Data consistency check compares table data between the source and target databases through Data Transfer Service (DTS) during data synchronization, providing comparison results and inconsistency details to help users quickly verify synchronization results. The data consistency check task is run independently and does not affect the normal business of the source database or the DTS tasks.
Note:
The consistency check is only for auxiliary data verification. Users are still required to perform data verification by themselves to ensure that the synchronization results meet the requirements.
Differences Between Independent Checks and Built-in Checks
Consistency checks are divided into two types: independent checks and built-in checks. Users can select an appropriate method based on their actual needs.
Comparison Item
Built-in Check
Independent Check
Definition
The consistency check service is integrated within the DTS task and is required to be initiated while the task is running. The check cannot be initiated once the DTS task ends.
The check service operates independently of the DTS task and selects identical data blocks from the source and target databases for comparison. Checks cannot be initiated after the DTS task ends.
Comparison scope
Only the synchronization objects selected in the DTS task are compared. Objects not selected in the DTS task from the source database are excluded from the check scope.
Only data written by DTS to the target database is compared; data manually written by users to the target database is not included in the check scope.
Synchronization objects not selected in the DTS task can be compared.
Data manually written by users to the target database can be compared.
Requirements during the check process
The source allows DML write operations but does not allow DDL write operations; otherwise, the check results may become inaccurate.
It is recommended to initiate a check when data is static, which means no data write operations are performed on the source or target; otherwise, the check results may become inaccurate.
Scenarios
Currently, the following synchronization links support data consistency checks:
MySQL/MariaDB/Percona/TDSQL-C MySQL/TDSQL MySQL > MySQL
MySQL/MariaDB/Percona/TDSQL-C MySQL/TDSQL MySQL > MariaDB
MySQL/MariaDB/Percona/TDSQL-C MySQL > TDSQL-C MySQL
MySQL/MariaDB/Percona/TDSQL-C MySQL/TDSQL MySQL > TDSQL MySQL
MySQL/MariaDB/Percona/TDSQL-C MySQL/TDSQL MySQL > TDSQL Boundless
Must-Knows and Constraints
1. The data consistency check task may increase the load on the source database instance. Therefore, it is recommended to perform these operations during off-peak hours.
2. Constraint comparison of checks:
Full checks and sampling checks: For tables without primary/unique keys, checks are supported if the number of rows is less than 50,000; checks are skipped if the number of rows exceeds 50,000.
Row quantity checks: No primary or unique key required for tables.
3. The current check task does not detect DDL operations. If users perform DDL operations on the source database during synchronization, inconsistent check results may occur. Users are required to re-initiate the check task to obtain accurate comparison results.
4. During data consistency checks, DTS enforces a 10-minute timeout limit for single queries on the source or target database. A single query refers to the query performed for each chunk check and the query for the row quantity check. If a single query exceeds 10 minutes (for example, when querying large tables on the source), the check task will fail.
5. Data checks are supported only for unidirectional and bidirectional synchronization. They are not supported in complex topologies, such as many-to-one, one-to-many, ring, or star synchronization.
6. If specific DML/DDL operations are selected or the Where clause filtering is applied in the synchronization task configuration, data inconsistency between the source and target databases may occur. In such cases, the built-in consistency check is not supported.
7. Configuring synchronization tasks as follows may result in inconsistent check results. Be aware of this when creating a check task.
If the data initialization type is not set to full data initialization, data inconsistency between the source and target may occur, ultimately leading to inconsistent check results.
If Conflict Ignore is enabled for primary key conflicts, data inconsistency between the source and the target may occur when conflicts arise, which will eventually lead to inconsistent data check results.
8. For existing synchronization tasks created before the release of the consistency check feature (January 12, 2023 for MySQL/MariaDB/TDSQL-C for MySQL; July 30, 2023 for links from TDSQL for MySQL to TDSQL for MySQL; October 20, 2023 for links between MySQL/MariaDB/Percona and TDSQL for MySQL), direct creation of check tasks is temporarily unsupported due to the DTS version being too low. To create such tasks, you need to submit a ticket to upgrade the version first.
9. When data consistency checks are performed on TDSQL for MySQL-related links, take note of the following items:
9.1 When the source or target is a distributed TDSQL for MySQL database, perform data consistency checks during off-peak hours; otherwise, inconsistent check results may occur.
9.2 Tables with virtual columns cannot be checked. If such tables exist, the check task may report errors.
10. Must-knows for the built-in check.
10.1 The scope of the built-in check only compares the selected database and table objects in the source database with those synchronized to the target database. If users write data to the target database during the synchronization, such data is excluded from the check scope. In addition, other advanced objects (such as stored procedures and functions) and views are not included. If structure initialization is not selected in the configuration for the synchronization task (indicating that table structures are not synchronized), table structures will not be checked during consistency checks.
10.2 The built-in check can be initiated when the synchronization task is running. If the user ends the synchronization task before the built-in check completes, the built-in check will fail.
