This document details the elastic scaling mechanism and CLB policy of TDSQL Boundless.
Auto Scaling
Scaling Overview
One of the core features of TDSQL Boundless is to achieve business-unaware scaling, ensuring that business requests are not affected by performance jitter during the scaling process.
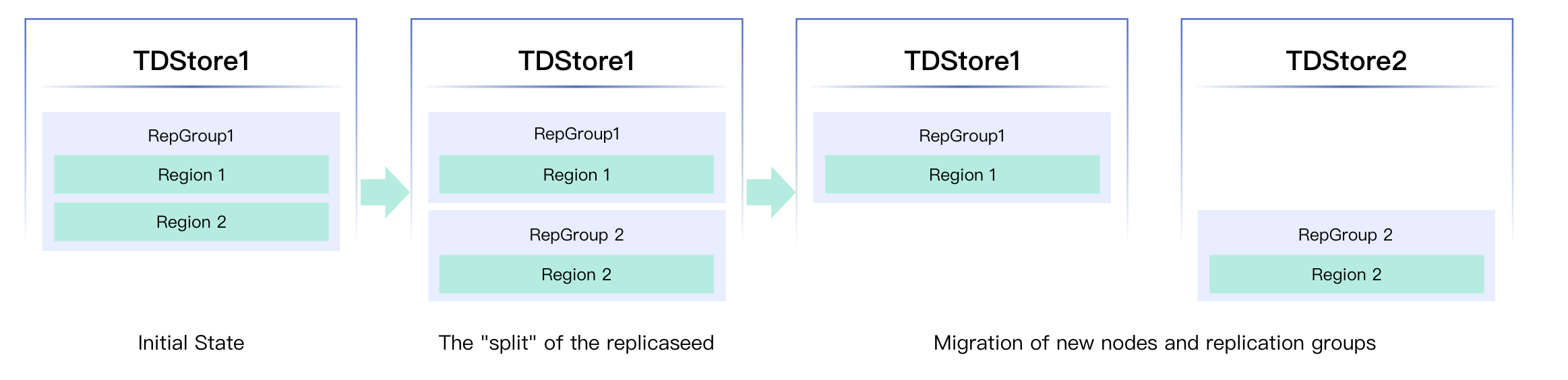
Scaling is the reconfiguration of the relationships among data shard - replication group - physical node:
Change Type
Specific events
Data logical relationship changes
The split and merge of Regions
The transfer of Regions on RGs
RG Creation and Deletion
Data physical relationship changes
RG Migration (Member Change)
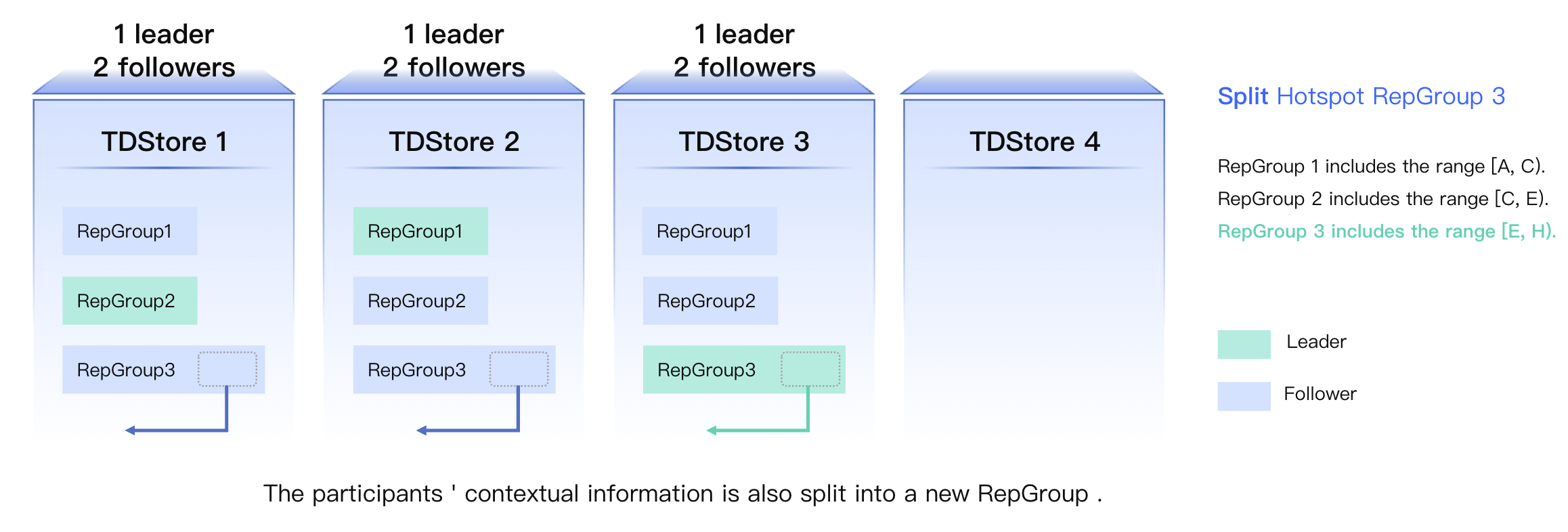
Split operation
