This document introduces the architectural design of the TDSQL Boundless scheduling engine (MC) and its data-aware capabilities.
Overview
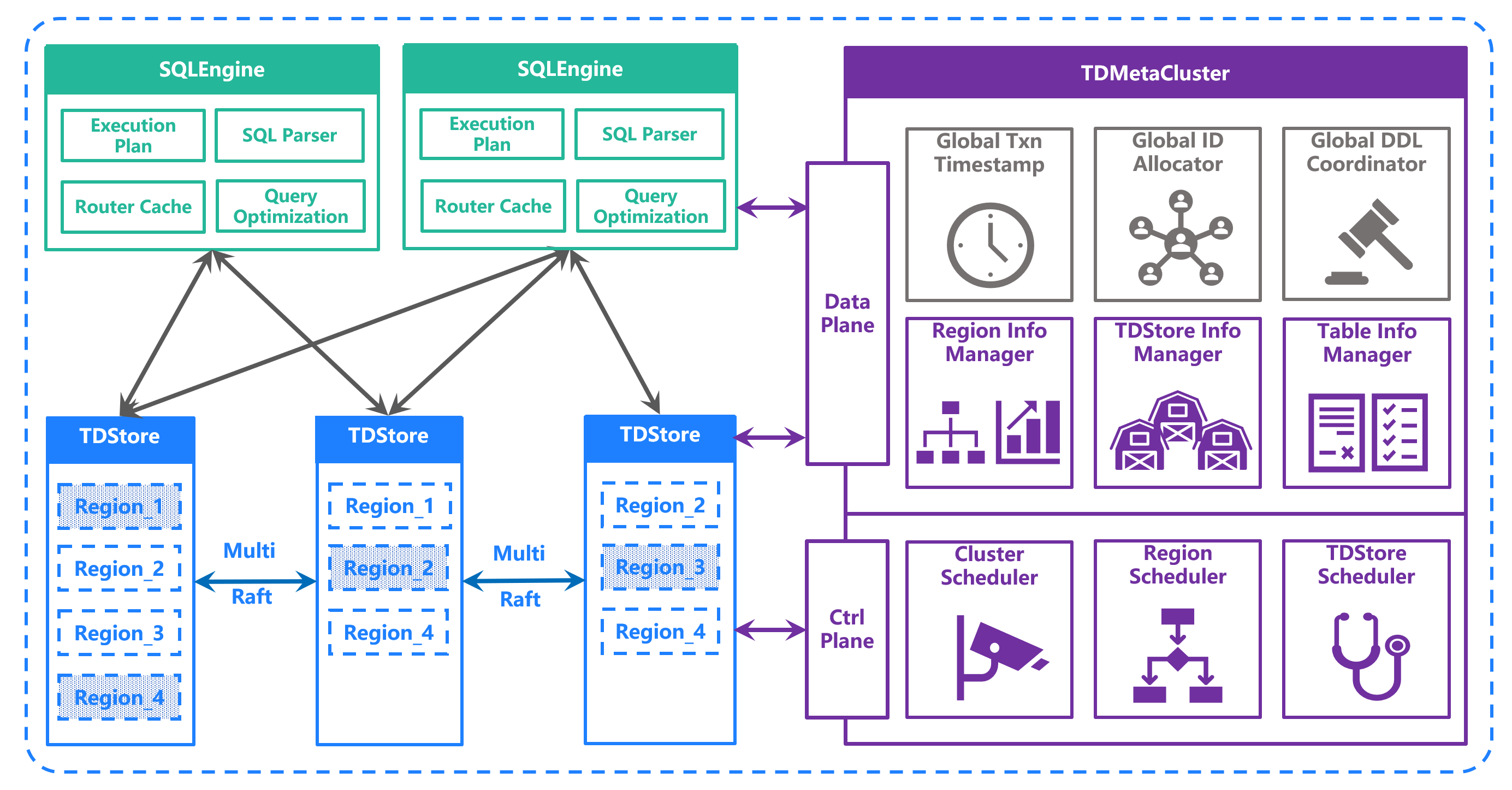
The scheduling engine (MC, Management Center) is the "brain" of TDSQL Boundless, responsible for all functions of the control plane (Ctrl Plane), including monitoring, decision-making, and scheduling. It enables the compute engine and storage engine to focus on data flow-related operations and performance optimization.