10.3 As the built-in check requires creating a database named __tencentdb__ in the source database and writing data into the CheckSum table under this database, the consistency check will be skipped if the source database is set to read-only mode.
11. Limitations on independent check restrictions.
If you perform operations, such as column renaming, column filtering, and table renaming on tables in a data synchronization task, the following interaction constraints apply when creating subsequent independent checks.
11.1 Column renaming and column filtering are configured in the synchronization link: If Check Object is set to All Objects during an independent check, tables that have had column renaming and filtering applied can be checked.
11.2 Column renaming and column filtering are configured in the synchronization link: If Check Object is set to Custom Objects during an independent check, the selected columns for checking must be a subset of the filtered columns in the synchronized objects. Otherwise, tables that have had column renaming and filtering applied will be skipped during the check.
11.3 Table renaming is configured in the synchronization link: When an independent check is performed, if you set Check Object to Custom, you need to select table objects one by one and cannot select the entire database. Otherwise, the tables that have been renamed previously will be excluded from the check.
How It Works
Built-in Checks
DTS performs consistency checks for MySQL series databases based on the row mode (binlog_format = row). This mode enables accurate replication between the master and slave databases, ensuring data security.
The implementation principles are as follows:
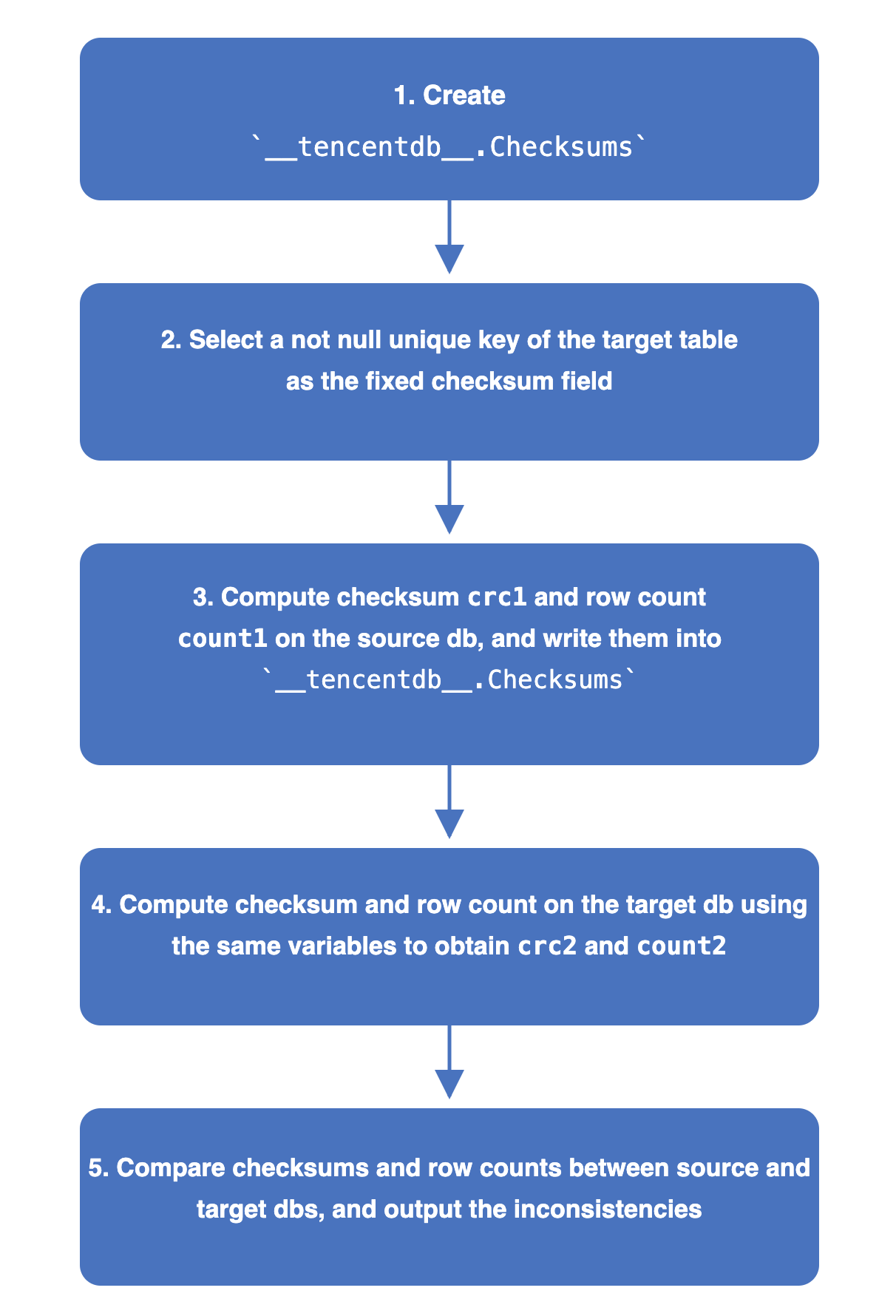
1. In the source database, create a check database named __tencentdb__.Checksums to store information about data comparison during the synchronization task.
