AIオプティマイザを有効にする
ダウンロード
フォーカスモード
フォントサイズ
本文では、AIオプティマイザを有効にする方法、およびAIオプティマイザページの関連フィールドについて説明します。
AIオプティマイザを有効にする
説明:
ご注意:この機能は現在、許可リストによる段階的リリース中です。コンソールに機能のエントリが表示されない場合は、しばらくお待ちください。ご不明な点がございましたら、チケットを提出してフィードバックをお寄せください。
新規購入時にAIオプティマイザを有効にすると、クラスタディメンションで有効になります。新規購入時、クラスタ内のすべてのインスタンスでこの機能が自動的に有効になります。
既存クラスタでAIオプティマイザを有効にする場合は、インスタンスディメンションで有効になります。クラスタ配下の任意のインスタンス(複数選択可)を選択して機能を有効にすることができます。
シナリオ1:新規クラスタ購入時にAIオプティマイザを有効にする
プリセットリソースクラスターを購入する場合は、詳細な操作についてはクラスタの作成を参照してください。
Serverlessクラスターを購入する場合は、詳細な操作についてはServerless版クラスターの作成を参照してください。
シナリオ2:既存クラスタでAIオプティマイザを有効にする
1. TDSQL-C for MySQLコンソールにログインします。
2. クラスターリストで、クラスタIDをクリックして、クラスタ管理ページに進みます。
3. AIオプティマイザページを選択し、今すぐ有効にするをクリックします。

4. ポップアップウィンドウで、AIオプティマイザを有効にするクラスタ配下のインスタンス(読み書きインスタンス、読み取り専用インスタンスのどちらも選択/複数選択可)にチェックを入れ、確定をクリックします。
シナリオ3:クラスタ配下のインスタンスでAIオプティマイザを有効にする
クラスタ配下に複数のインスタンスがあり、すべてのインスタンスでAIオプティマイザが有効になっていない場合は、以下の操作を参考にして、指定したインスタンスで機能を有効にすることができます。
1. TDSQL-C for MySQLコンソールにログインします。
2. クラスターリストで、クラスタIDをクリックして、クラスタ管理ページに進みます。
3. AIオプティマイザページを選択し、右側の機能設定をクリックします。
4. ポップアップウィンドウで、ターゲットインスタンスの機能ボタンを有効にします。
AWR 説明
