HINTによるSQL実行の最適化
ダウンロード
フォーカスモード
フォントサイズ
ヒントとは
オプティマイザは、一般にユーザーのSQLに対して最適な実行計画を選択します。しかし、統計情報の推定誤差やコストモデルのフィッティング偏差などの特定のシナリオでは、オプティマイザが生成する実行計画は最適でない可能性があります。このような場合、ユーザーはHintメカニズムを使用してオプティマイザを指導し、より良い実行計画を生成させることができます。
ヒントは大文字と小文字を区別しません。/*+ ... */ のコメント形式でSELECTキーワードの後ろに配置され、複数のヒントはスペースまたはカンマで区切ります。以下はヒントの使用例です。
SELECT /*+ [hint_text] [hin_text]... */ * FROM ....
Hintの適用範囲
ヒントはクエリブロック単位で適用されます。DML文では、各クエリブロックにQB_NAME(クエリブロック名)が割り当てられ、読み取り専用分析エンジンは左から右の順に@sel_1、@sel_2 のように各クエリブロックにQB_NAMEを生成します。以下のSQLを例として。
SELECT * FROM (SELECT * FROM t) t1, (SELECT * FROM t) t2;
このSQLには3つのクエリブロックが含まれており、最も外側のSELECTが配置されているクエリブロックの名前はsel_1、2つのSELECTサブクエリの名前は順にsel_2とsel_3であり、番号は順次増加します。ヒントではQB_NAMEを使用することで、ヒントの適用範囲と対象を制御できます。ヒントでQB_NAMEを明示的に指定しない場合、ヒントの適用範囲はそのヒントが存在するクエリブロックとなります。以下に例を示します。
SELECT /*+ HASH_JOIN_PROBE(@sel_2 t1) */ * FROM (SELECT t1.a, t1.b FROM t t1, t t2 WHERE t1.a = t2.a) t1, t t3 WHERE t1.b = t3.b;SELECT /*+ HASH_JOIN_PROBE(t1@sel_2) */ * FROM (SELECT t1.a, t1.b FROM t t1, t t2 WHERE t1.a = t2.a) t1, t t3 WHERE t1.b = t3.b;
上記の2つのSQLでは、ヒント内でQB_NAMEを指定する2つの異なる方法を使用しています。1つ目のSQLでは、ヒントの最初のパラメータでQB_NAMEを指定し、スペースで他のパラメータと区切ります。2つ目のSQLでは、パラメータの後ろにQB_NAMEを追加することで、ヒントの適用範囲を指定します。
サポートされているヒントの概要
読み取り専用分析エンジンのヒント関連パラメータの名称、意味、構文は以下の表に示します。
名称 | 構文 | セマンティクス |
SHUFFLE_JOIN | SHUFFLE_JOIN([QB_NAME] tbl1_name,tbl2_name …) | JOIN操作でシャッフル方式によるデータ分散を指定します。 |
BROADCASR_JOIN | BROADCAST_JOIN([QB_NAME] tbl1_name,tbl2_name …) | JOIN操作でブロードキャスト方式によるデータ分散を指定します。 |