2. The non-null unique key of the table to be checked is selected as the fixed field for the check.
3. The check value crc1 and number of rows (count1) of the source database are calculated and written to __tencentdb__.Checksums in the source database.
The calculation method of crc is similar to the chunk check. Based on the fixed check field, a fixed range is selected (for example, the data with primary keys from 1 to 1000 in Table A). The data is concatenated row by row to generate a crc value for each chunk. Meanwhile, the entire data of the source database is computed to produce crc1.
4. DTS parses binlog data in the row mode, reconstructs the SQL that wrote the check values in the source database, and then replays it on the target database.
The target database uses the same variables as the source database to compute the check value and row count, obtaining crc2 and count2 for the target database.
5. Compare the check values and row counts between the source and target databases, and display the comparison results.
Independent Checks
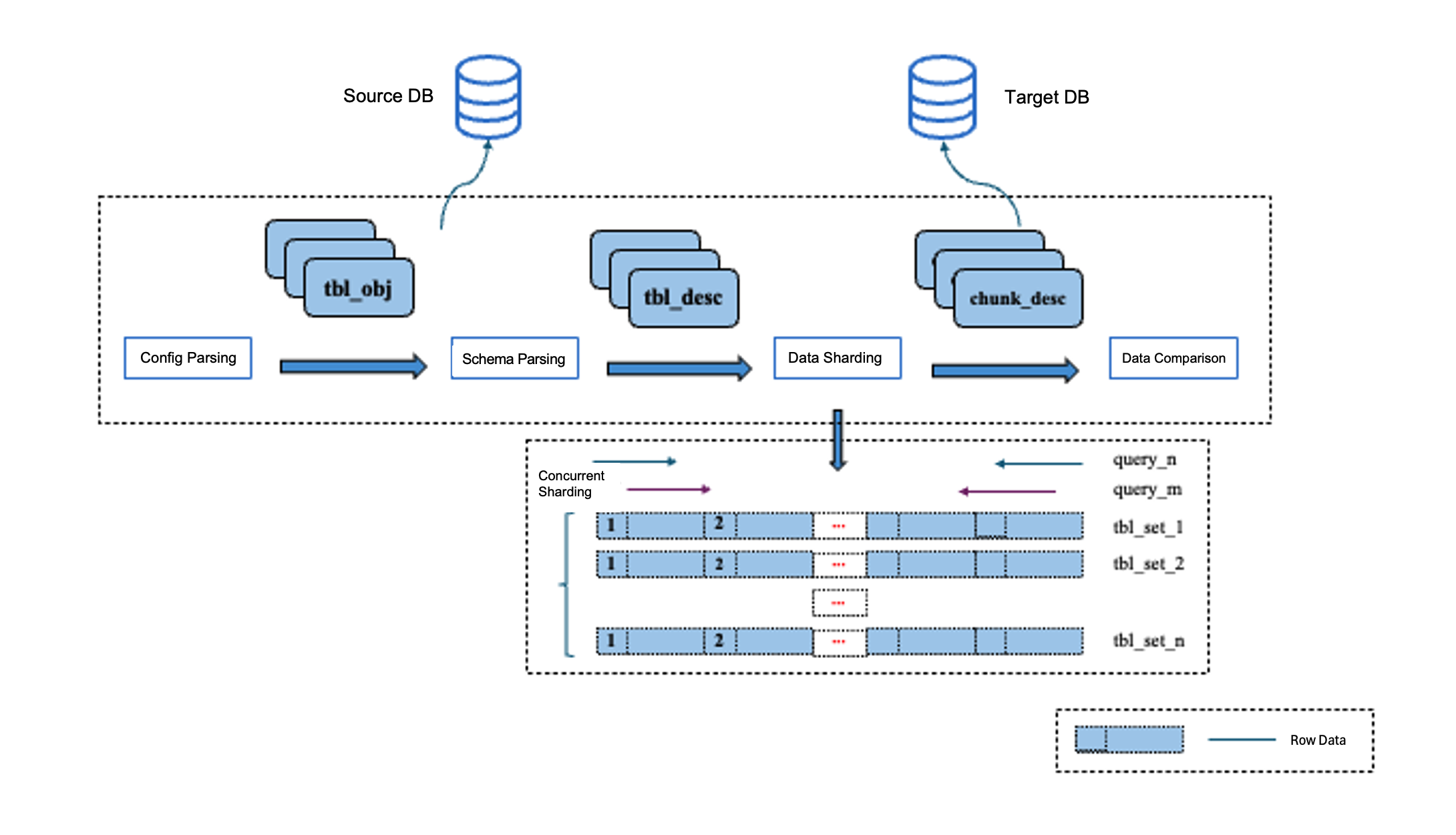
The independent check is a data comparison tool that operates independently from DTS data migration tasks. It performs data comparison by querying data from both the source and target in parallel, based on user-defined configuration files. To support data comparison between heterogeneous databases, data from different databases is converted according to unified data type mapping rules. In addition, to increase concurrency for data comparison and minimize the impact of delays in data synchronization, each table is split into slices, with each data shard serving as the smallest unit for data query and processing in the comparison.
