This document details the implementation principles of distributed transactions in TDSQL Boundless and explains how data affinity scheduling optimizes transaction performance.
Distributed Transaction Principles
Overview of Transaction Models
Distributed transaction design aims to ensure both correctness and efficiency. TDSQL Boundless has comprehensively optimized the read/write operations and commit pathways of transactions.
Read/Write Phase
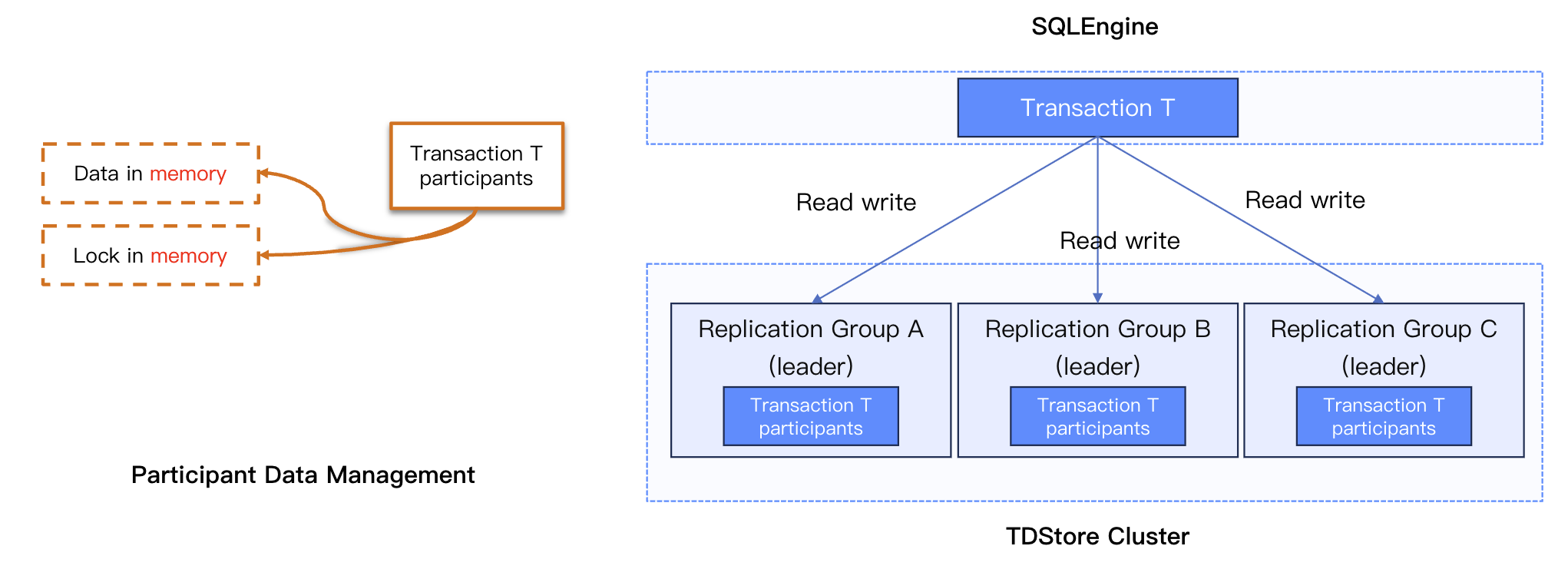
Participant Management Mechanism
Replication Group as the Unit: Manages transaction participants with the Replication Group as the fundamental unit.
Automatic Context Creation: Automatically creates corresponding participant contexts when a transaction accesses data in a specific Replication Group.
Distributed Caching: The SQLEngine layer does not cache transaction data; instead, TDStore implements distributed caching.
Transaction Execution Flow
1.
Obtain Read Timestamp: When the transaction executes the first statement, it obtains a timestamp from MC as the read snapshot.
2.
Read/Write Operations: Access the Leader replica of the Replication Group corresponding to the data and create a participant context on that replica.
3.
Transaction Commit: Select one participant to act as the coordinator and send a commit request to the coordinator.