Architecture Design
control plane and data plane separation
TDSQL Boundless implements the Data/Ctrl Plane Separation architecture:
core value:
Clear responsibilities and simple architecture
Compute/storage engines focus on data flow operations and performance optimization.
MC handles all control plane features.
atomic scheduling design
Issue Background
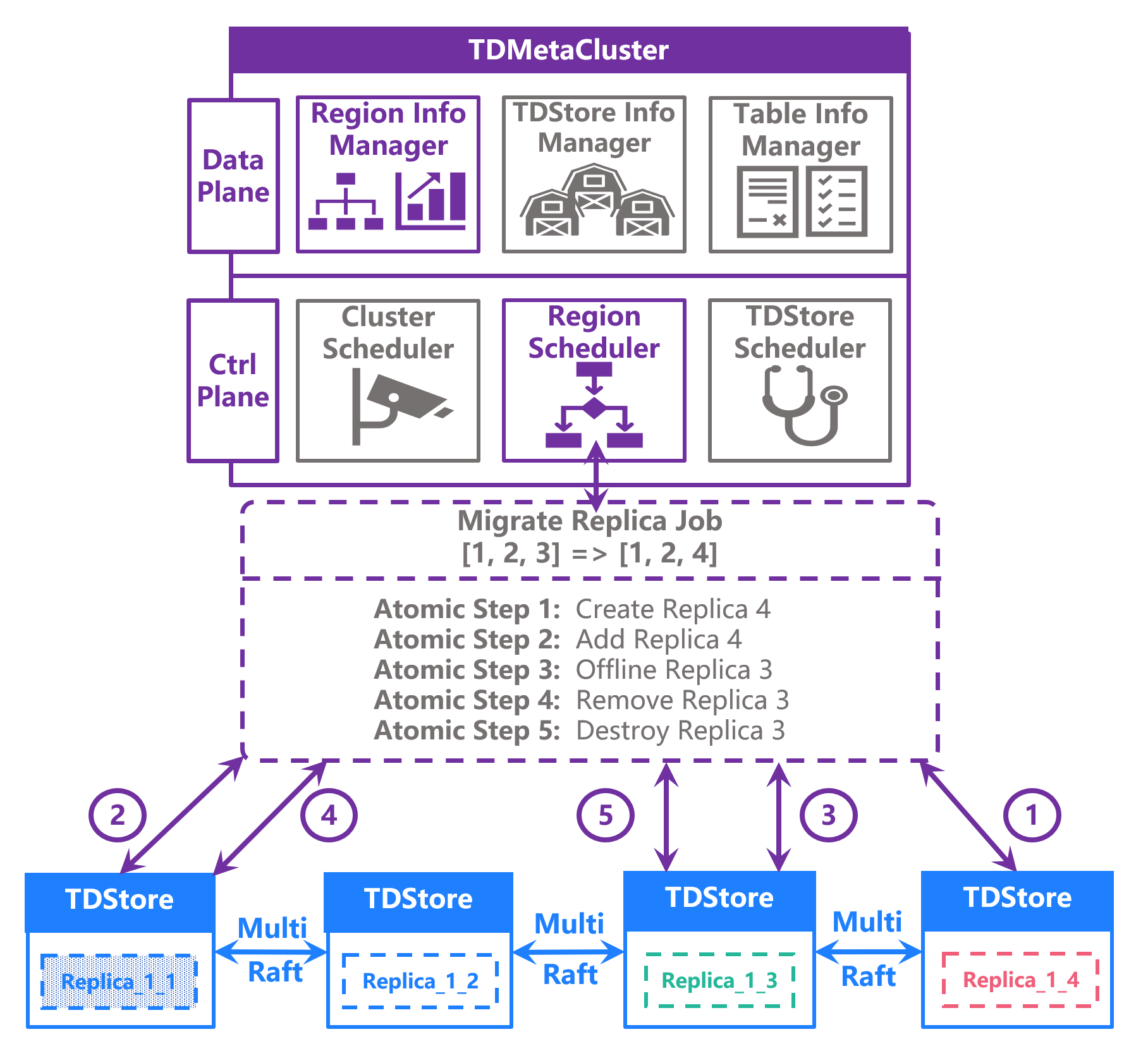
The scheduling engine needs to handle complex tasks such as cross-node migration of data shards (Region). Such tasks appear as a single operation from a business perspective but involve multiple substeps internally.