AWR(Automatic Workload Repository)は、データを収集してトレーニングおよび最適化を行う関連機能の総称であり、パラメータを通じて様々な制御と調整を実現します。AIオプティマイザを有効にすると、AWRも同時に有効になります。現在AWRが提供するパラメータは以下の通りです:
パラメータ名 | タイプ | 設定可能範囲 | 説明 |
txsql_awr_enabled_level | uint | 0 | 2 | このパラメータは、AWRのレベルセレクタを表します。 値が0の場合:動作しません。これはAIオプティマイザが停止していることも意味します。 値が2の場合:AAS高精度タイマーを有効化します。これはAIオプティマイザが有効になっていることも意味します。新規購入時、または既存クラスタでコンソールを通じてAIオプティマイザを有効にする場合、このパラメータ値はデフォルトで2に設定されます。 説明: コンソールでAIオプティマイザを停止する場合、このパラメータは自動的に停止されません(値は0のままです)。停止する必要がある場合は、インスタンスパラメータの設定を参考にして手動で調整してください。 |
AIオプティマイザページの表示(機能有効化済み)
1. TDSQL-C for MySQLコンソールにログインします。
2. クラスターリストで、クラスタIDをクリックして、クラスタ管理ページに進みます。
3. AIオプティマイザページを選択します。
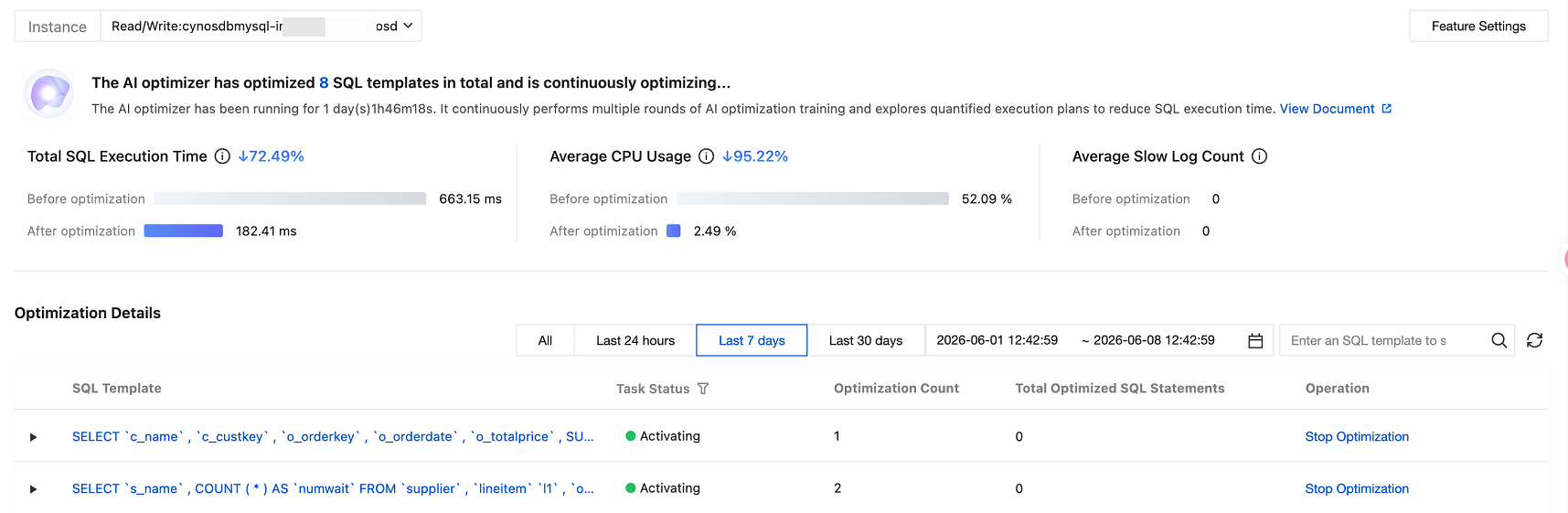
概要の表示
AIオプティマイザページの上部で、インスタンスを切り替えて表示することができます。
表示するインスタンスを選択すると、下部に現在のインスタンスのAIオプティマイザが累積で最適化したSQLテンプレートの数と実行時間が表示されます。機能を停止するまで、AIオプティマイザは複数ラウンドのAIトレーニングを継続し、実行計画を探索・定量化することで、SQL実行時間を低減します。
指標説明の表示
AIオプティマイザは現在以下のパフォーマンス指標に関与しています。最適化前後の指標データを比較することで、AIオプティマイザを有効にした後の最適化効果を明確に把握し、この機能が現在SQL実行時間の短縮に関するご要件を満たしているかどうかを判断できます。
SQL総実行時間:SQLテンプレートの最適化前後の実行時間の比較を表示します。トレーニング前後に実行されたSQLテンプレートの時間を累積して計算します。
平均CPU使用率:最適化前後のインスタンスの平均CPU使用率の比較を表示します。トレーニング前後のインスタンスの平均CPU使用率のモニタリングに基づいて計算されます。使用状況によっては、最適化後の数値が最適化前を上回る場合があります。