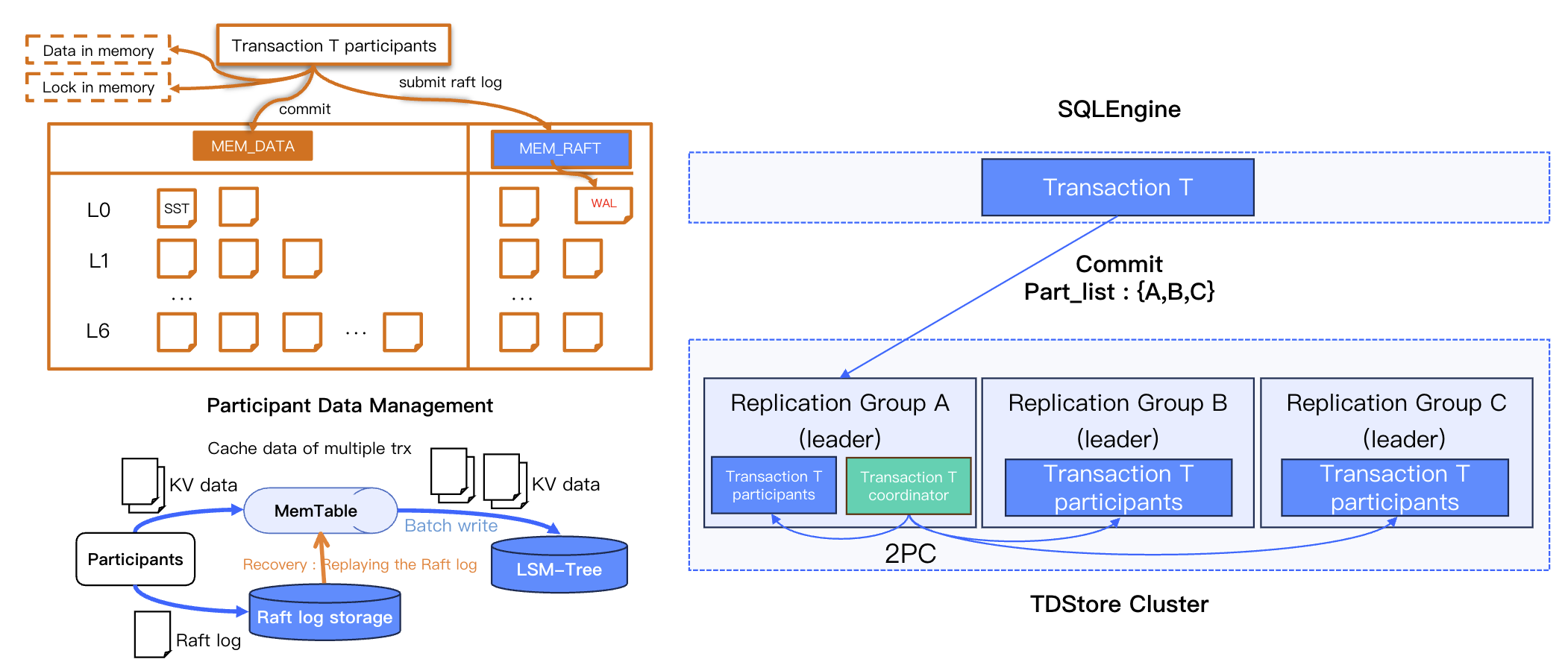
Data Caching Mechanism
Feature
Description
Pre-Commit Caching
Transaction data is fully cached in memory before commit.
SQLEngine Does Not Cache
The SQLEngine layer does not cache transaction data.
Distributed Caching
TDStore implements distributed caching.
Persistence on Commit
Data persistence is performed only during the transaction commit phase.