HASH_JOIN_BUILD | HASH_JOIN_BUILD([QB_NAME] tbl1_name,tbl2_name …) | HASH JOIN操作におけるビルドテーブルを指定します。 |
HASH_JOIN_PROBE | HASH_JOIN_PROBE([QB_NAME] tbl1_name,tbl2_name …) | HASH JOIN操作におけるプローブテーブルを指定します。 |
LEADING | LEADING([QB_NAME] tbl1_name,tbl2_name …) | JOIN操作のJoin Orderを指定します。 |
SET_VAR | SET_VAR(setting_name = value) | SQLレベルでシステムパラメータを設定します。 |
NO_PX_JOIN_FILTER_ID/PX_JOIN_FILTER_ID | NO_PX_JOIN_FILTER_ID(rf_id1,rf_id2…)/ PX_JOIN_FILTER_ID(rf_id1,rf_id2…) | ランタイムフィルタの有効化と無効化を制御します。 |
読み取り専用分析エンジンのヒント構文詳細解説
SHUFFLE_JOIN(t1_name, t2_name ...)
使用説明
SHUFFLE_JOIN(t1_name, t2_name ...) は、読み取り専用分析エンジンのオプティマイザがJOIN操作を行う際にShuffle Joinアルゴリズムを採用するよう制御するために使用されます。左右のテーブルデータを分散させて再配置した後、JOIN操作を実行します。
参考例
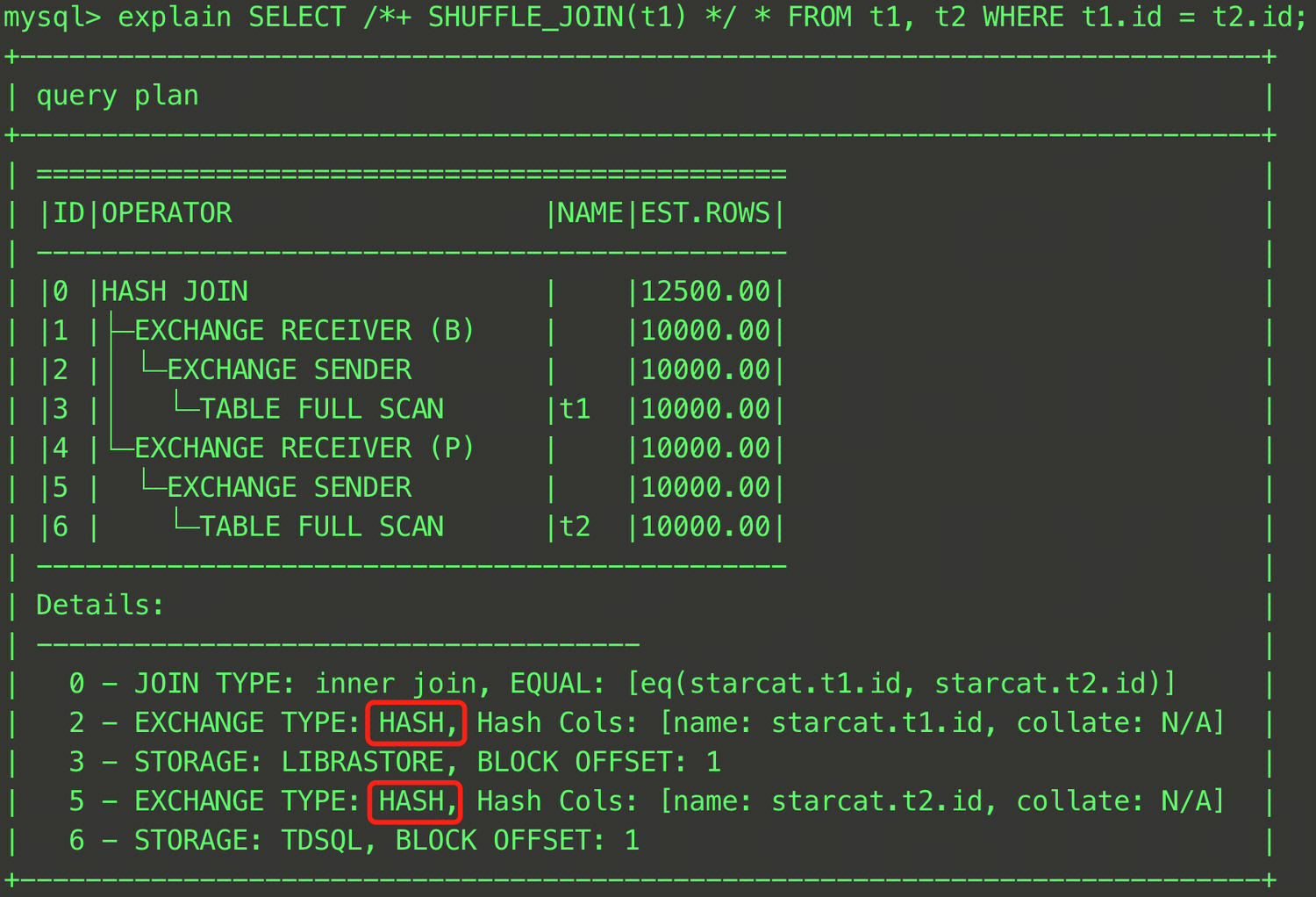
EXPLAIN SELECT /*+ SHUFFLE_JOIN(t1) */ * FROM t1, t2 WHERE t1.id = t2.id;
このSQL文では、t1テーブルとt2テーブルのJOIN操作が行われ、SHUFFLE_JOINヒントによってJoinデータ分散方式がShuffle Joinに指定されました。最終的なプランは下図の通りで、Detailsの2行目と5行目のEXCHANGE TYPEがHASHに変更されていることから、ハッシュシャッフルが採用されたことが確認できます。
単一テーブルを指定するだけでなく、JOINの中間結果を指定してデータの再分散を行うことも可能です。
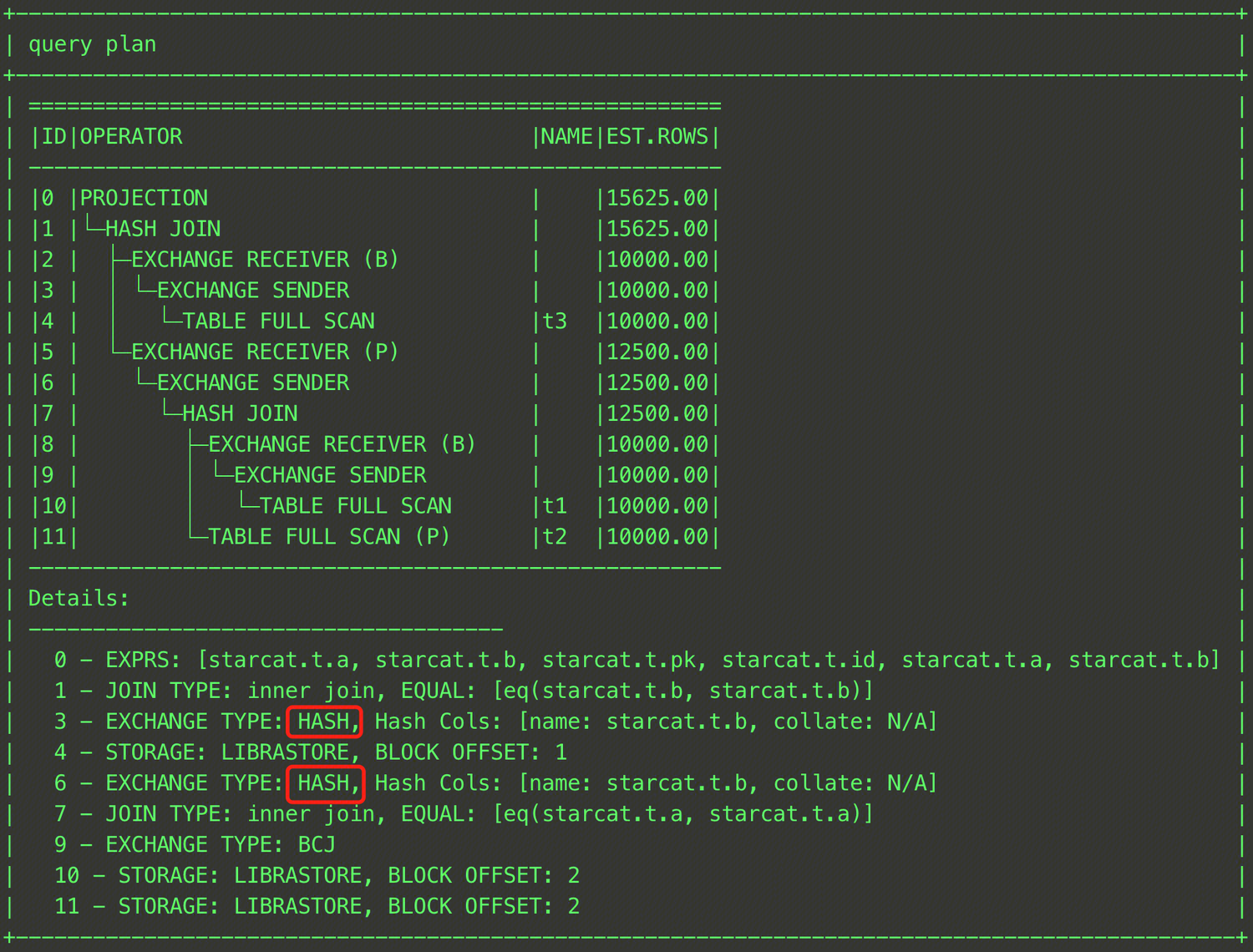
EXPLAIN SELECT /*+ SHUFFLE_JOIN((t1@sel_2,t2@sel_2)) */ * FROM (SELECT t1.a, t1.b FROM t t1, t t2 WHERE t1.a = t2.a) t1, t t3 WHERE t1.b = t3.b;
上記のように、t1テーブルとt3テーブルを括弧で囲み、各テーブルのQB_NAMEを指定することで、t1とt3テーブルのJOINの中間結果とt2テーブルとのJOIN時にShuffle Joinを採用するように指定できます。
注意:
このヒントは分散プランの生成時にのみ有効で、シングルマシンプランでは無効です。
BROADCAST_JOIN(t1_name [, tl_name ...])