平均スローログ数:最適化前後のインスタンスの平均スローログ数の比較を表示します。トレーニング前後のインスタンスの平均スローログ数のモニタリングに基づいて計算されます。使用状況によっては、最適化後の数値が最適化前を上回る場合があります。
最適化明細の表示
現在のインスタンスの全期間、直近24時間、直近7日間、直近30日間、およびカスタム時間範囲の最適化明細リストを表示することができます。検索ボックスにSQLテンプレートを入力して迅速に検索し、対応する最適化タスクの最適化明細を取得することができます。リストを更新する必要がある場合は、
フィールド名称 | 説明 |
SQLテンプレート | SQLテンプレートの詳細を表示します。 |
タスク状態 | 最適化タスクの現在のステータスを表示します。フィルタリングをサポートし、値は以下を含みます: 有効中:現在のタスクが継続して最適化されていることを示します。 無効化済み:現在のタスクが最適化を停止したことを示します。新しいタスクに上書きされた場合、または手動で最適化を停止する操作を行った場合、いずれも現在のタスクのステータスが無効化済みになります。 |
最適化回数 | 現在の最適化タスクの最適化回数を表示します。 |
累積最適化SQL数 | 現在の最適化タスクの累積最適化SQL数を表示します。 |
操作 | 現在の最適化タスクに対して実行可能な操作を表示します。 最適化を停止:最適化を停止をクリックすると、実行中の最適化タスクを手動で停止できます。 トレーニングを再開:トレーニングを再開をクリックすると、停止状態の最適化タスクを手動で再開できます。 |
SQLテンプレート詳細の表示
最適化明細リストから対象の最適化タスクを見つけ、
フィールド名称 | 説明 |
最適化フェーズ | 過去および現在の最適化タスクのステータスを表示します。形式は以下の通りです: 2025-04-28 03:04:36 有効中です。 |
トレーニングラウンド | 最適化タスクのトレーニングラウンドを表示します。例:1。 |
平均実行時間(ms) | 対応する最適化フェーズにおける最適化前後の平均実行時間を表示します。単位:ミリ秒。 |
平均スキャン行数 | 対応する最適化フェーズにおける最適化前後の平均スキャン行数を表示します。 |
最適化SQL数 | 対応する最適化フェーズにおける最適化SQL数を表示します。 |
操作 | 表示:表示をクリックすると、ポップアップウィンドウで対応する最適化フェーズの可視化された実行計画の詳細を確認できます。 |
実行計画詳細の表示
最適化明細リストから対象の最適化タスクを見つけ、
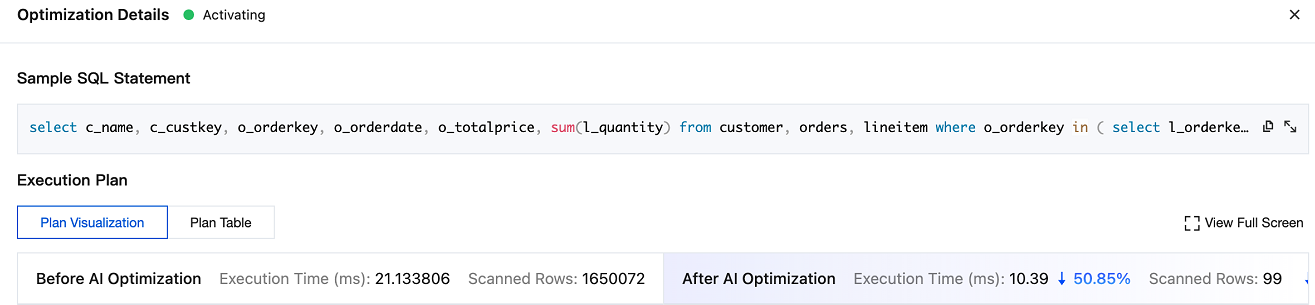
SQL文サンプル