Split is to divide a single Replication Group into two, each managing a portion of the data before the split.
Split Process:
1. Initial State: RG3 with large data volume exists on TDStore1, 2, and 3, and a new TDStore4 node is added.
2.
Replication Group Split: Allocate a portion of Key Range Regions to a new RG and establish a new Raft Group.
3.
Split Completed: Each RG handles a portion of the pre-split load.
Split Characteristics:
Replication group splitting is performed only in the upper-level logic module.
The underlying KV data has not undergone physical changes.
The impact on system IO is relatively limited.
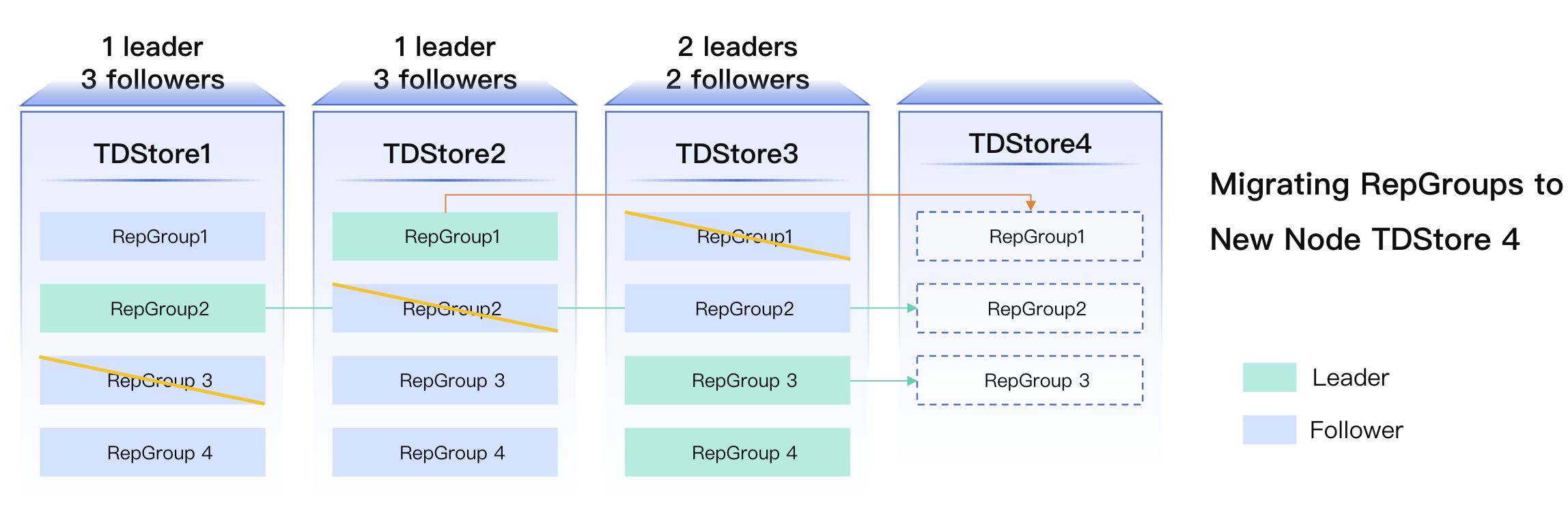
Migration Operation
Migration refers to the process of transferring a follower replica of a Raft Group to a new node.