使用説明
BROADCAST_JOIN(t1_name,t2_name...) は、読み取り専用分析エンジンのオプティマイザがJOIN操作を行う際にBroadcast Joinアルゴリズムを採用するよう制御するために使用されます。指定されたテーブルデータをすべてのノードにブロードキャストしてJOIN操作を実行し、結果を返します。
参考例
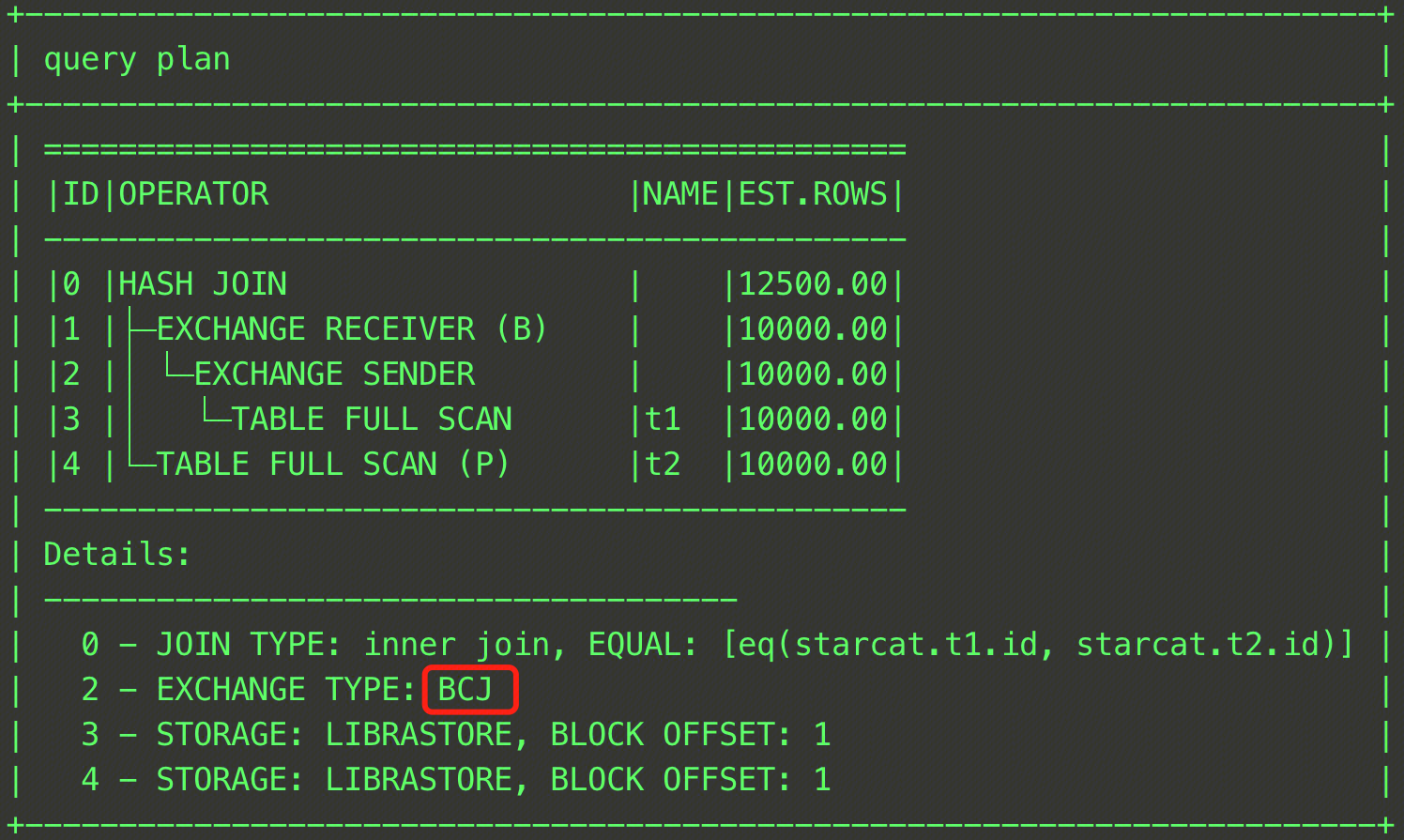
EXPLAIN SELECT /*+ BROADCAST_JOIN(t1) */ * FROM t1, t2 WHERE t1.id = t2.id;
このSQL文では、t1テーブルとt2テーブルのJOIN操作が行われ、BROADCAST_JOINヒントによってJOIN方式がBroadcast Joinに指定されました。最終的なプランは下図の通りで、Detailsの2行目と5行目のEXCHANGE TYPEがBCJに変更されていることから、ブロードキャストが採用されたことが確認できます。
単一テーブルを指定するだけでなく、JOINの中間結果を指定してデータブロードキャストを行うことも可能です。
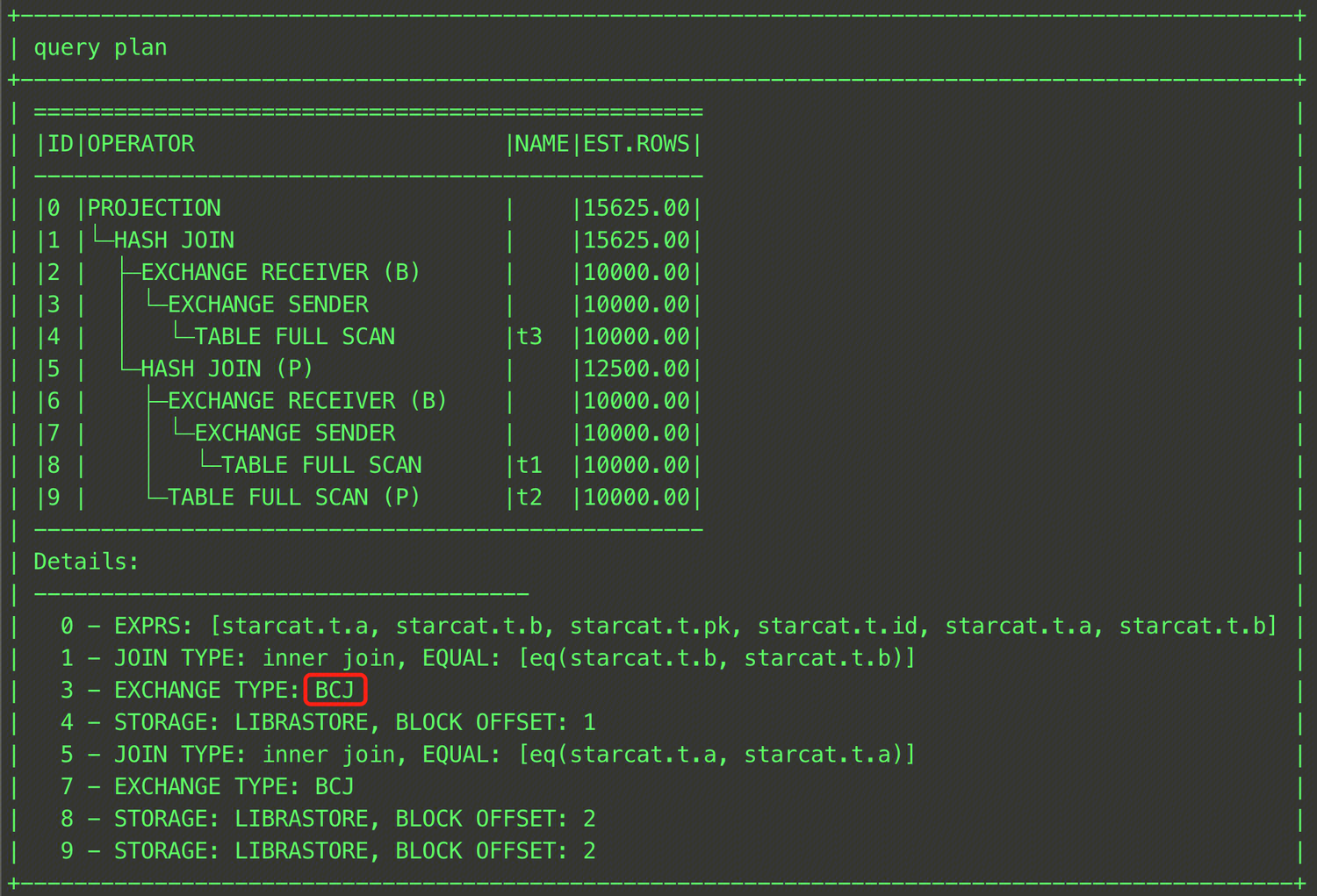
EXPLAIN SELECT /*+ BROADCAST_JOIN((t1@sel_2,t3@sel_1)) */ * FROM (SELECT t1.a, t1.b FROM t t1, t t2 WHERE t1.a = t2.a) t1, t t3 WHERE t1.b = t3.b;
上記のように、t1テーブルとt3テーブルを括弧で囲み、各テーブルのQB_NAMEを指定することで、t1とt3テーブルのJOINの中間結果とt2テーブルとのJOIN時にBroadcast Joinを採用するように指定できます。結果は下図の通りです。
注意:
このヒントは分散プランの生成時にのみ有効で、シングルマシンプランでは無効です。
読み取り専用分析エンジンのオプティマイザは、Hash Joinのビルド側をブロードキャストテーブルとして選択します。調整が必要な場合は、HASH_JOIN_BUILDと組み合わせて調整できます。
HASH_JOIN_BUILD(t1_name,t2_name…)
使用説明
HASH_JOIN_BUILD(t1_name,t2_name ...) は、読み取り専用分析エンジンのオプティマイザが指定されたテーブルにハッシュ結合アルゴリズムを使用するよう制御するために使用されます。同時に、指定されたテーブルをハッシュ結合アルゴリズムのビルド側として使用します。つまり、指定されたテーブルを使用してハッシュテーブルを構築します。
