ノードプールの概要
Download
フォーカスモード
フォントサイズ
概要
Kubernetesクラスター内のノードの管理効率を上げるため、Tencent Kubernetes Engine(TKE)はノードプールのコンセプトを導入しました。ノードプールの基本機能を利用することで、ノードの作成、管理、破棄が、より簡単に素早くなり、ノードのダイナミックスケーリングを実現しました。
人的コスト削減のため、クラスターでリソース不足によりインスタンス(Pod)のスケジューリングができない場合は、自動でスケーリングをトリガーします。
リソースコスト削減のため、ノードアイドルなどのスケーリング条件が揃った場合には、スケーリングを自動でトリガーします。
製品アーキテクチャ
ノードプール全体のアーキテクチャ図は次のとおりです。
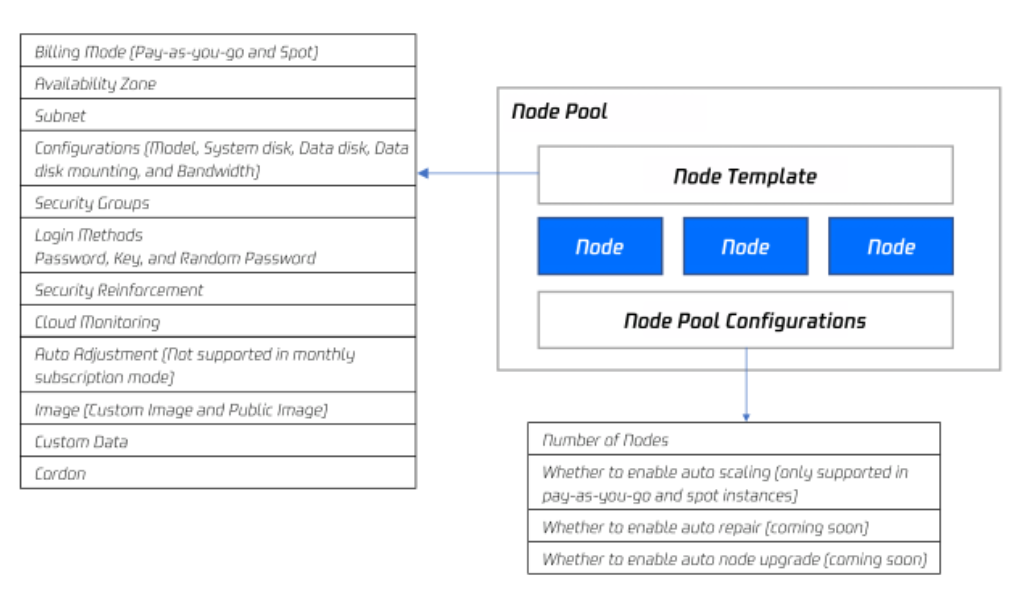
通常の状況では、ノードプール内のノードはすべて次のような同一属性を有しています。
ノードオペレーティングシステム。
課金タイプ(現在は従量課金とスポットインスタンスをサポートしています)。
CPU/メモリ/GPU。
ノードKubernetesインスタンスの起動パラメータ。
ノードのカスタマイズ起動スクリプト。
ノードのKubernetes LabelおよびTaintの設定。
この他、TKEはノードプールについて、同時に次の機能を展開します。
CRDを用いたノードプールの管理をサポートします。
ノードプールレベルの各ノードのPod数の上限。
ノードプールレベルの自動修復および自動アップグレード。
ユースケース
業務で大規模なクラスターの使用が必要な場合は、大規模なクラスターの使いやすさを高めるため、ノードプールを利用したノード管理をお勧めします。次の表では、複数の大規模クラスターの管理ケースについて説明します。ノードプールが各ケースで発揮するそれぞれの機能を表示します。
シーン | 機能 |
クラスターには多くの異種ノード(モデルコンフィグレーションが異なります)が存在しますが | ノードプールを介してノードのグループ管理をルール化できます。 |
クラスターは頻繁にノードのスケーリングを行う必要がありますが | ノードプールによって運用効率を高め、人的コストを削減することができます。 |
クラスター内のアプリケーションプログラムのスケジューリングルールは複雑ですが | ノードプールのタグにより指定業務のスケジューリングルールを素早く指定できます。 |