The implementation principles are as follows:
1. Configuration parsing: It mainly involves identifying the databases and tables in the current data comparison task, processing renaming rules, and configuring the Where clause. The independent check allows users to configure different objects for data comparison, such as a whole instance, a whole database, or custom databases and tables. It allows users to set allowlists and blocklists for tables and columns, configure rename conversion rules for database, table, and column names, and supports setting Where filter conditions on tables. Through these configurations, users can select appropriate objects for data comparison based on their specific requirements.
2. Table structure parsing: It mainly includes steps such as parsing column names and types, querying character sets and collations, and querying primary keys, as well as non-null unique keys. For tables without primary keys or non-null unique keys: when the number of rows is less than or equal to 50,000, the independent check calculates crc values for data consistency comparison. Since no unique identifiers can be identified for the data, inconsistent row data or SQL statements for data correction cannot be accurately output for these tables. When the number of rows is greater than 50,000, data comparison for such tables is skipped. Column type parsing is particularly critical in heterogeneous scenarios. Based on unified type mapping rules, data from different sources is converted to a consistent in-memory data type, with column type parsing forming the foundation of this key process.
3. Data slicing: To enhance parallelism in data querying and comparison, the independent check splits table data into slices, with each data shard serving as the smallest unit for data querying and comparison.
The independent check uses a primary key-based sequential slicing strategy for MySQL databases. This is because MySQL organizes its data using the B+ tree structure, where range queries based on primary keys deliver higher efficiency with minimal I/O consumption. A typical data slicing algorithm used is based on the table's minimum and maximum primary key values, as well as the primary key order. It traverses all primary key values and queries the upper and lower boundary values (primary key values) of slices in a fixed chunk size each time, thereby defining the range of each data slice. The process further optimizes slicing through a multi-level concurrency strategy. First, for sharded or partitioned tables, data is split into multiple data segments by shard or partition to improve slicing parallelism. Second, within each data segment, a bidirectional approximation strategy is applied to concurrently perform data slicing from both ends.
4. Data comparison: It mainly involves data querying, data type conversion, and data consistency comparison. Data type conversion is a critical step in this phase. Due to differences in column types across heterogeneous databases, we convert column types from different databases into standardized in-memory data types based on predefined type mapping rules before performing data comparisons between them. This process also addresses differences in character set encoding, time types and ranges, and floating-point precision between heterogeneous databases to ensure accurate data comparison. The independent check compares whether each row of data is consistent based on primary keys or unique keys. For inconsistent data, it outputs specific data field differences and queries SQL to help users quickly locate issues. In addition, it generates SQL statements for correcting inconsistent data, facilitating data repair.
Creating a Data Consistency Check Task
Automatic Triggering
You can enable the data consistency check task when creating a DTS synchronization task. The data consistency check task is automatically triggered once the subsequent task proceeds to the incremental synchronization step.
On the Set Consistency Check page, select Enable data consistency verification, configure the parameters, and then click Next.
Full check: All data in the source and target databases is compared when a check task is initiated.
Verification Benchmark
Both ends: Use data from the source and target as the check benchmark.
Verification Parameters
Thread Count
The value range is 1–8. Select an appropriate value according to the actual situation. Increasing the number of threads can accelerate the consistency check speed, but it will also increase the load on the source and target databases.
Review count
Set the number of rechecks.
If the first full data check result is inconsistent, the background will re-initiate a check of the inconsistent data identified during the full check.
Recheck time interval
Set the interval for rechecks.
Verified Object option
Check Object
All sync objects: The check scope includes all objects selected for the synchronization task.
Custom: Select specific objects from the selected synchronization objects for checking.