参考例
EXPLAIN SELECT /*+ HASH_JOIN_BUILD(t2)*/ * FROM t t1, t t2 WHERE t1.a = t2.a;
このSQL文は、HASH JOINにおけるビルドテーブルとしてt2テーブルを指定しました。最終プランは下図の通りです。
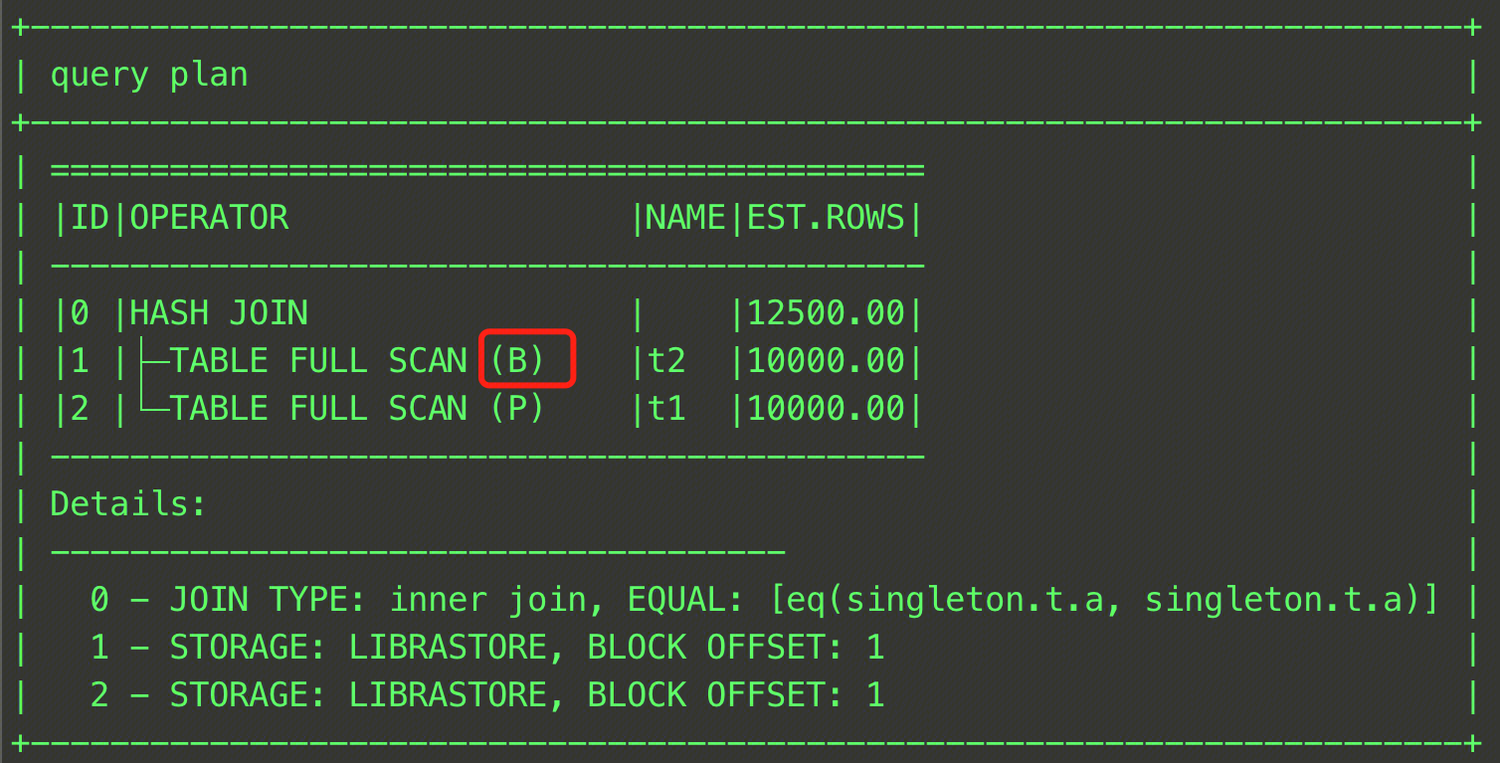
単一テーブルを指定するだけでなく、JOINの中間結果をビルド側として指定することも可能です。以下に例を示します。
EXPLAIN SELECT /*+ HASH_JOIN_BUILD((t1@sel_2,t3@sel_1)) */ * FROM (SELECT t1.a, t1.b FROM t t1, t t2 WHERE t1.a = t2.a) t1, t t3 WHERE t1.b = t3.b;
上記のように、t1テーブルとt2テーブルを括弧で囲み、各テーブルのQB_NAMEを指定すればよいです。
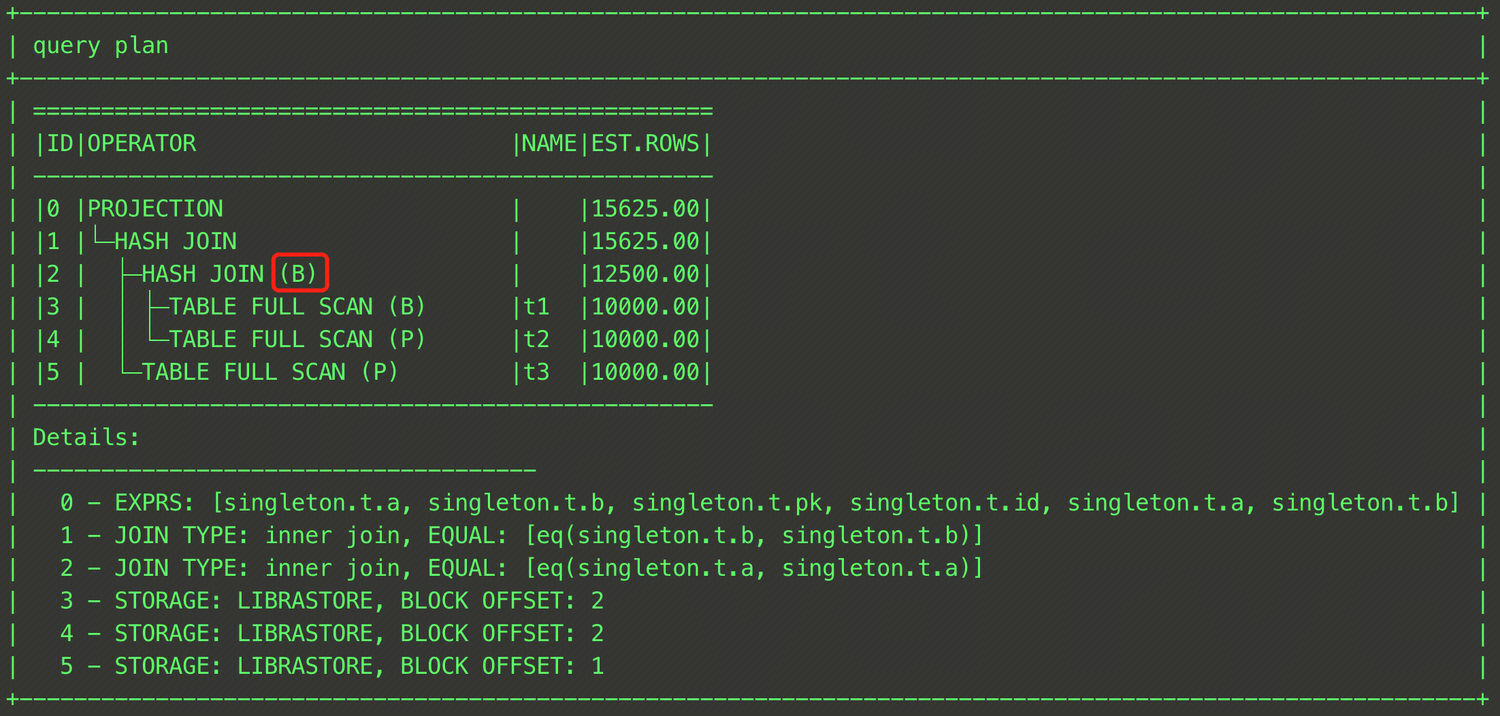
HASH_JOIN_PROBE(t1_name,t2_name…)
使用説明
HASH_JOIN_PROBE(t1_name,t2_name ...) は、オプティマイザが指定されたテーブルにハッシュ結合アルゴリズムを使用するよう制御するために使用されます。同時に、指定されたテーブルをハッシュ結合アルゴリズムのプローブ側として使用します。つまり、指定されたテーブルをハッシュ結合のプローブテーブルとして使用します。
参考例
EXPLAIN SELECT /*+ HASH_JOIN_PROBE(t2)*/ * FROM t t1, t t2 WHERE t1.a = t2.a;
このSQL文は、HASH JOINにおけるプローブテーブルとしてt2テーブルを指定しました。最終プランは下図の通りです。
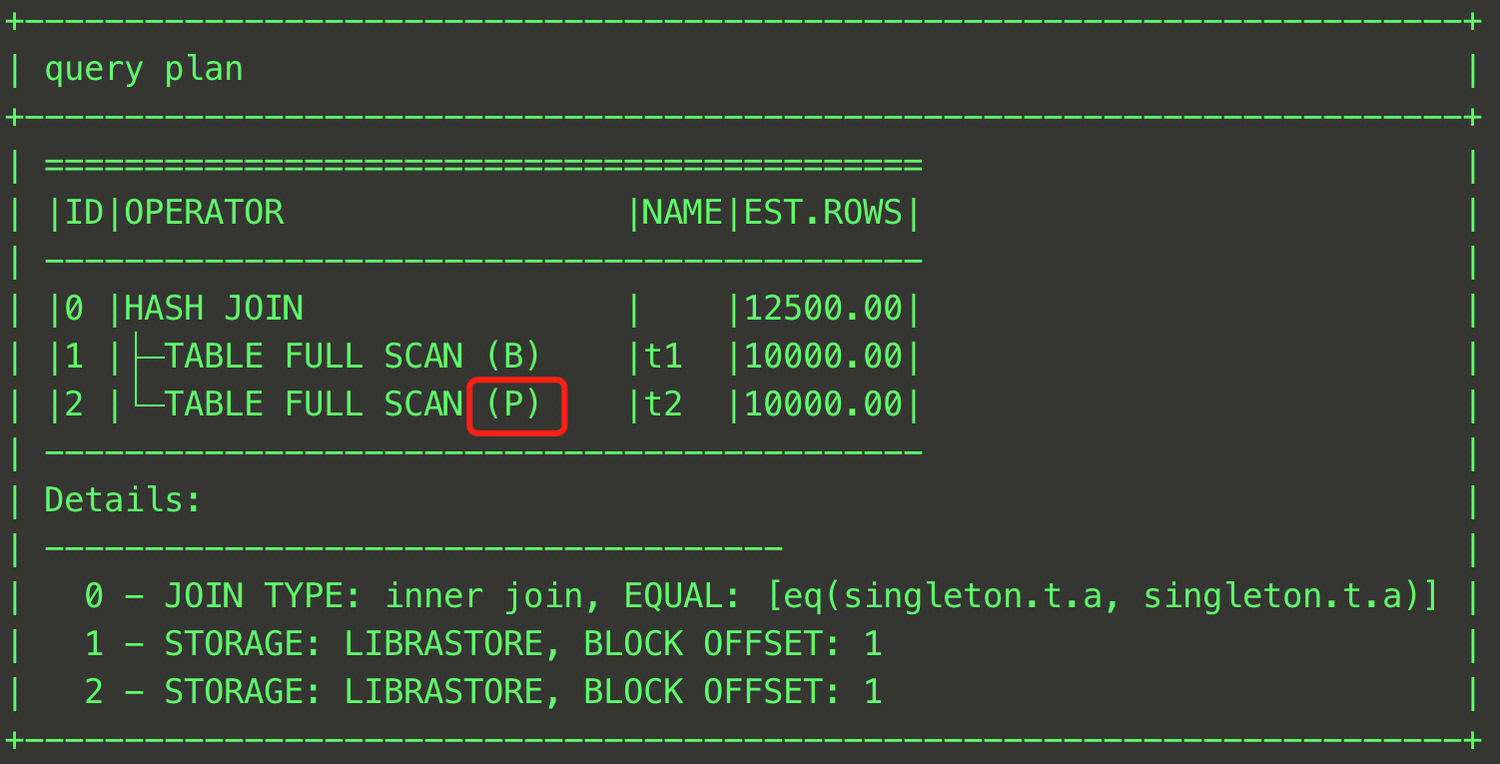
単一テーブルを指定するだけでなく、JOINの中間結果をプローブ側として指定することも可能です。以下に例を示します。
EXPLAIN SELECT /*+ HASH_JOIN_PROBE((t1@sel_2,t3@sel_1)) */ * FROM (SELECT t1.a, t1.b FROM t t1, t t2 WHERE t1.a = t2.a) t1, t t3 WHERE t1.b = t3.b;