クラスター内ノードの日常のメンテナンス | ノードプールによりKubernetesバージョンアップ、Dockerバージョンアップの操作が簡単にできます。 |
関連概念
TKEの自動スケーリングは、Tencent Cloud自動スケーリング(AutoScaling)および Kubernetesコミュニティの cluster-autoscaler によって実現します。関連コンセプトの説明です。
CA:cluster-autoscalerは、コミュニティオープンソースコンポーネントです。主にクラスターの自動スケーリングを行います。
AS:AutoScalingは、Tencent Cloudの自動スケーリングサービスです。
ASG:AutoScaling Groupは、いずれかの具体的なノードプール(ノードプールは自動スケーリングサービスが提供するスケーリンググループに依存します。ノードプール1つにつき1つのスケーリンググループに対応しますので、ノードプールのみに注目してください)です。
ASA:AS activityは、いずれかの回のスケーリングイベントです。
ASC:AS configは、ASの起動設定、つまりノードテンプレートです。
ノードプール内のノードの種類
異なるシーンでのニーズに応えるため、ノードプール内のノードは2つのタイプに分けられます。
説明:
特殊なシーンがない場合は、既存のノード機能の追加使用はお勧めしません。例えば、ノードの権限を新しく作成せず、既存のノードを介してのみクラスターをスケールアウトする場合は、既存のノードの一部パラメータを追加することで、あなたが定義したノードのテンプレートとの不一致がおこり、自動スケーリングに参加できなくなる可能性があります。
ノードのタイプ | ノードのソース | 自動スケーリングをサポートしているかどうか | ノードプールからの削除方式 | ノード数が数量の調整の影響を受けるかどうか |
スケーリンググループ内のノード | 自動スケールアウトあるいは手動での数量調整 | はい | 自動スケールインあるいは手動での数量調整 | はい |
スケーリンググループ外のノード | ユーザーが手動でノードプールに参加 | いいえ | ユーザーが手動で削除 | いいえ |
ノードプールの自動スケーリングの原理
ノードプールの自動スケーリング機能をご利用になる前に、原理についての次の説明にしっかり目を通してください。
ノードプールの自動スケールアウトの原理