Migration Process:
1.
Create a new replica for the replication group to be migrated on the target node.
2.
The Leader executes the install snapshot process to synchronize the complete RG data to the new replica.
3.
Delete the old replica to be migrated (using the "add first, then remove" policy).
core value:
Data Dispersion: Achieves balanced distribution of data across different TDStore nodes.
Read-Write Transparency: The creation and destruction of followers do not affect the Leader's normal read-write operations.
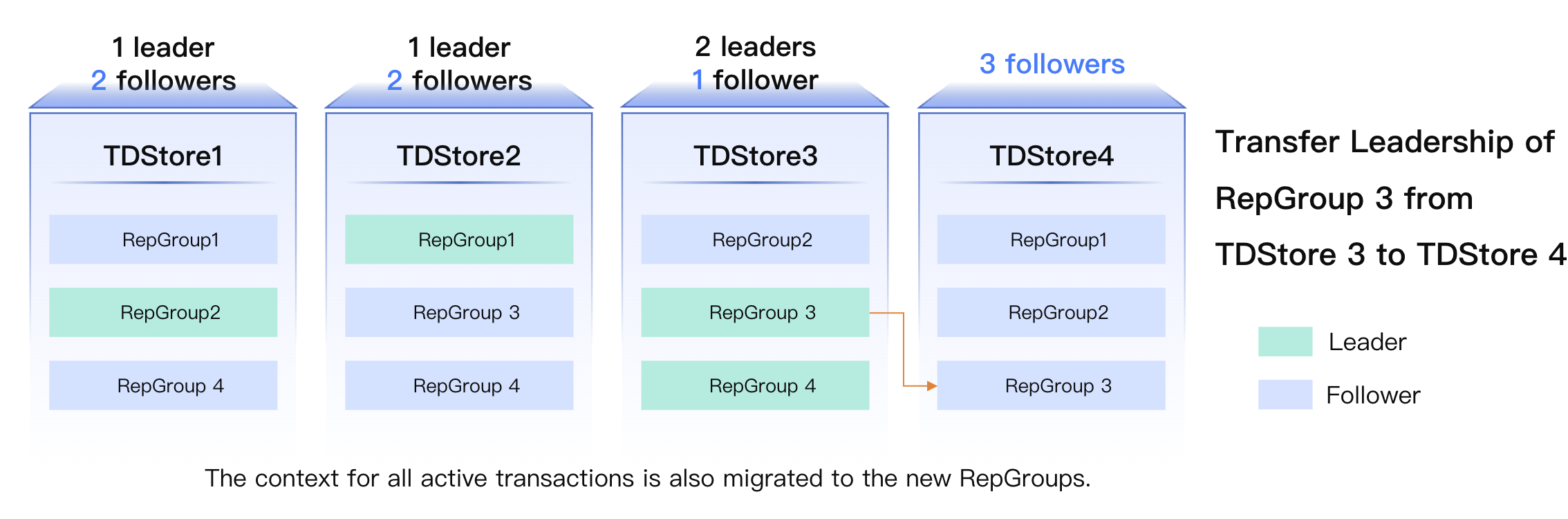
Leader switch operation
Leader Switch refers to the process of transferring the Leader role to another Raft replica within a Raft Group.
Leader Switch Process:
1.
Transaction Information Pre-synchronization: Send the context information of unfinished active transactions from the original Leader to the target node in advance.
2.
Raft-layer Leader Switch: After transaction information synchronization is completed, the formal Leader switch operation is triggered.
Core Objective: Achieve load balancing by distributing Leader hotspots.