上記のように、t1テーブルとt2テーブルを括弧で囲み、各テーブルのQB_NAMEを指定すればよく、最終プランは下図の通りです。
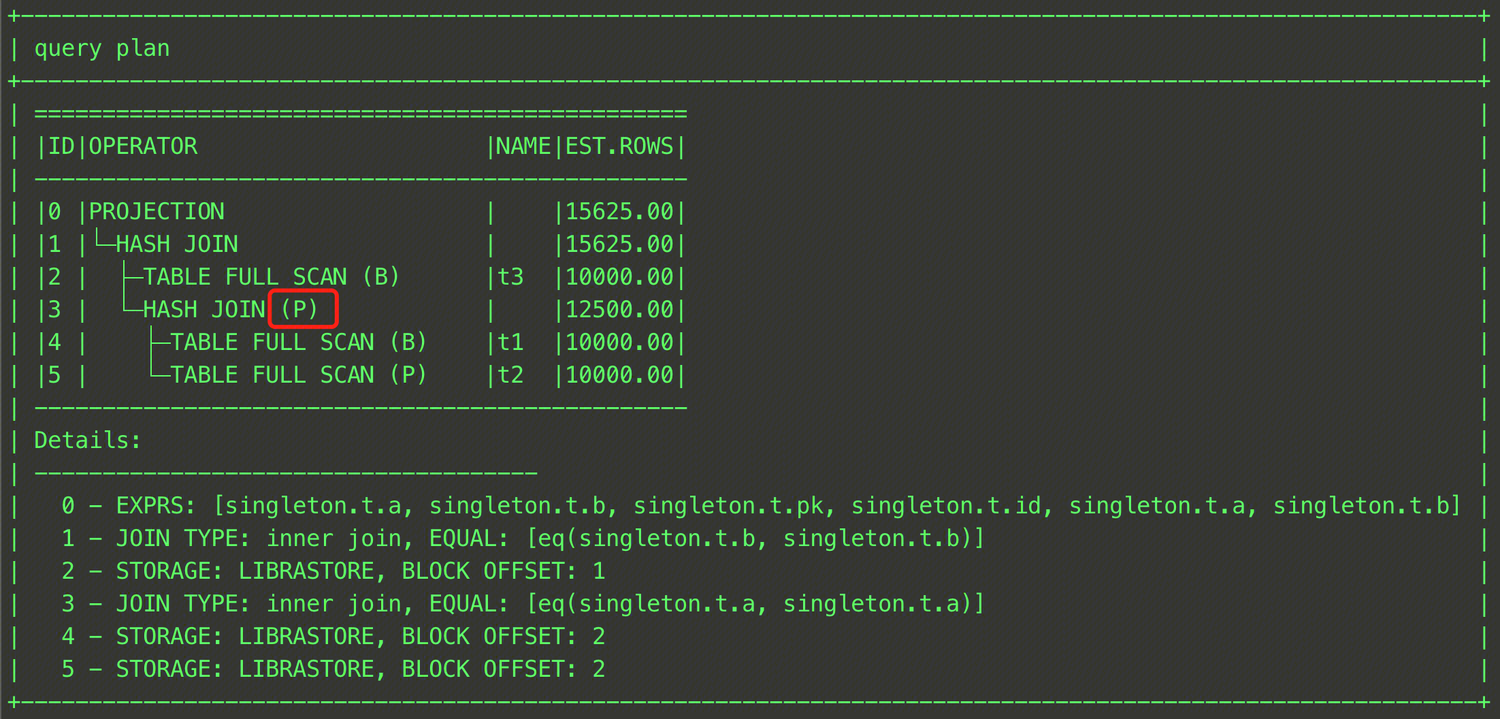
LEADING(t1_name,t2_name …)
使用説明
Leading(t1_name,t2_name...) は、オプティマイザがJoin Reorderフェーズで生成するJoin Orderを制御するために使用されます。オプティマイザはLeading Hintに出現する順序に従ってJoin Orderを決定します。
参考例
EXPLAIN SELECT /*+ LEADING(t1,t3,t2,t4)*/ * FROM t1,t2,t3,t4 WHERE t1.a = t2.a and t2.a = t3.a and t3.a = t4.a;
このSQL文では、LEADINGヒントを使用して、t1テーブルを最初にt3テーブルとジョインし、次にt2テーブルとジョインし、最終的にt4テーブルとジョインすることを明示的に指定しています。最終プランは下図の通りです。
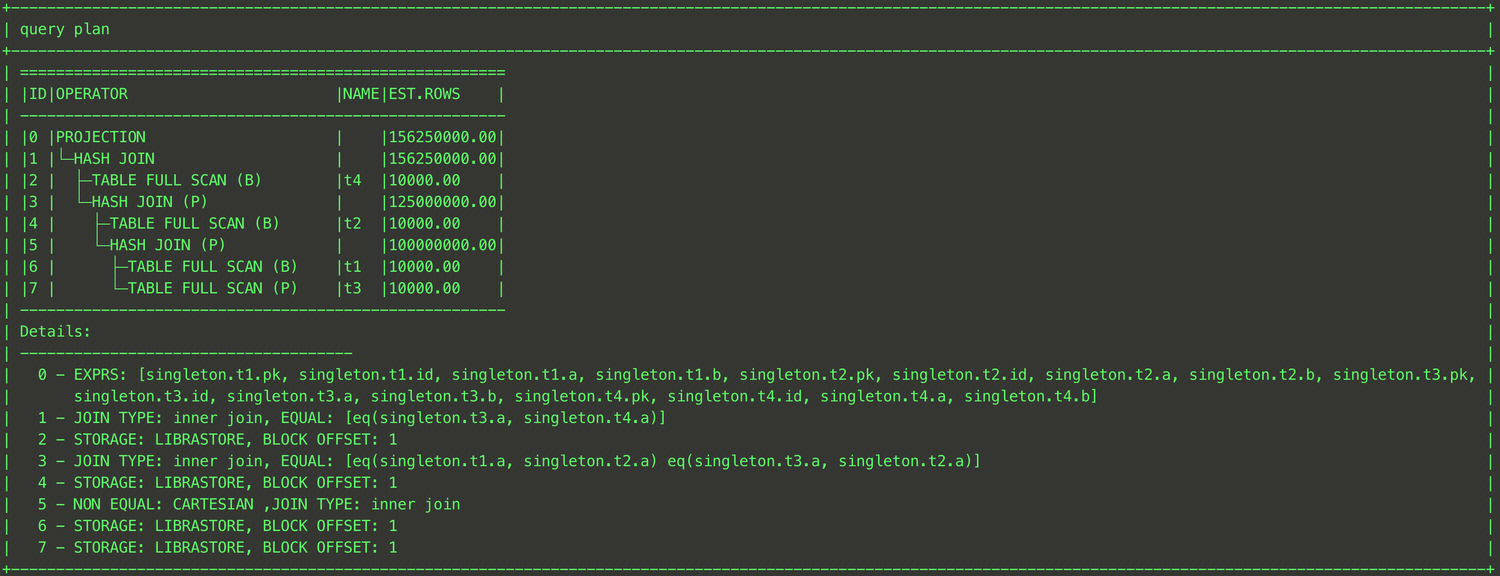
上記の方法でJOIN順序を指定すると左深ツリーのみ生成されますが、読み取り専用分析エンジンではLEADINGに高度な構文も提供しており、括弧を使用することでブッシーツリーを生成することも可能です。例を以下に示します。
EXPLAIN SELECT /*+ LEADING((t1,t3),(t2,t4))*/ * FROM t1,t2,t3,t4 WHERE t1.a = t2.a and t2.a = t3.a and t3.a = t4.a;
このSQL文のLEADINGヒントでは、まず(t1,t3)によってオプティマイザにt1テーブルとt3テーブルのJOINを先行させます。その後(t2,t4)によってオプティマイザにt2テーブルとt4テーブルのJOINを実行させ、最後に((t1,t3),(t2,t4))によって上記2つのJOIN結果を結合させます。最終的な実行計画は下図の通りです。
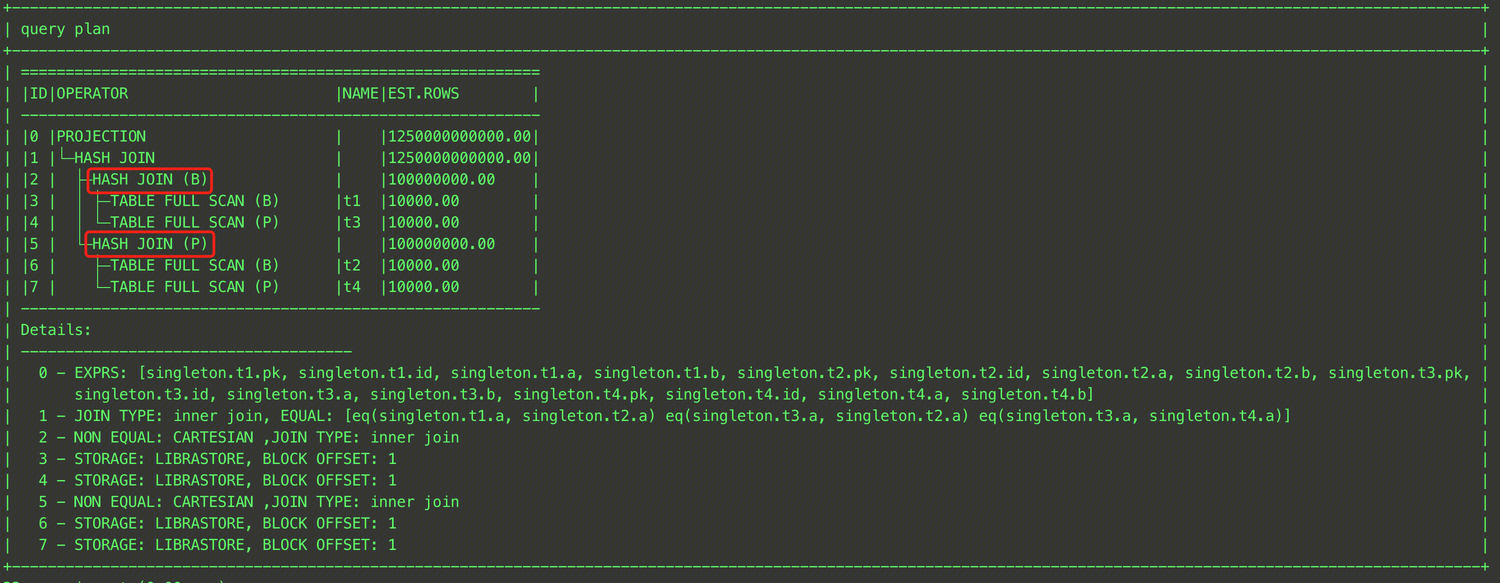
注意:
複数のLEADINGヒントが存在する場合、ヒントが無効になります。