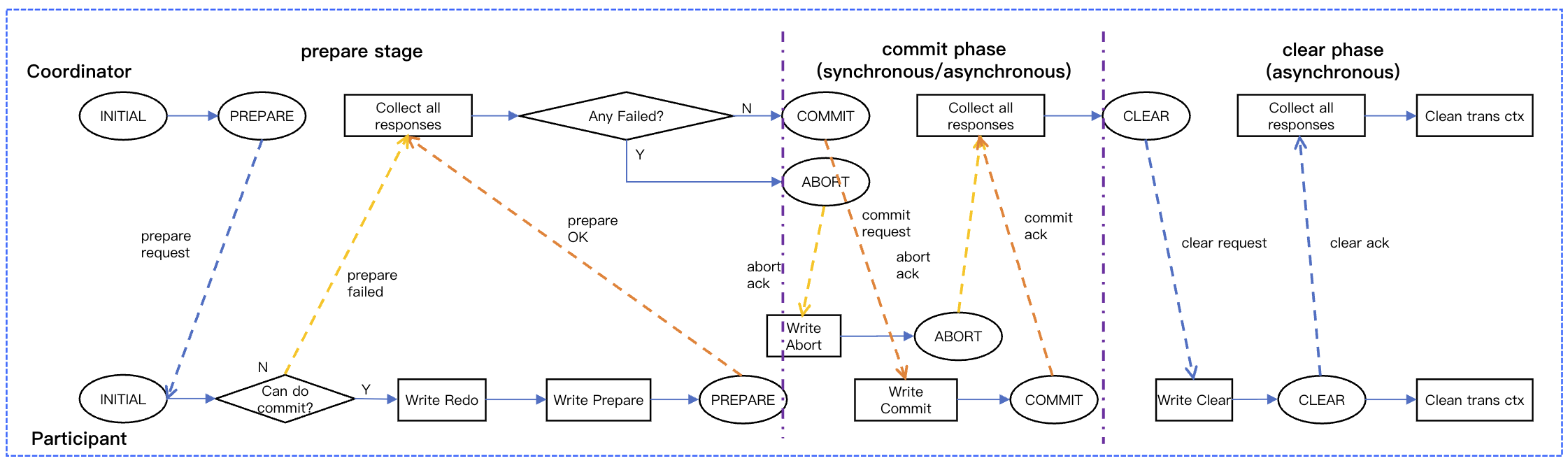
commit phase
2PC Offloading
TDSQL Boundless completely offloads the implementation of 2PC to the TDStore layer, and the SQLEngine is unaware of the transaction commit process.
Commit Process:
1.
When a distributed transaction is submitted, the SQLEngine selects one of the participants as the coordinator.
2.
Send a commit request to the selected participant node, which contains a list of all participants involved in the transaction.
3.
The node receiving the request creates a coordinator context within its replication group.
4.
The coordinator is responsible for sending read/write requests to other participants and driving the complete 2PC process.
Data Persistence
TDStore directly uses Raft log as the WAL; writing data to the LSM-Tree does not require an additional WAL:
1.
Upon node restart, replay the Raft Log from the last recorded point.
2.
After data is flushed to disk, advance the log position to reduce the amount of logs that need to be replayed during a crash.
3.
A single Log achieves both data synchronization for standby machines and failure recovery features.
Log-based vs. Negotiation-based 2PC
TDSQL Boundless adopts collaborative 2PC, offering significant advantages over traditional logging-based 2PC:
Item
logging-based 2PC
Collaborative 2PC (TDSQL Boundless)
RPC Rounds
2 rounds (prepare, commit)
3 rounds (prepare, commit, asynchronous clear)
Log Synchronization Count
Participant 2 times + Coordinator 3 times = 5 times
Participants synchronize 3 times (including 1 asynchronous).
Troubleshooting
After a crash restart, both the participants and coordinator can independently determine the transaction's final state by replaying their local logs.
After a crash restart, participants can determine the state by replaying local logs; the coordinator needs to determine the state based on messages received from participants.
Core Advantage:
Using collaborative 2PC to avoid the overhead of the coordinator's log synchronization.
Ensuring atomicity of transactions across Replication Groups.
