容,将保留到该字段中。
记录解析错误:如提取模式为"分隔符",您可选择是否记录解析错误。勾选后,当解析失败时,报错信息将作为值(Value)上传到该字段中。
索引设置
所属项目空间:您可将同一个业务的索引都归属到某个项目空间下以便于管理。
索引名称:长度为1 - 100,支持小写字母,数字, -, _, ;, @, &, =, !, ', %, $, ., +, (, )。
字段映射
动态生成:默认开启,开启后将自动解析写入的数据,生成索引的字段设置。
输入样例自动配置:关闭动态生成后,您可以通过输入样例自动配置来生成索引的字段映射,在输入框内输入一段 JSON 格式的数据样例,确定后平台将自动为您进行校验,校验无误后,相关字段将映射到字段映射的表格中。
字段映射将原始数据按字段(即 key:value)分别切分为多个分词进行索引构建,检索时基于该映射进行检索。具体如下:
参数项 | 功能描述 |
字段名称 | 写入的数据中的字段名称 |
字段类型 | 字段的数据类型,界面支持“text、date、boolean、keyword、long、double、integer、ip、geo_point”9种类型,更多字段类型可在 JSON 编辑模式中支持,具体可参考 官方说明 |
包含中文 | 字段中包含中文且需要对中文进行检索时可开启该功能。开启后,将默认对该 text 字段使用 ik_max_word 分词器 |
开启索引 | 启用后,会对该字段构建索引用于检索 |
开启统计 | 启用后,可以对字段值做统计分析,会增加索引存储 |
时间字段
时间字段指在实际数据中类型为 date 的字段,索引创建成功后该字段不可更改。
注意:
时间字段默认打开开启索引与开启统计,且不可关闭。
数据存储时长:
1.1 您可设置数据的存储时长,默认选择存储30天,同时也支持设置为永久保存。
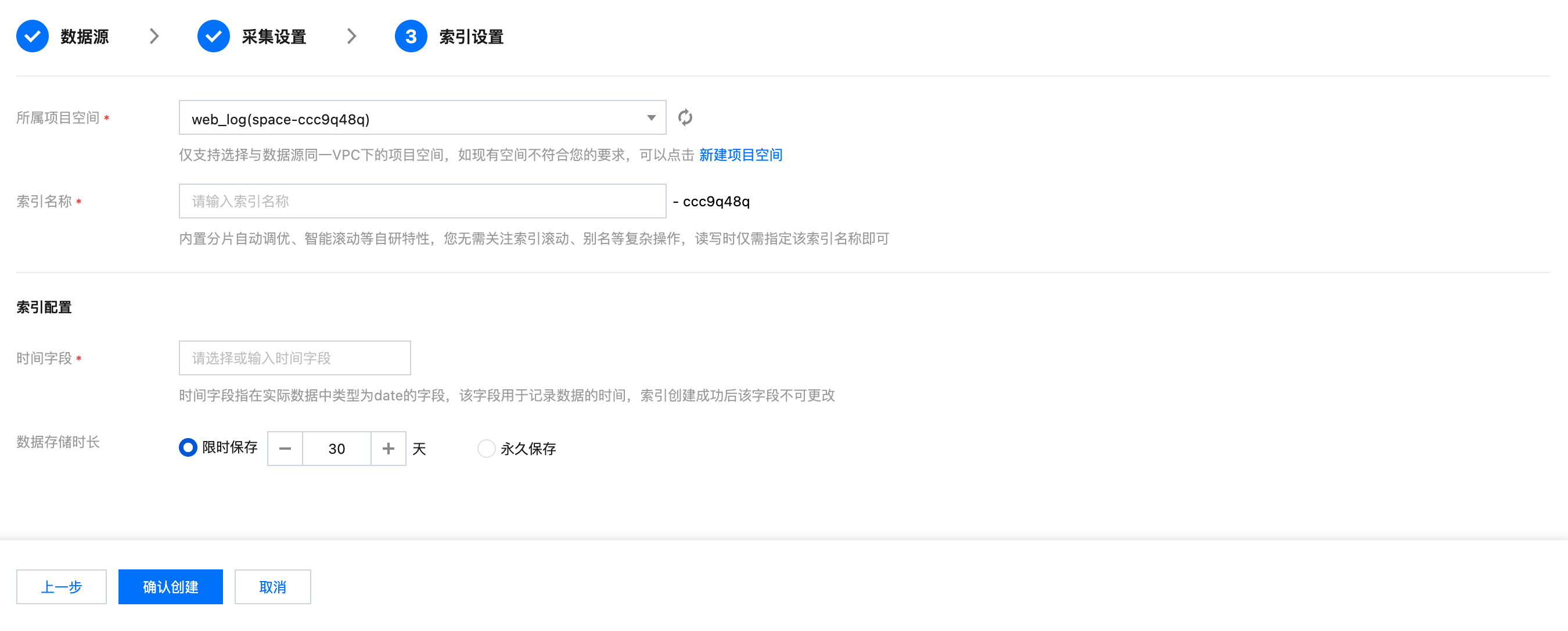
1.2 信息填写无误后,单击确认创建,即可完成 CVM 日志采集。
文档反馈