SQL文サンプルで、現在の実行計画のSQLコマンド詳細を確認できます。
計画の可視化
計画の可視化の下で、最適化前後の実行計画の状況を確認できます。これには最適化前後の実行時間の比較やスキャン行数の比較が含まれます。全画面表示をクリックすると、具体的な実行計画をより明確に照会できます。
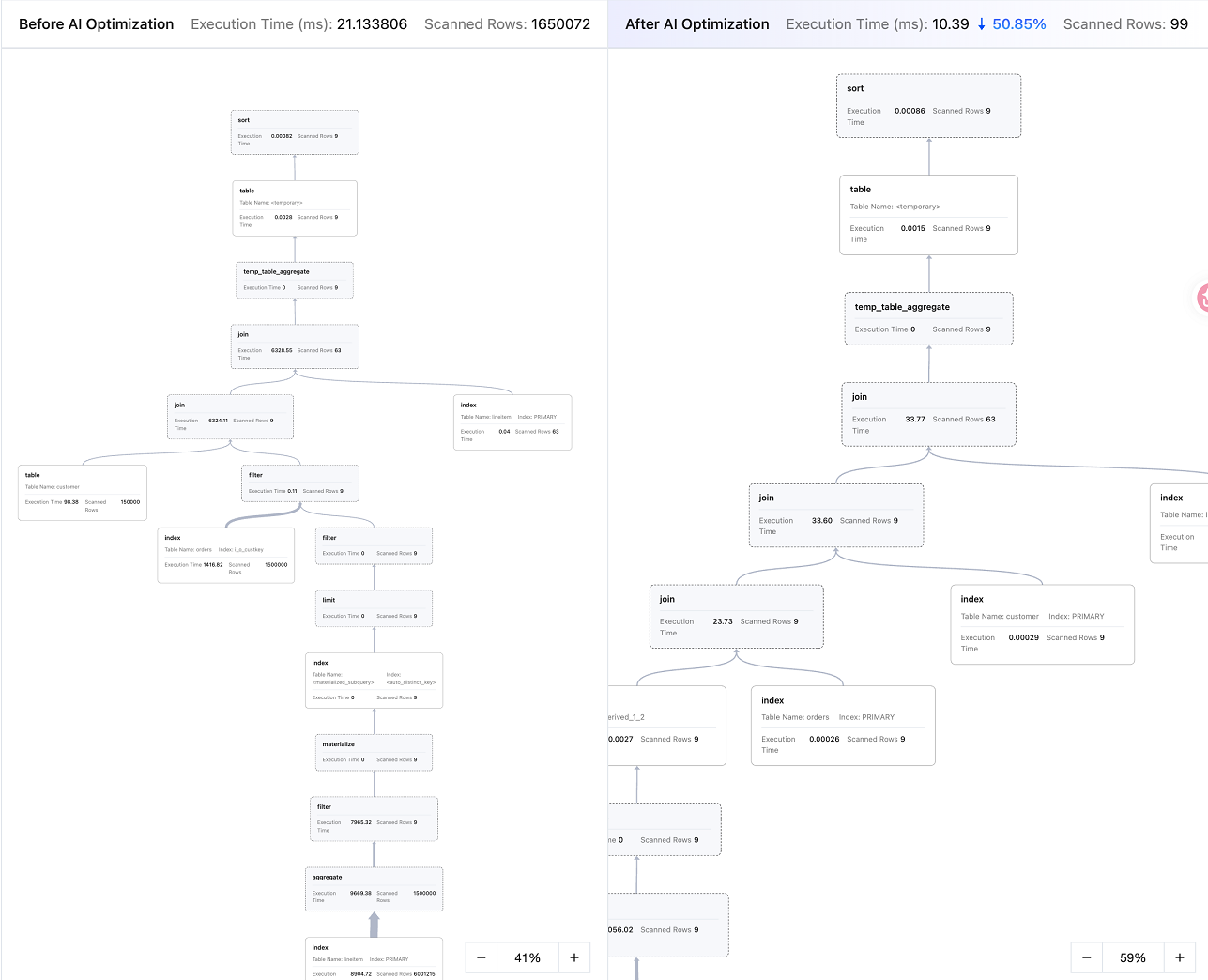
計画表
計画表の下で、最適化前後の実行計画表の状況を確認できます。これには最適化前後の実行時間の比較やスキャン行数の比較が含まれます。全画面表示をクリックすると、計画表明細をより明確に照会できます。
フィールド名称 | 説明 |
id | SELECTクエリのシーケンス番号です。SQL内のサブクエリの実行順序を示します。idが大きいほど先に実行され、idが同じ場合は上から順に実行されます。 例:1。 |
selectType | クエリタイプ。このステップのクエリの複雑さを示します。 例:PRIMARY。 |
table | アクセスするテーブル名。このステップでどのテーブルを読み取っているかを表示します。 例:nation。 |
partitions | マッチングしたパーティション。テーブルがパーティションテーブルの場合、ヒットしたパーティション名を表示します。非パーティションテーブルの場合は -- と表示されます。 例:--。 |
type | アクセスタイプ(主要パフォーマンス指標)。TDSQL-C for MySQLがデータをどのように検索するかを示します。 例:ALL。 |
possibleKeys | 使用可能なインデックス。AIオプティマイザが理論上使用可能と判断したインデックスのリストです。 例:PRIMARY。 |
key | 実際に使用されたインデックス。AIオプティマイザが最終的に使用を決定したインデックスです。 例:PRIMARY。 |
keyLen | インデックスキー長。使用されたインデックスフィールドの合計バイト数であり、インデックスが完全に利用されているかどうかを判断するために使用できます。 例:4。 |
ref | インデックス参照関係。key列のインデックスと比較される列または定数を表示します。 例:tpch1g.nation.n_nationkey。 |
rows | 見積もりスキャン行数。 例:382。 |
filtered | フィルタリング割合。条件フィルタリング後に残った行数が、見積もり行数に占める割合(0 - 100)を示します。値が小さいほど、フィルタリング効果が低いことを意味します。 例:100。 |
extra | 追加実行情報。 例:Using index。 |
フィードバック