The number of log synchronizations is reduced from 5 to 3.
data affinity scheduling
Affinity Definition
Data Affinity: There exists correlation between data items, for example:
Primary keys and secondary indexes within a table
Join keys between different tables
Scheduling related data to the same replication group enables transaction optimization.
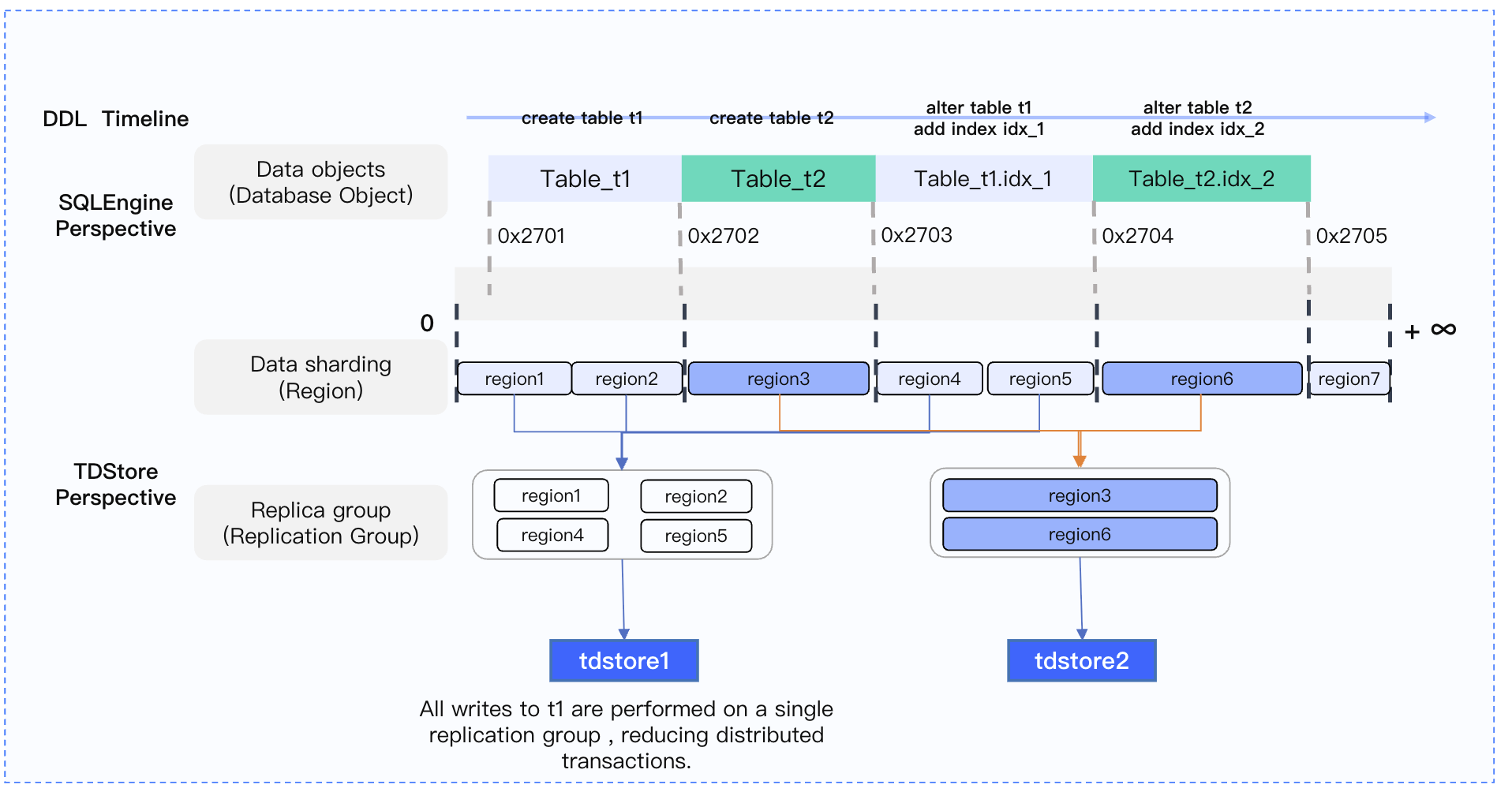
Typical Case: Affinity within a Table
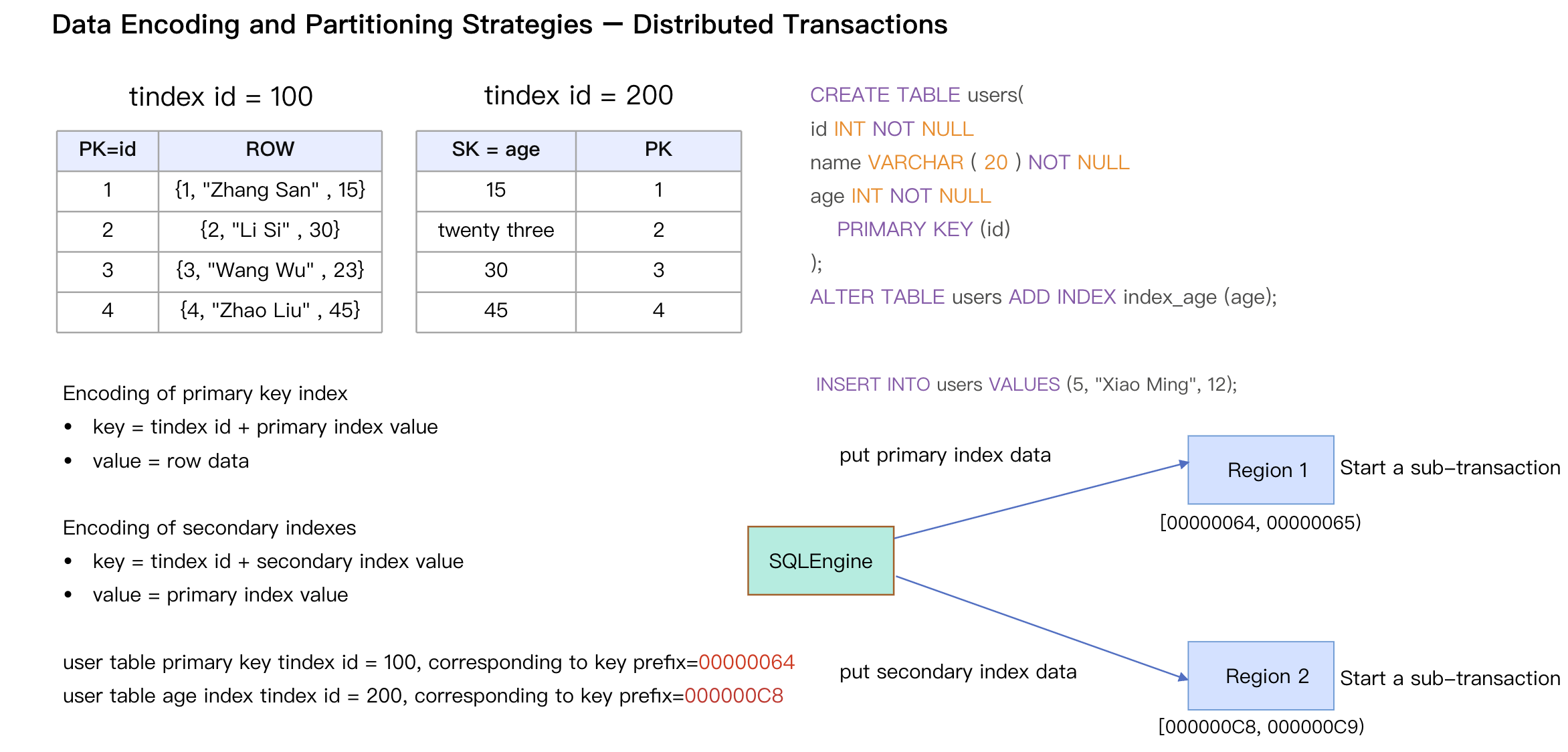
Scenario: The user creates a table containing ID, name, and age columns, and creates a secondary index on the age column.
