Intelligent Search Development Service Pricing
Download
Focus Mode
Font Size
Leveraging Tencent Cloud Elasticsearch engine and ecosystem advantages, we help customers easily build applications like Retrieval-Augmented Generation (RAG) and AI search with less R&D and Ops investments. This document describes in detail the billing modes and unit price policies for each atomic service. Based on the pay-as-you-go principle, prepaid resource packages and pay-as-you-go options are offered to help customers achieve granular cost management according to actual business scenarios.
Billing Mode | Description |
Pay-as-you-go | Billing is based on the actual resources consumed by API calls. Settlement and deduction are performed on your Tencent Cloud account on an hourly basis. Ensure that your account is in a non-arrears status before formal usage. |
Prepaid resource package | The fees for the entire validity period are prepaid in a lump sum to offset the costs incurred by using corresponding atomic services. The validity period is one year from the date of purchase. |
Free Quotas
After Intelligent Search Development Atomic Services are enabled for the root account that has passed real-name authentication, the account will have a total of 100 free testing quotas for all atomic services. Usage beyond the quota will be automatically billed. If you have more testing needs, please contact us.
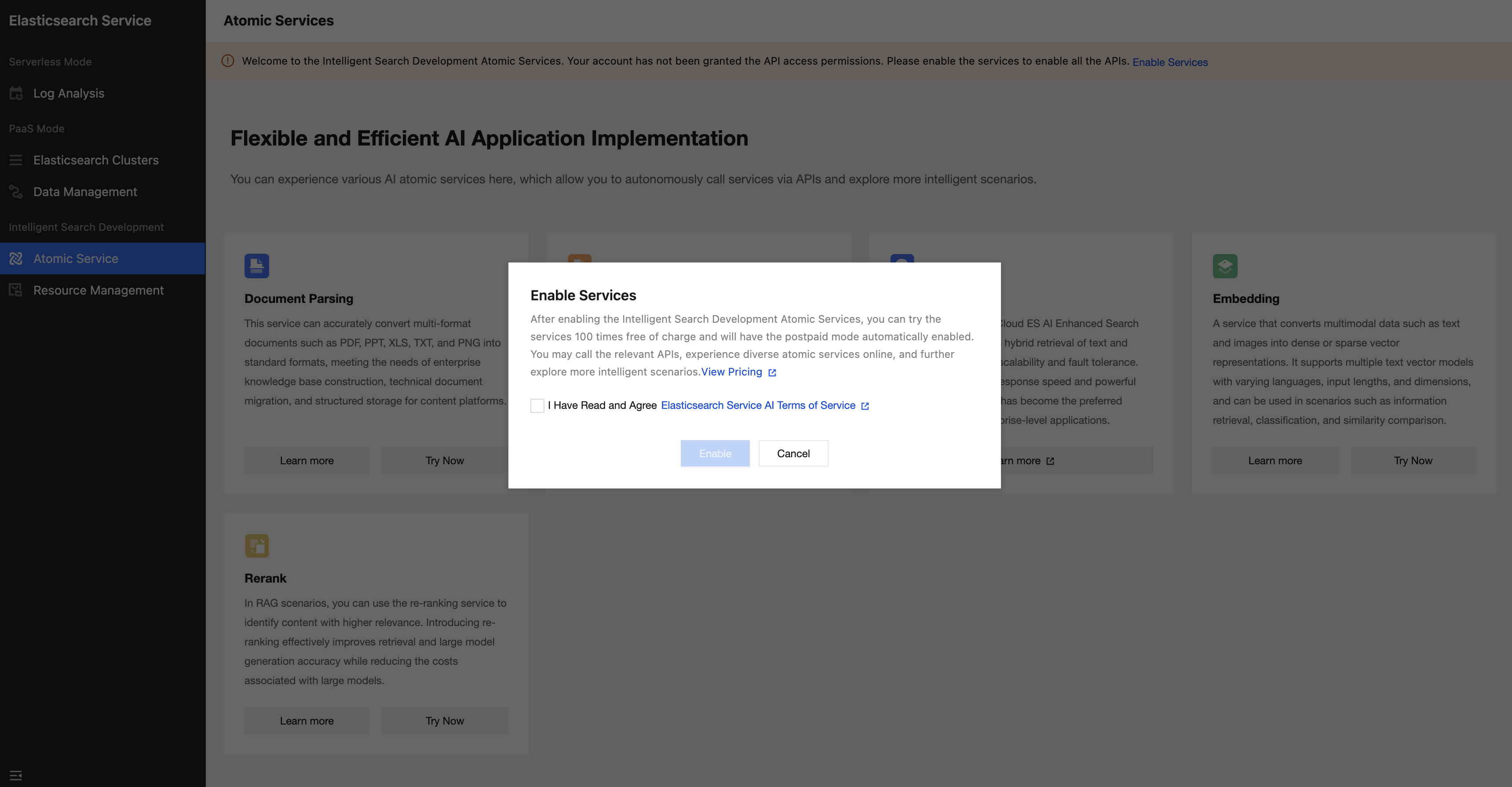
Purchase Methods
During billing settlement, the system will settle in the following order: free trial quotas > resource packages > postpaid.