Guarantee: Pre-synchronization of transaction information ensures that no ongoing transactions will be terminated during the Leader Switch process.
CLB
CLB and Data Affinity Collaboration
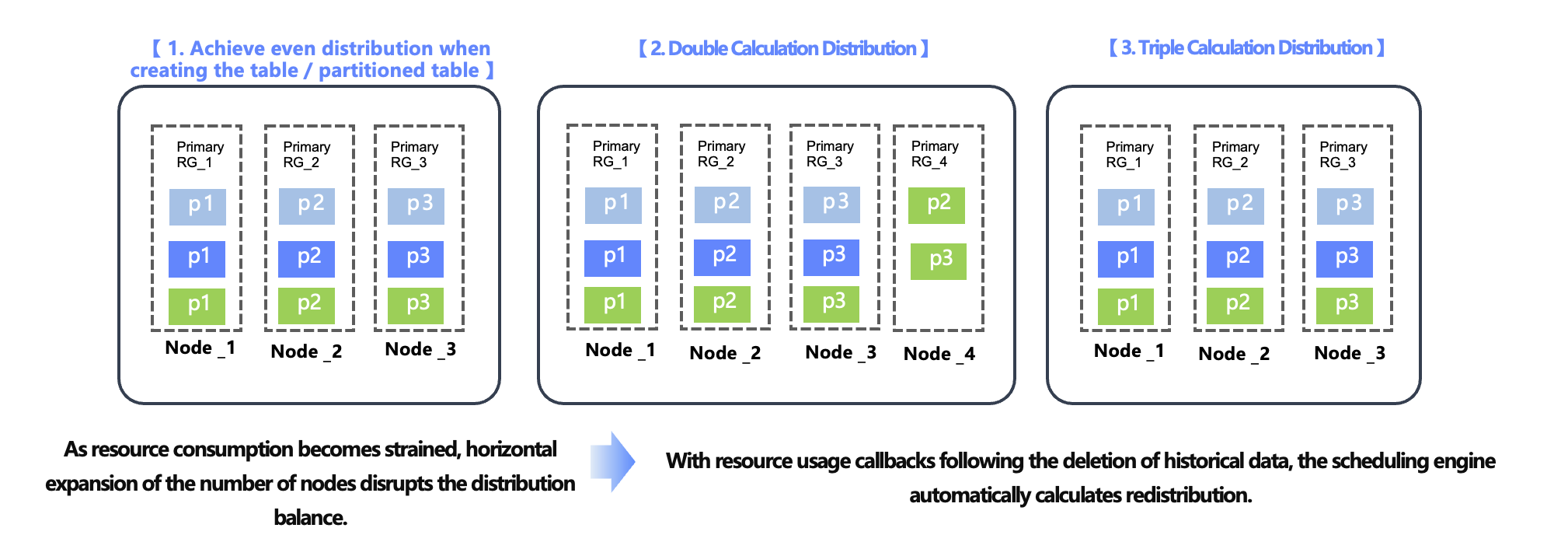
MC implements the Coordinated Scheduling Mechanism for Load Balancing and Data Affinity:
Coordinated Scheduling Process:
1.
Initial Distribution Policy: Uniform distribution principle, Leader balancing, replica balancing.
2.
Dynamic Scaling-out Awareness: Calculating the capacity of newly added nodes, reevaluating distribution balance, and migrating partial data shards.
3.
Continuous Optimization Mechanism: Periodically recalculating data distribution and performing incremental optimization.
4.
Extreme Scenario Handling: When data skew is too high, split table data and perform replica relocation.