1. クラスターがリソース不足(クラスターの計算/ストレージ/ネットワークなどリソースがPodのrequest/親和性のルールを満たしていない)の場合は、CA(Cluster Autoscaler)が、スケジューリングができずにPendingしているPodをモニタリングします。
2. CAは、各ノードプールのノードテンプレートに基づいてスケジューリング判断を行い、適切なノードテンプレートを選択します。
3. 複数のテンプレートが適していた場合、つまり複数の拡張可能なノードプールが選択肢となった場合、CAは expanders を呼び出してその中から最適なテンプレートを選択し、対応するノードプールに対してスケールアウトを行います。
4. 指定のノードプールに対してスケールアウト(複数のサブネット/モデルポリシーに基づく)を行い、2種類のリトライポリシー(ノードプールの作成で設定できます)を提供します。スケールアウトに失敗した場合は、ご自身で設定されたリトライポリシーに基づいてリトライします。
説明
特定のノードプールにスケールアウトを行う場合は、ご自身で作成されたノードプールのサブネットおよびその後で設定した複数のモデルコンフィグレーションでスケールアウトを行うことをお勧めします。通常の状況では、先に複数モデルのポリシーを保証し、次にマルチアベイラビリティーゾーン/サブネットのポリシーを保証します。
例えば複数のモデルA、B、複数のサブネット1、2、3を設定すると、A1、A2、A3、B1、B2、B3に基づいてトライします。A1が完売している場合は、B1ではなくA2でトライします。
ノードプールの自動スケールアウトの原理は、次の図のとおりです。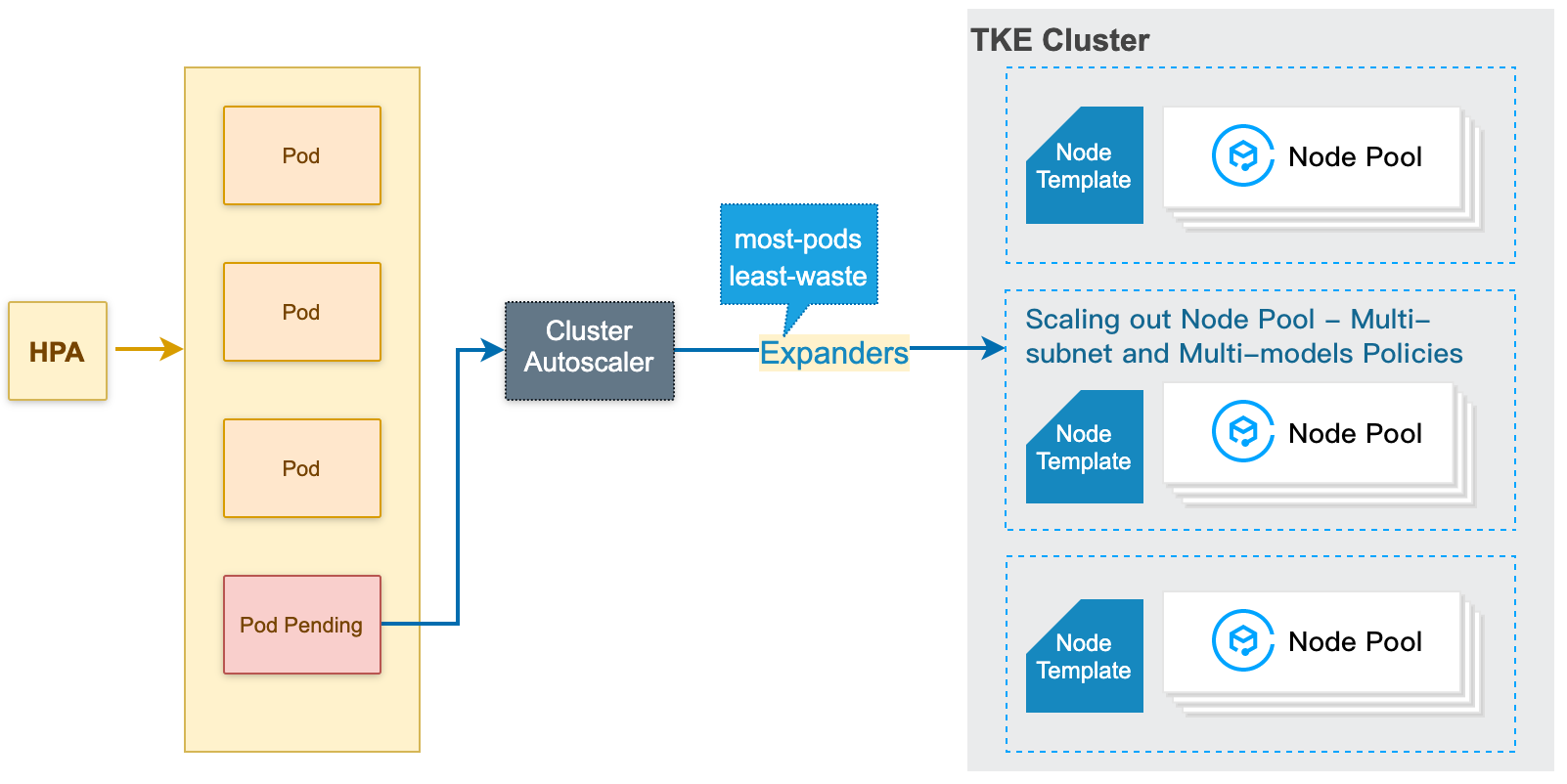
ノードプールの自動スケールインの原理
1. CA(Cluster Autoscaler)がモニタリングした分配率(つまりRequest値は、CPU分配率とMEM分配率の最大値を取ります)は、設定のノードを下回ります。分配率を計算する際に、Pod占有リソースにDaemonsetタイプが計算されないよう設定できます。
2. CAは、クラスターの状態がスケールインにトリガーできるかどうかを判断します。それには次の要件を満たす必要があります。
ノードのアイドル時間についての要求(デフォルトでは10分)。
クラスターのスケールアウトのバッファ時間についての要求(デフォルトでは10分)。
3. CAはこのノードがスケールインの条件に合致しているかどうかを判断します。必要に応じて次のスケールインしない条件(条件を満たすノードはCAによってスケールインされません)に従って設定できます。