Billing covers direct API calls and the online trials of using relevant atomic services in the console. Failed calls are not billed.
Enabling Postpaid
After Intelligent Search Development Atomic Services are enabled, postpaid is automatically enabled by default. Once the free trial quotas are used up, if no prepaid resource package is purchased, billing will automatically switch to postpaid. To enable or disable postpaid billing, please go to the console and choose Resource Management > Postpaid Settings to enable or disable postpaid.
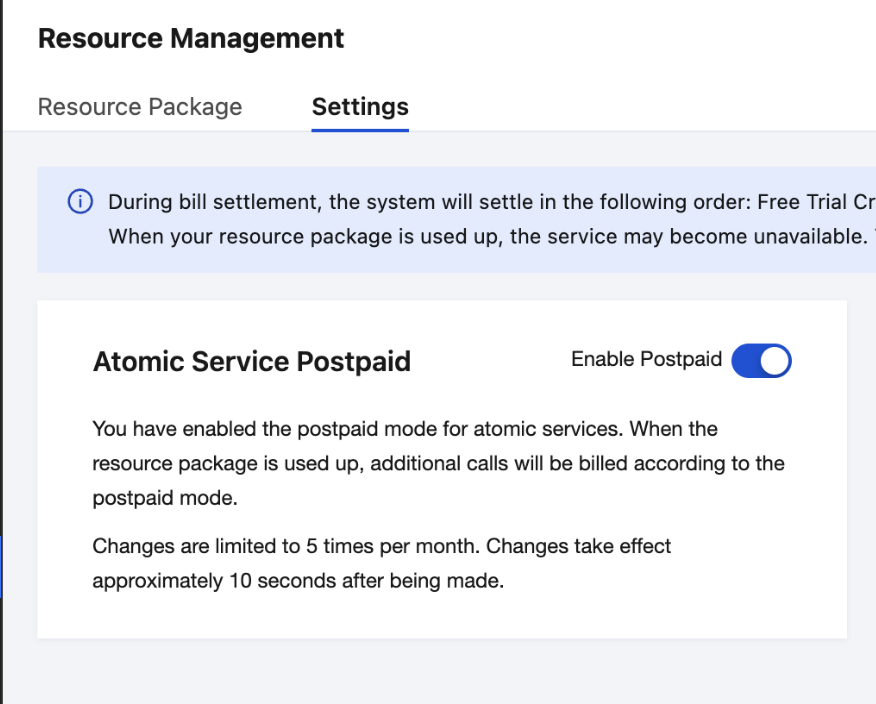
Note:
Postpaid settings can only be changed up to 5 times per month. Changes take effect in approximately 10s. Please refrain from making frequent changes.