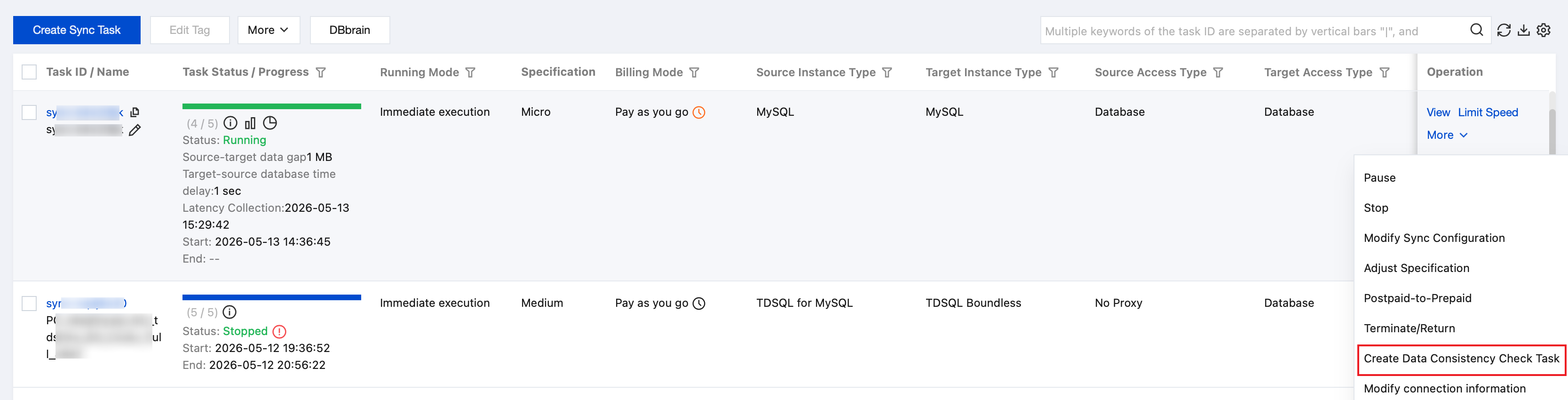
2. On the Data Sync page, select the synchronization task to be checked, and choose More > Create Data Consistency Check Task in the Operation column.
Note:
A data consistency check task can only be created when the data gap between the source and target databases is less than 100 MB. If the button on the page is grayed out, it indicates that the synchronization task status does not meet the requirements. Possible causes include specific DML or DDL operations selected in the task configuration, filters applied through the Where clause, task failures, a data gap exceeding 100 MB, or a complex synchronization topology.
3. On the Consistency Check page, click Create Data Consistency Check Task.
Note:
If a consistency check task already exists, you can click Create Similar Task in the Operation column and configure the related parameters.
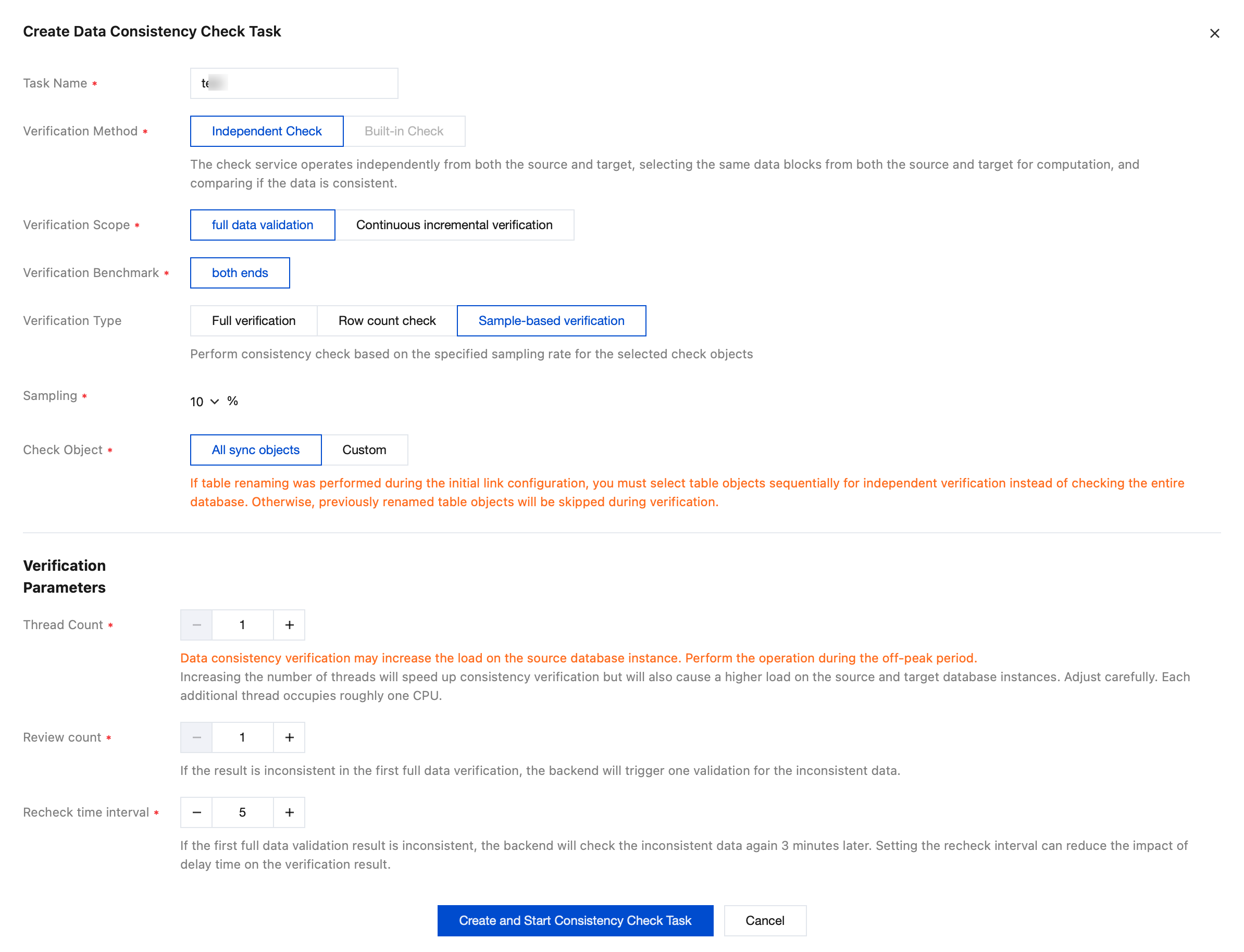
4. In the pop-up dialog box, click Create and Start Consistency Check Task after configuring the data consistency check parameters.