If scheduling coordination logic is placed in the storage layer, it will cause problems:
Excessive logic: The storage layer needs to handle both data reads/writes and complex scheduling logic.
State confusion: Task progression, pause, and rollback are determined by the executors themselves, making consistency difficult to guarantee.
Solution Effect
Move complex scheduling logic up to the scheduling engine (MC):
Fine-grained locks at the Region level, decoupling the state of Regions from the state of scheduling Jobs.
MC defines the complete set of Atomic Step state machines, where each Job consists of one or more Atomic Steps.
The Region layer of TDStore will receive and execute at most a single Atomic Step at any given time.
TDStore is unaware of Job progress or rollback, with normal progress or rollback entirely handled by MC.
Replica Migration Job Example
A RegionGroup (RG) Replica Migration Job can be broken down into the following five atomic steps:
1.
Create: Establish a new replica on the target node.
2.
Add: The new replica synchronizes data from the primary replica.
3.
Offline: Take the old replica offline.
4.
Remove: Modify the Raft group configuration to remove the old node.
5. Destroy: Clean up replica data on the old node.
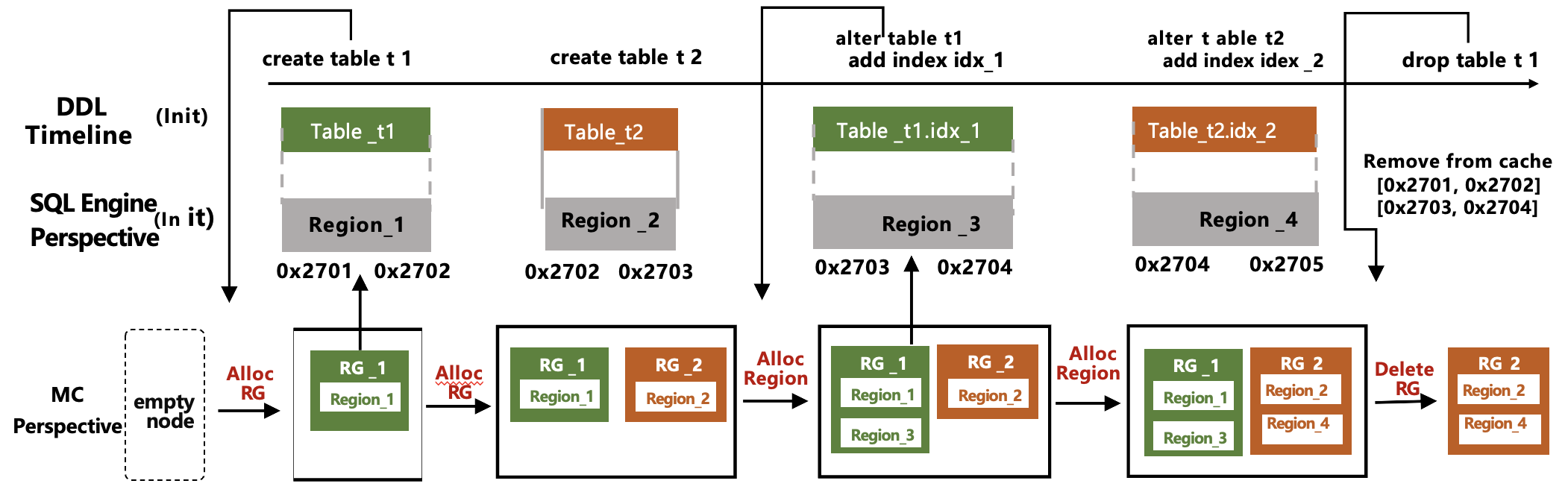
Data awareness capability
Topology-aware lifecycle management of data objects
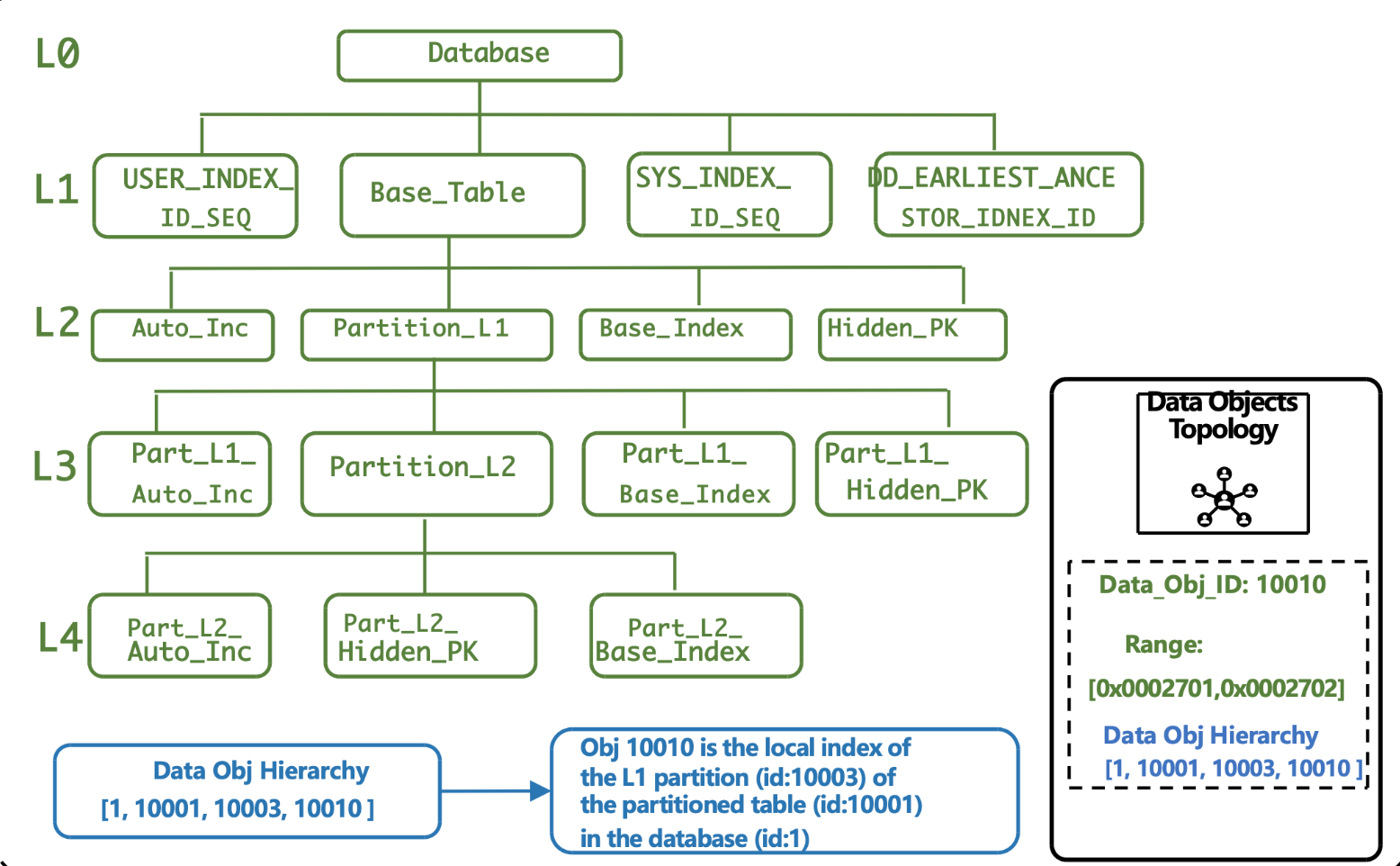
The control and scheduling engine establishes a topology-aware data object management system based on the DataObject abstraction, bridging the linkage between the logical data layer and the physical storage layer.
Topology Structure Hierarchy Definition:
L0 Level: Database (Database)
L1 Level: Table (Table), belonging to a specific Database.
L2 Level: Index/Partition (Index or Partition), belonging to a specific Table.
core value:
Enables precise location of the logical ownership for each data object.
Enables awareness of affinity relationships between data.
Enables placement of closely associated data on the same or adjacent storage nodes.