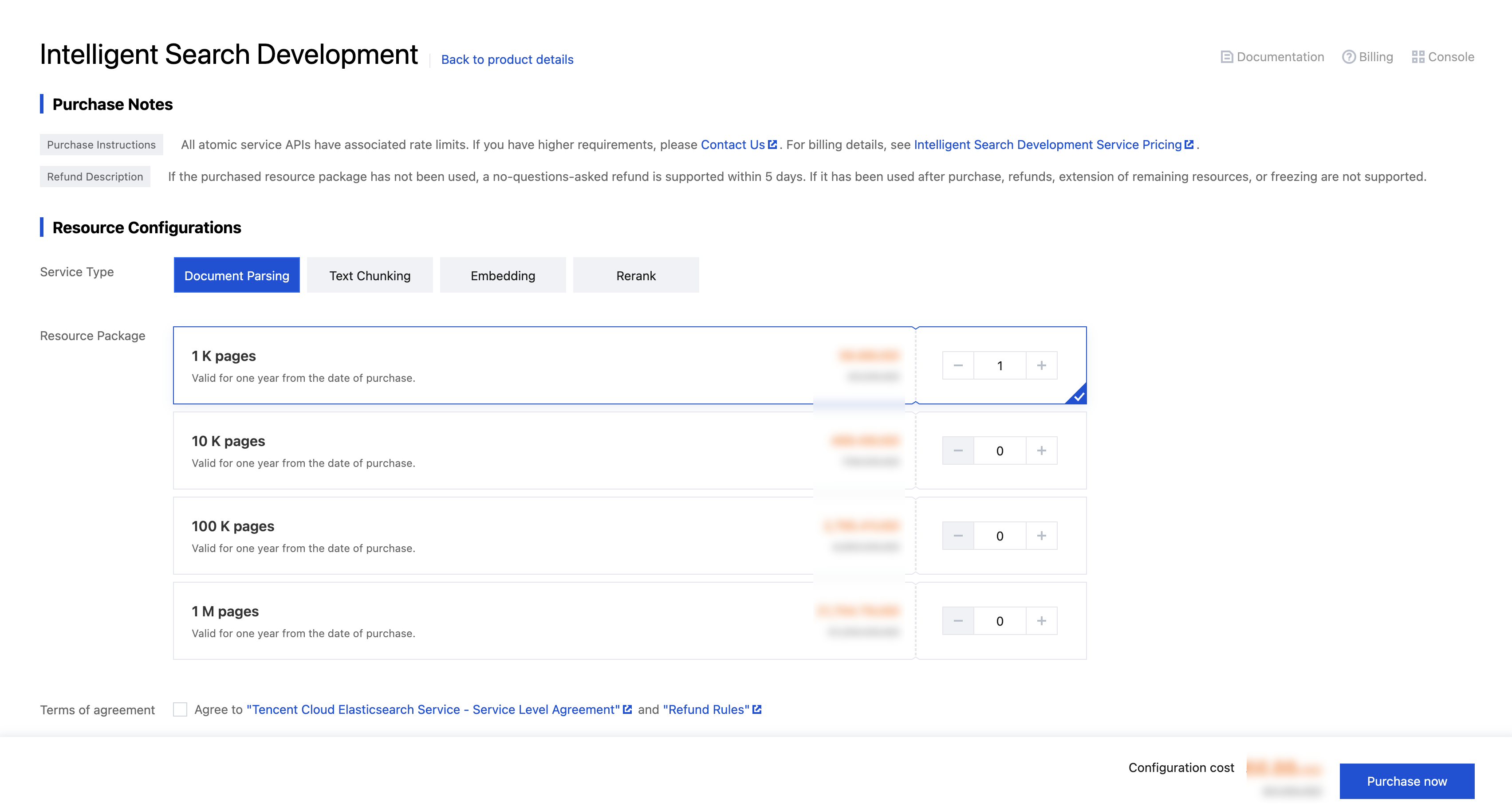
Purchasing a Resource Package
In the console's Resource Management menu bar, click Purchase Resource Package and select the desired resource type:
Pay-as-You-Go Pricing
Document Parsing
The document parsing service is billed based on the number of pages successfully parsed from the original documents. The unit prices are as follows:
Service | List Price (USD/Page) |
doc-llm | 0.083 |
Note:
The doc-llm document parsing service is billed per page. The billing rules for different document types are as follows:
DOC, DOCX, PPT, PPTX, and PDF are billed per page.
JPEG, PNG, and other image formats are billed as one page per image.
XLSX, TXT, MD, and CSV are billed as one page per file.