オプティマイザがLEADINGに従ってテーブルをジョインできない場合、ヒントは無効になります。
SET_VAR(NAME="VALUE")
使用説明
SET_VAR(XXXX="YY") は、SQL実行中にシステム変数を一時的に変更するために使用されます。SQL実行が完了すると、指定されたシステム変数は自動的に元の値に復元されます。使用方法は以下の通りです。
参考例
SELECT /*+ SET_VAR(max_threads=64) */ * FROM t1
このSQL文では、SET_VARヒントを使用してSQL実行中の最大スレッド数を64に一時的に指定しています。
注意:
すべてのパラメータがSET_VARヒントをサポートしているわけではありません。使用前に対象パラメータがヒントによる変更をサポートしていることを確認してください。ヒントによる変更が可能なパラメータについては、システム変数を参照してください。
NO_PX_JOIN_FILTER_ID(ID)/PX_JOIN_FILTER_ID(ID)
使用説明
no_px_join_filter_id(ID)/px_join_filter_id(ID)は、オプティマイザによるランタイムフィルタの無効化または有効化を制御するために使用されます。
参考例
よくあるヒント問題
MYSQLクライアントがヒントを除去すると、有効にならなくなります。
MySQLコマンドラインクライアントは、5.7バージョンより前ではデフォルトでOptimizer Hintsをクリアしていました。これらの古いバージョンのクライアントでヒント構文を使用する必要がある場合は、クライアント起動時に
--commentsオプションを追加する必要があります。例:mysql -h 127.0.0.1 -P 4000 -u root -cクロスデータベースクエリでデータベース名を指定しないとヒントが有効になりません。
クエリ内で複数のデータベースに跨るテーブルアクセスが必要な場合、ヒント内で明示的にデータベース名を指定する必要があります。指定しない場合、ヒントが有効にならない可能性があります。例えば、以下のSQL文の場合:
SELECT /*+ SHUFFLE_JOIN(t1) */ * FROM test1.t1, test2.t2 WHERE t1.id = t2.id;
現在のデータベースにt1テーブルが存在するため、ヒントが無効になりました。Warning情報は以下の通りです。