Parameter
Description
Task Name
Name of the created consistency check task.
Verification Method
Independent Check: The check service serves independently from the DTS task and selects the same data blocks from both the source and target for comparison. Check tasks cannot be initiated once the DTS task stops running.
Built-in Check: The consistency check service is integrated within the DTS task and is required to be initiated while the task is running. The check cannot be initiated once the DTS task stops running.
Verification Scope
Full data validation: All data in the source and target databases is compared when a check task is initiated.
Verification Benchmark
Both ends: Use data from the source and target as the check benchmark.
Verification Type
Full verification: Perform a consistency check on the full data of the selected check objects.
Sample-based verification: Select a certain proportion of the selected check objects for checking.
Row count check: Compare only the number of rows in the selected check objects.
Sampling
Configure the sampling ratio, which can be 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, or 90%.
Note:
This parameter needs to be configured only when Verification Type is set to Sample-based verification.
Check Object
All sync objects: The check scope includes all objects selected for the synchronization task.
Custom: Select specific objects from the selected synchronization objects for checking.
Thread Count
The value range is 1–8. Select an appropriate value according to the actual situation. Increasing the number of threads can accelerate the consistency check speed, but it will also increase the load on the source and target databases.
Review count
Set the number of rechecks.
If the first full data check result is inconsistent, the background will re-initiate a check of the inconsistent data identified during the full check.