Problems with Traditional Solutions:
The key ranges of primary key indexes and secondary indexes are far apart.
Distributed transactions must be completed via 2PC.
Transaction execution efficiency is significantly lower than that of single-machine transactions.
TDSQL Boundless Optimization Solution:
Place related data (primary keys and secondary indexes) in the same replication group.
Read and write queries only need to send requests to the target replication group.
Transaction commits only need to interact with a single replication group.
The 1PC protocol significantly improves transaction processing efficiency.
Data-aware scheduling
Typical Case Studies:
1.
The user creates a table containing ID, Name, and Age columns (Table ID: 100).
2.
Create a secondary index on the age column (index table ID: 200).
3.
The primary key index key prefix is 00000064, and the secondary index key prefix is 000000C8; their key ranges are far apart.
Typical Case: Cross-Table Affinity
Scenario: Small data volume merchant balance account tables coexist with large data volume merchant transaction account tables.
Data Growth Processing Flow:
1.
Initial State: Two tables coexist on the same node.
2.
Data Growth: Tables begin to automatically split Regions (at different speeds).
3.
Ensure Correlation: Perform automatic splitting of Table 2's Regions and split the replication groups accordingly.
4. Data Range Alignment: RG1 manages data range 0-5; RG2 manages data range 5-9.
5. When load increases: RG2 is migrated to other nodes to achieve data splitting while ensuring affinity.
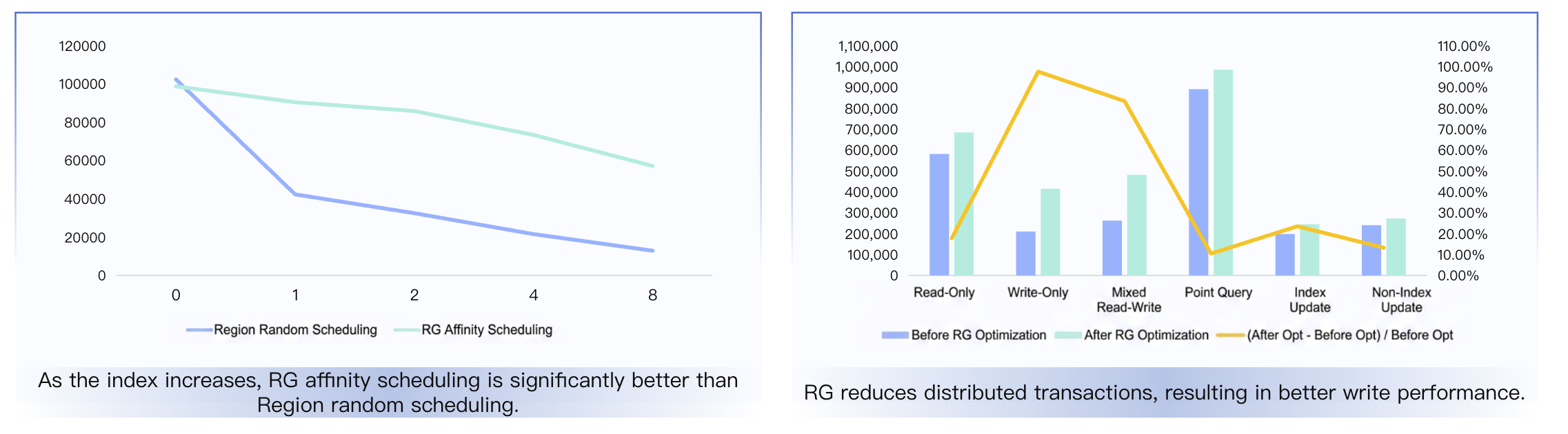
Affinity Benefits Summary
Benefits
Description
Data Localization
Data frequently accessed together is stored on the same node.
Reduce RPC
Read and write operations entail less data movement and fewer RPC calls.
Avoid Distributed Transactions
Operations within a single replication group require no 2PC.
Significantly Improve Performance
Significantly reduces latency and network overhead.