Reducing cross-node data access and lowering the proportion of distributed transactions
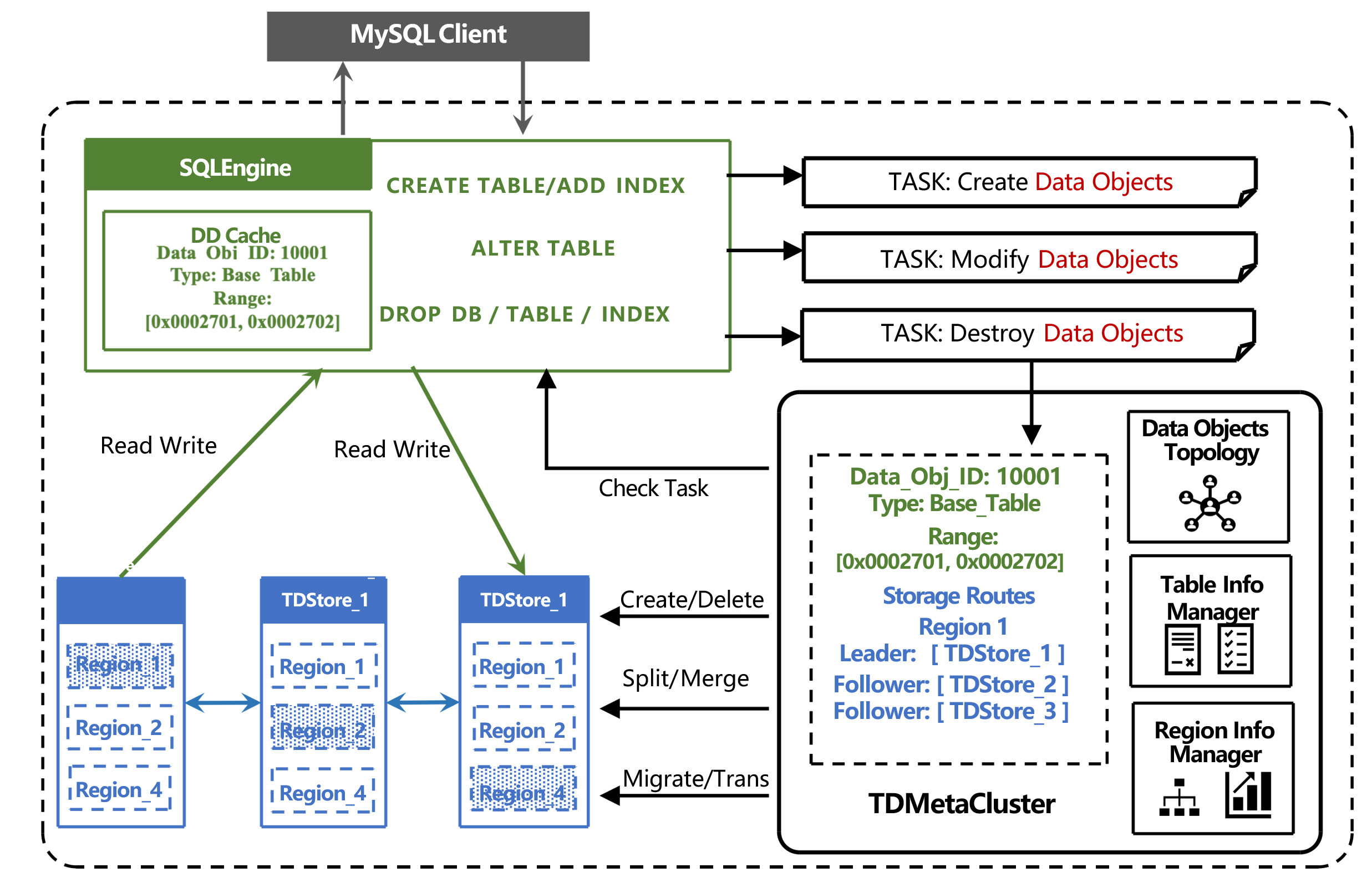
On-Demand resource allocation mechanism
Unlike competitors that simply partition by range when regions become too large, TDSQL Boundless introduces the On-Demand Allocation Mechanism:
Feature
Description
On-Demand Resource Allocation
When DDL is executed, Regions are requested on demand based on the logical meaning and affinity relationships of data objects.
Affinity-Driven Scheduling
Identifying data shards that should be placed together, and scheduling indexes and primary table data to the same node.
Two-Tier Metadata Management
Based on the two-tier structure of ReplicationGroup + Region, supporting the split and merge of arbitrary data shards.