ローカルストレージのノードを含みます。
Kube-system namespaceを含み、DaemonSet管理でないPodのノード。
説明
上記のスケールイン条件はクラスター次元で有効化します。さらに細かい粒度でノードを守りスケールインを避ける場合は、スケールインの保護機能が利用できます。
4. CAはノード上のPodをドレイン後に、ノードをリリース/シャットダウンします。
ノードが完全にアイドル状態になると、スケールインの同時実行が可能になります(スケールインの最大同時実行数が設定できます)。
完全なアイドル状態でないノードは個別にスケールインします。
ノードプールの自動スケールインの原理は、次の図のとおりです。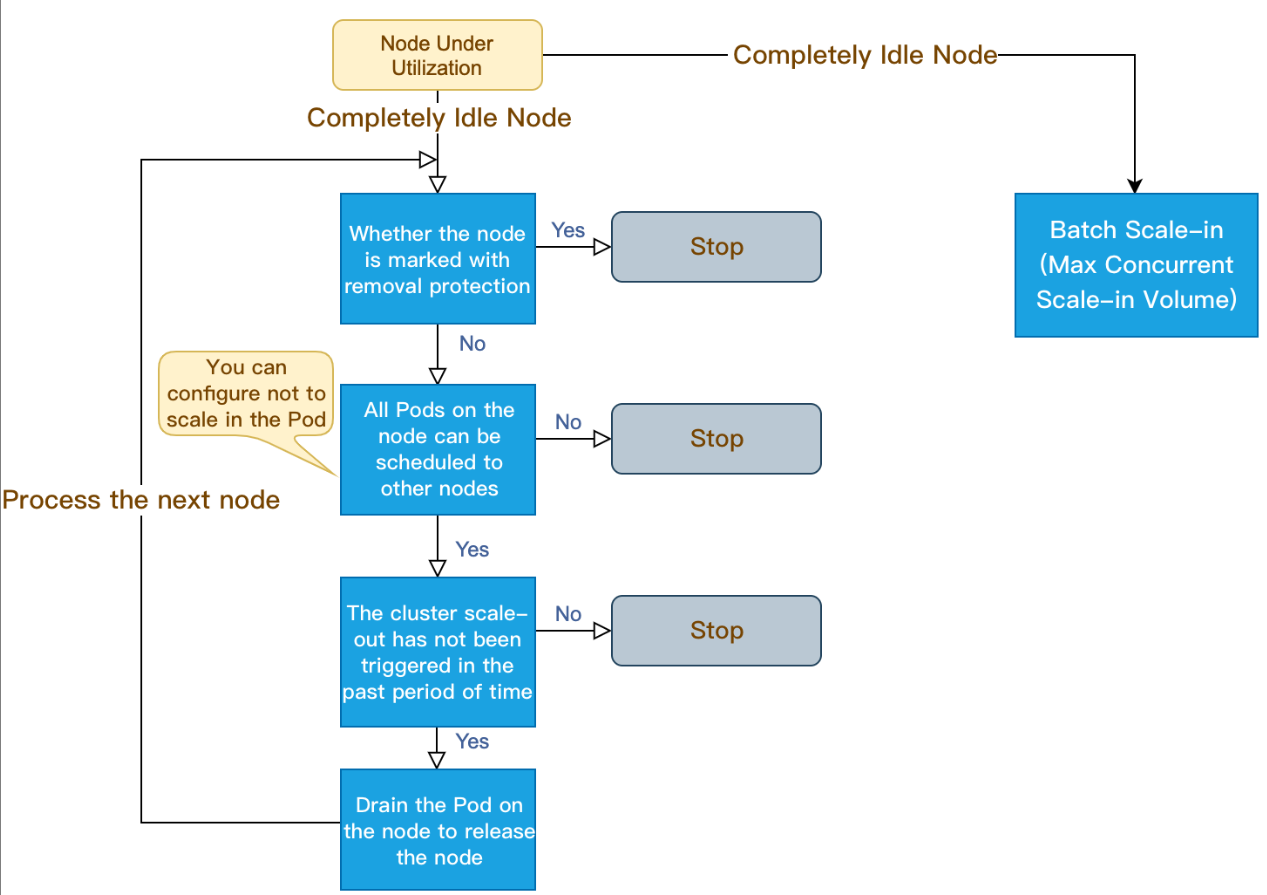
機能点および注意事項
機能点 | 機能説明 | 注意事項 |
ノードプールの追加 | 単一クラスターではノードプールが20を超えることをお勧めしません。 | |
ノードプールを削除する際、ノードプール内のノードを破棄するかどうかの選択ができます。 ノードを削除した場合もしない場合も、ノードはクラスター内では保持されません。 | ノードプールを削除する際、破棄するノードを選択するとノードは保持されなくなります。後から新しいノードの使用が必要になった場合には、再度作成ができます。 | |
ノードプールの自動スケーリングの開始 | 自動スケーリングをオンにすると、ノードプール内のノード数はクラスターの負荷状況に従って自動調整されます。 | スケーリンググループコンソールでは、自動スケーリングのオン/オフを行わないでください。 |
| ノードプールの自動スケーリングの終了 | 自動スケーリングをオフにすると、ノードプール内のノード数はクラスターの負荷状況に従わずに自動調整されます。 |
ノードプールのノード数の調整 | ノードプール内のノード数の直接調整をサポートします。 ノード数を減らす際は、ノード退出ポリシー(デフォルトでは最も古いノードを退出)に従い、スケーリンググループ内からノードをスケールインします。このスケールイン動作はスケーリンググループにより行われるため、TKEは具体的なスケールインノードを関知できず、事前に動作のドレイン/ブロックができませんのでご注意ください。 | 自動スケーリング開始後は、ノードプールサイズの手動調整をお勧めしません。 