Implementing Slow SQL Analysis Using the Auto_explain Plugin
Download
포커스 모드
폰트 크기
마지막 업데이트 시간: 2025-06-09 10:27:42
Note:
Enabling auto_explain requires restarting the database. Plan the operation and maintenance time window in advance.
Enabling auto_explain will incur a certain performance loss, which is related to the specific service. Test thoroughly beforehand.
Enabling auto_explain may result in more occupied disk space due to the generation of excessive logs. Be aware of this.
If you wish to enable auto_explain and download logs, please submit a ticket to get in touch with us.
Description of Key Parameters
The auto_explain plugin offers a feature for automatically logging SQL execution plans. Once this plugin is enabled in the instance, you can configure its detailed capabilities through the parameter settings in the console. Below, key parameters will be explained, while comprehensive details can be found in the official documentation.
auto_explain.log_min_duration
This parameter primarily determines which SQL statements with execution time exceeding a certain duration will have their execution plans recorded. The default value is -1, representing no recording. Custom range is 500-60000 milliseconds.
auto_explain.log_analyze
Adding this parameter can print the actual execution time of the execution plan. Default is off, in disabled state.
auto_explain.log_timing
Adding this parameter can print the statement execution time. Default is off, in disabled state.
auto_explain.log_verbose
Adding this parameter can increase the verbose information output in explain to obtain more detailed execution plan information. Default is off, in disabled state.
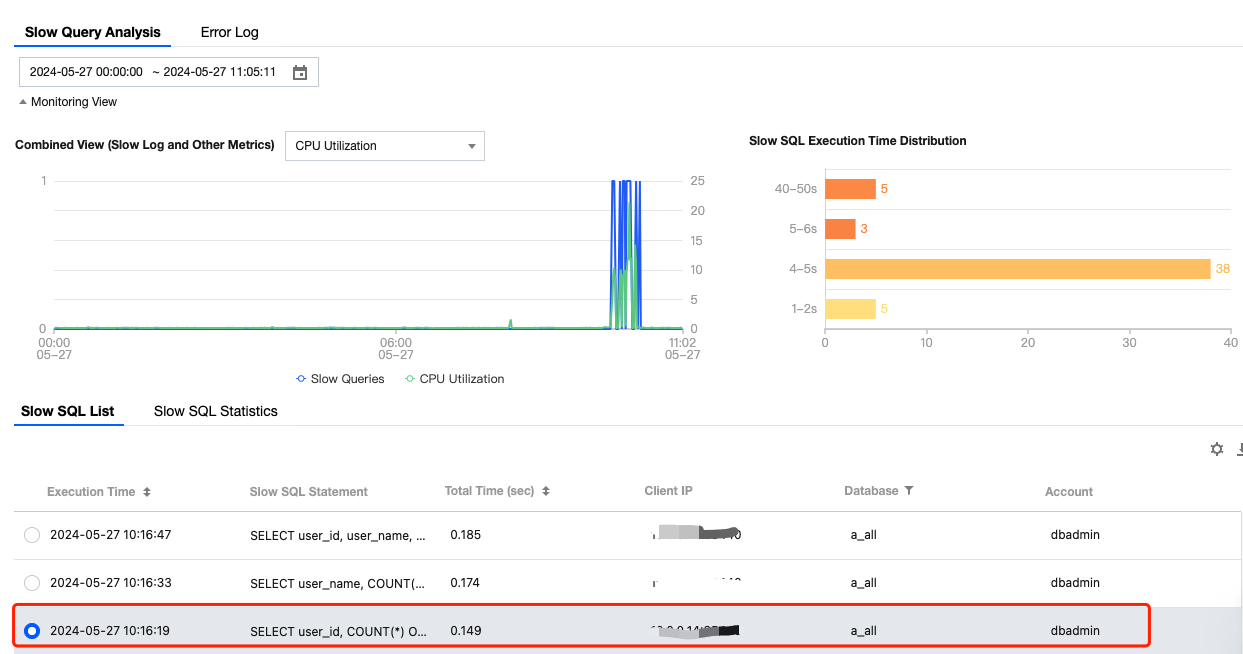
Examples
Assume the instance has a database named a_all, and this database has 10 tables under the public schema, namely: student_info_b0, student_info_b1, student_info_b2, student_info_b3, student_info_b4, student_info_b5, student_info_b6, student_info_b7, student_info_b8, student_info_b9
The current TencentDB for PostgreSQL instance has enabled the auto_explain plugin. Its parameter values are as follows:
a_all=> show auto_explain.log_min_duration;
auto_explain.log_min_duration
-------------------------------
800ms
(1 row)
a_all=> show auto_explain.log_analyze;
auto_explain.log_analyze
--------------------------
on
(1 row)
a_all=> show auto_explain.log_verbose;
auto_explain.log_verbose
--------------------------
on
(1 row)
a_all=> show auto_explain.log_timing;
auto_explain.log_timing
-------------------------
on
(1 row)
The following statements are executed:
SELECT user_id, COUNT(*) OVER (PARTITION BY user_id) as countFROM ( SELECT user_id FROM student_info_b0 UNION ALL SELECT user_id FROM student_info_b1 UNION ALL SELECT user_id FROM student_info_b2 UNION ALL SELECT user_id FROM student_info_b3 UNION ALL SELECT user_id FROM student_info_b4 UNION ALL SELECT user_id FROM student_info_b5 UNION ALL SELECT user_id FROM student_info_b6 UNION ALL SELECT user_id FROM student_info_b7 UNION ALL SELECT user_id FROM student_info_b8 UNION ALL SELECT user_id FROM student_info_b9) AS all_students;