mysql> show warnings;+---------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------+| Level | Code | Message |+---------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------+| Warning | 1815 | There are no matching table names for (t1) in optimizer hint /*+ SHUFFLE_JOIN(t1) */ or /*+ SHUFFLE_JOIN(t1) */. Maybe you can use the table alias name |+---------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------+1 row in set (0.00 sec)
QB_NAMEが指定されていない/誤って指定されたため、ヒントが有効になりません
複数のQB_NAMEを持つクエリの場合、ヒントが対象テーブルのクエリブロックに記述されていないときは、ヒント内で明示的にQB_NAMEを指定する必要があります。指定しない場合、クエリヒントが有効にならない問題が発生する可能性があります。例:
SELECT /*+ HASH_JOIN_PROBE(t2) */ * FROM (SELECT t1.a, t1.b FROM t t1, t t2 WHERE t1.a = t2.a) t1, t t3 WHERE t1.b = t3.b;
ヒント内のt1テーブルでQB_NAMEが明示的に指定されていないため、ヒントが有効になりませんでした。ワーニング情報は以下の通りです。
mysql> show warnings;+---------+------+---------------------------------------------------------------------------------------------------------------------------------+| Level | Code | Message |+---------+------+---------------------------------------------------------------------------------------------------------------------------------+| Warning | 1815 | There are no matching table names for (t2) in optimizer hint /*+ HASH_JOIN_PROBE(t2) */. Maybe you can use the table alias name |+---------+------+---------------------------------------------------------------------------------------------------------------------------------+1 row in set (0.00 sec)
この時、キーワードでSQL計画を検索し、各テーブルが属するクエリブロックのQB_NAMEを確認できます。
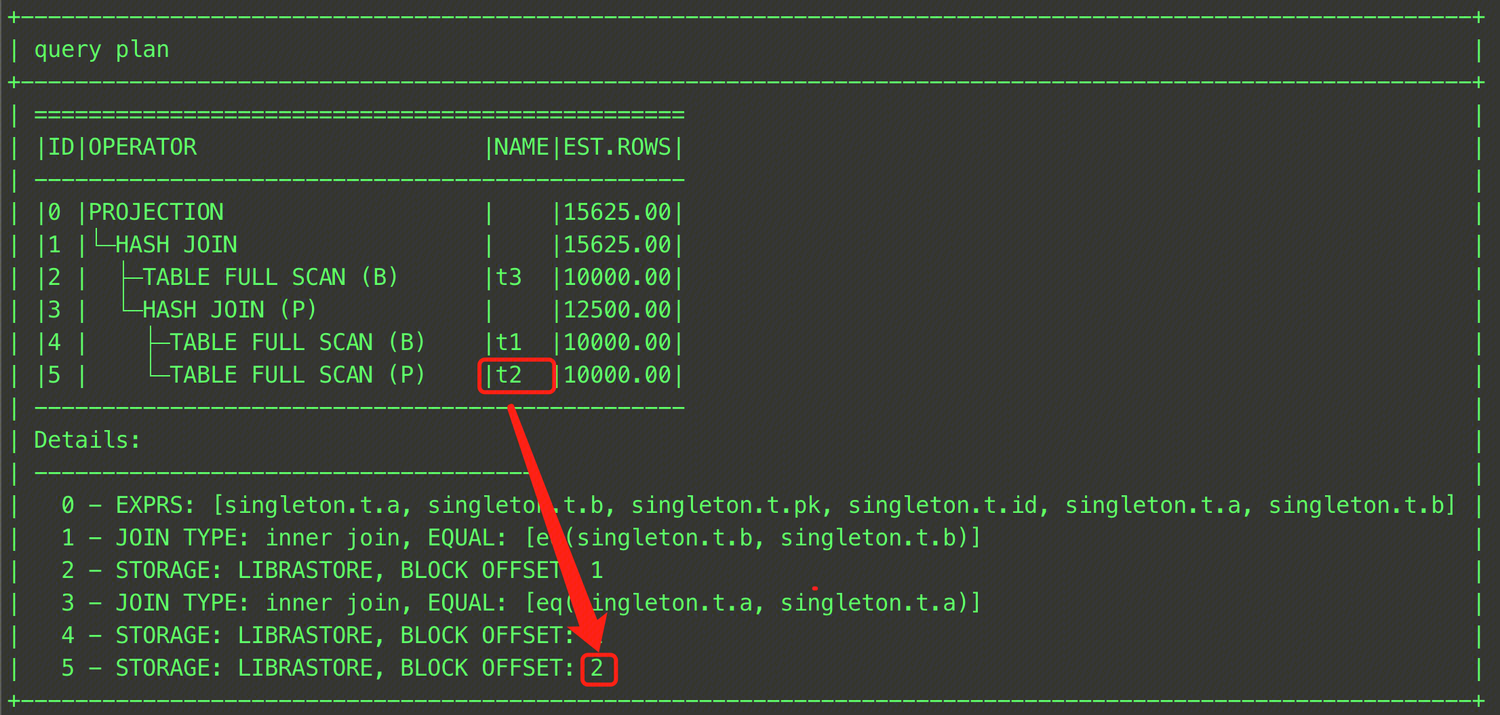
ヒントの位置が正しくないため、有効になりません。
Optimizer Hints構文に従ってヒントを指定キーワードの後ろに正しく配置しないと、有効になりません。例:
SELECT * /*+ SET_VAR(max_threads = 64)) */ FROM t;SHOW WARNINGS;
ワーニング情報は以下の通りです。
+---------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| Level | Code | Message |+---------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| Warning | 1064 | You have an error in your SQL syntax; check the manual that corresponds to your TiDB version for the right syntax to use [parser:8066]Optimizer hint can only be followed by certain keywords like SELECT etc. |+---------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+1 row in set (0.01 sec)
上記の例では、HintをSELECTキーワードの直後に配置する必要があります。
フィードバック