スケーリンググループコンソールでは、スケーリンググループの希望インスタンス数の直接調整をしないでください。 特殊な状況でないかぎり、ノードプールでは自動スケールインを使用し手動でのスケールインはしないでください。自動スケールインでは、まずノードマーカーをスケジューリングできなくしてから、ノード上のすべてのPodをドレインあるいは削除し、その後ノードの再リリースを行います。 |
ノードプールの名称、オペレーティングシステム(OS)、スケーリンググループのノード数範囲、Kubernetes labelおよびTaintの変更が可能です。 | LabelおよびTaintを変更すると、ノードプール内のノードすべてが有効化され、Podが再度スケジューリングされる可能性がありますので、慎重に変更してください。 | |
既存ノードの追加 | クラスターに属さないインスタンスをノードプールに追加することができます。その要件は次のとおりです。 インスタンスとクラスターが同一のVirtual Private Cloudに属していること。 インスタンスがその他クラスターで使用されておらず、かつインスタンスとノードプールの設定が同一モデル、同一課金モデルであること。 クラスター内のどのノードプールにも属していないノードを追加できます。ノードインスタンスとノードプールの設定は同一モデル、同一課金モデルであること。 | 特殊な状況でないかぎり、既存ノードの追加はお勧めしません。ノードプールを直接新規作成されることを推奨します。 |
ノードプール内ノードの削除 | ノードプール内の任意のノードの削除をサポートします。削除時、ノードをクラスター内に保留するかどうかの選択ができます。 | スケーリンググループコンソールでは、スケーリンググループ内にノードを追加しないでください。データの不一致により重大な影響が生じる恐れがあります。 |
オリジナルスケーリンググループのノードプールへの変換 | 既存のスケーリンググループのノードプールへの切り替えをサポートします。変換後は、ノードプールはオリジナルスケーリンググループの機能を完全に引き継ぎ、そのスケジューリンググループの情報は表示されなくなります。 クラスターメモリ量のすべてのスケーリンググループの切り替えが完了した後は、スケーリンググループにポータルを提供しません。 | 不可逆的な操作ですので、ノードプールの機能を理解してから切り替えを行ってください。 |
関連する操作
TKEコンソール にログインし、次のドキュメントを参考に、ノードプールについての操作を行ってください。
フィードバック