Text Chunking
The text chunking service is billed per thousand tokens. The unit prices are as follows:
Service | List Price (USD/Thousand Tokens) |
doc-tree-chunk | 0.0125 |
doc-chunk | 0.000009 |
Note:
The doc-tree-chunk service implements document chunking based on the doc-llm document parsing service. By default, fees are divided into parsing and chunking costs, as detailed below:
When the input files are in document formats such as PDF/DOCX/DOC/PPT/PPTX and image formats such as JPG/PNG, document parsing fees are billed per page.
When input files are in TXT/MD/XLSX/XLS formats, only engineering parsing is required, and no fees are charged.
Files input through either method incur chunking fees, billed based on the number of tokens consumed.
The doc-chunk service chunks text based on delimiters and text length and applies to highly structured text. The tokens counted here refer to the character length of the original text.
Embedding
The text-only embedding service is billed per thousand tokens. The unit prices are as follows:
Model | Level | Token Limit | Language | List Price (USD/Thousand Tokens) |
KaLM-embedding-multilingual-mini-v1 | 896 | 131072 | Multilingual | 0.0001 |
bge-m3 | 1024 | 8194 | Multilingual | 0.0001 |
The text and image embedding service supports input in both text and image modalities, billed separately based on tokens and the number of images. The unit prices are as follows:
Model | Level | Token Limit | Language | List Price |
WeCLIPv2-Large | 768 | 72 | Multilingual, better suited for Chinese scenarios | Text: USD 0.0001/thousand tokens Images: USD 0.1/thousand images |
Reranking
The reranking service is billed per thousand tokens. The unit prices are as follows:
Model | Token Limit | Language | List Price (USD/Thousand Tokens) |
bge-reranker-v2-m3 | 8194 | Multilingual | 0.0002 |
Resource Package Pricing
Intelligent Search Development Services provide prepaid resource packages for purchase, which can be used to consume various atomic services. Compared to the pay-as-you-go billing mode, resource packages are more cost-effective. You can go to the purchase page to buy prepaid resource packages.
Pricing by Resource Type
Resource Type | Resource Package Specifications | List Price (USD) |
Document parsing | 1 thousand pages | 83 |
| 10 thousand pages | 708 |
| 100 thousand pages | 4083 |
| 1 million pages | 31250 |
Text chunking | 10 million tokens | 125 |
| 100 million tokens | 1188 |
| 1 billion tokens | 11250 |
Text embedding | 1 billion tokens | 100 |
| 10 billion tokens | 950 |
| 100 billion tokens | 9000 |
Image embedding | 1 million images | 100 |
| 10 million images | 950 |
| 100 million pieces | 9000 |
Reranking | 1 billion tokens | 200 |
| 10 billion tokens | 1900 |
| 100 billion tokens | 18000 |
Deduction Coefficient
The deduction coefficients vary across different models. The consumption of actual resource packages is calculated based on the deduction coefficients. The conversion formula is: Resource package usage = Actual usage x Deduction coefficient.
Billing Calculation Example:
If Customer A uses 1 billion tokens for text chunking (doc-chunk) and 1 million tokens for doc-tree-chunk, the deducted resource package usage is calculated as follows: 1 billion x 0.00066667 + 1 million x 1 = 1.66667 million tokens.
The deduction coefficient for each resource type is as follows:
Resource Type | Model Service | Deduction Coefficient |
Document parsing | doc-llm | 1 |
Text chunking | doc-tree-chunk | 1 |
| doc-chunk | 0.00066667 |
Text embedding | KaLM-embedding-multilingual-mini-v1 | 1 |
| bge-m3 | 1 |
Image embedding | WeCLIPv2-Large | 1 |
Reranking | bge-reranker-v2-m3 | 1 |
Deduction Coefficient Description:
The deduction coefficient is a conversion ratio used to standardize billing across different model services. Taking embedding services as an example: When you are unsure which embedding model best suits your business needs, you can directly purchase a general embedding resource package. This resource package supports all embedding models, and the system automatically calculates resource consumption based on the deduction coefficient of the actually called model (for example: 1 call of Model A = 1.2 resource units, 1 call of Model B = 0.8 resource units). This design not only avoids initial selection difficulties but also ensures efficient resource utilization.
Help and Support
Was this page helpful?
You can also Contact sales or Submit a Ticket for help.
Help us improve! Rate your documentation experience in 5 mins.
Feedback