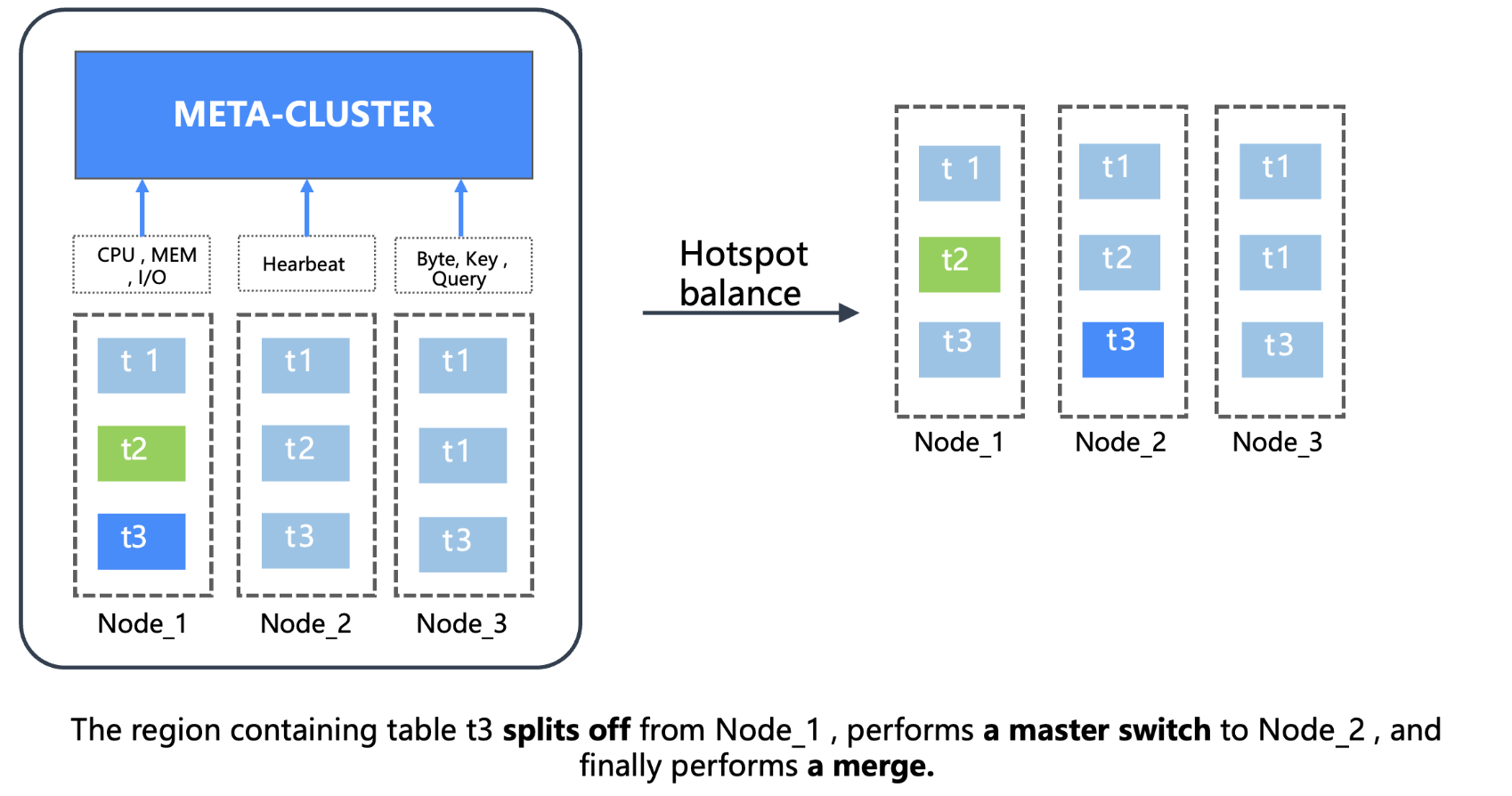
2.2 Hotspot Detection and Intelligent Scheduling
MC implements an intelligent hotspot detection and load balancing system:
Hotspot Detection Mechanism:
1.
Real-time Data Reporting: Node heartbeat reports basic information and Region-level read/write traffic statistics.
2.
Multi-dimensional Load Status: MC maintains Multi-TopN records (Byte/Key/Query dimensions).
3. Intelligent Scheduling Algorithm: Based on MovingAverage to avoid impact loads, calculating heat scores to select optimal distribution.