Recheck time interval
Set the interval for rechecks.
Viewing the Data Consistency Check Results
1. On the Data Sync page, select the synchronization task to be viewed, and choose More > Create Data Consistency Check Task in the Operation column.
2. Click View in the Operation column to view the check results.
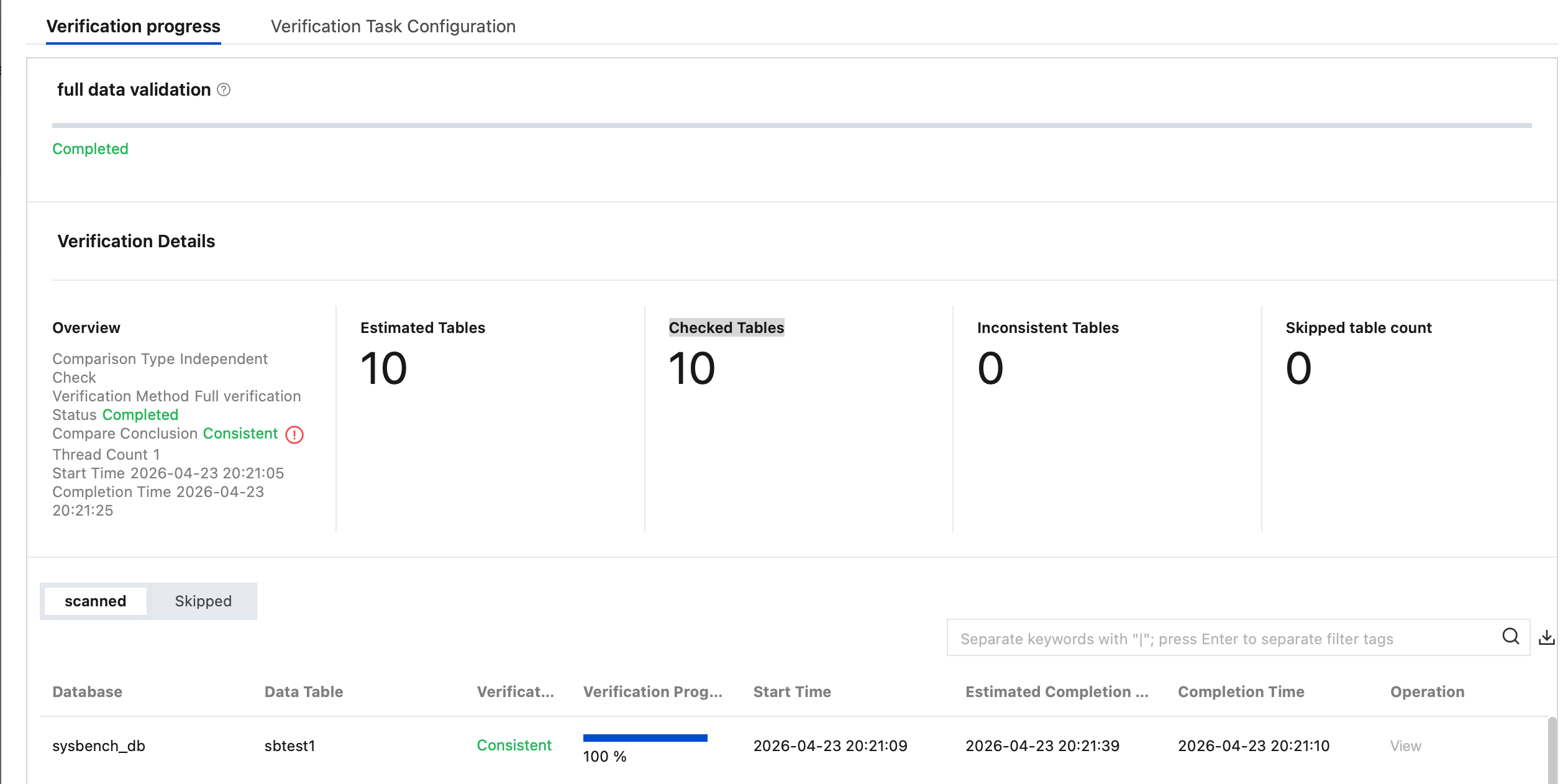
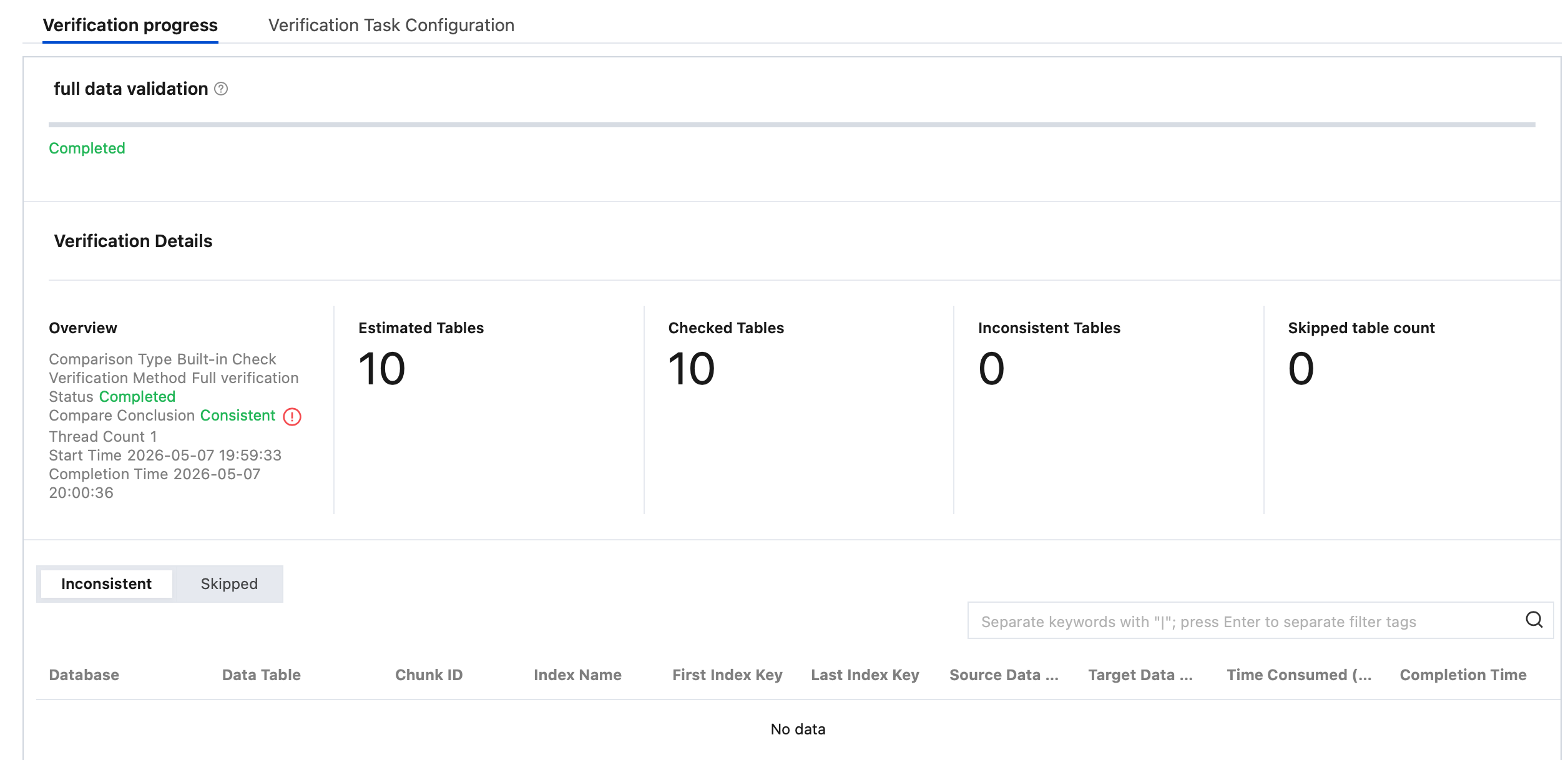
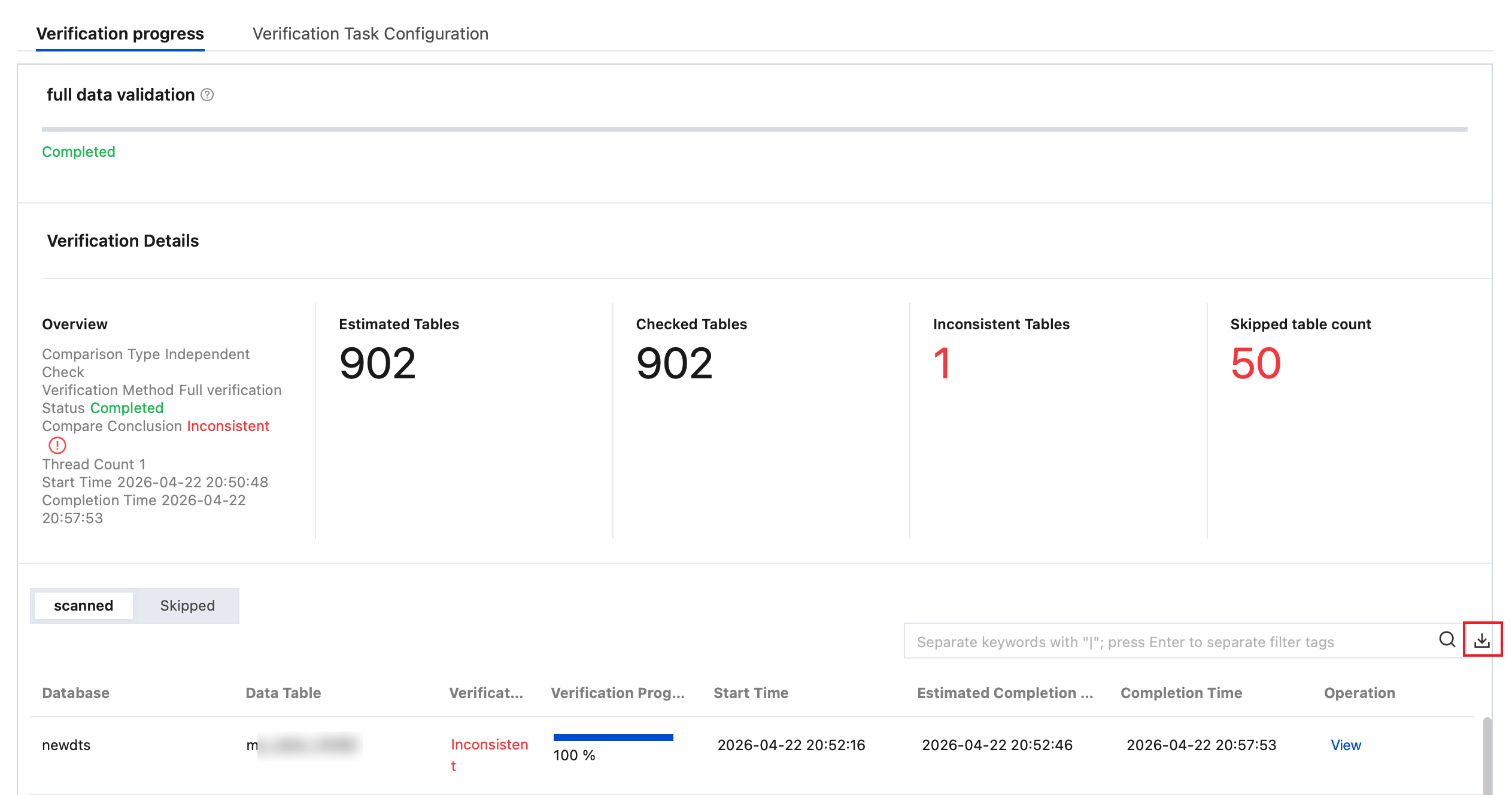
3. View the check results.
Full Check: View Estimated Tables, Detected Tables, Inconsistent Tables, and Skipped tables count.
Estimated Tables: The estimated number of tables to be checked. It may slightly differ from the actual number of checked tables, as calculating an exact total number could affect overall check performance.
Reasons for Unchecked Tables: The table has no primary key or non-null unique key, is empty, uses an unsupported engine type, or does not exist.
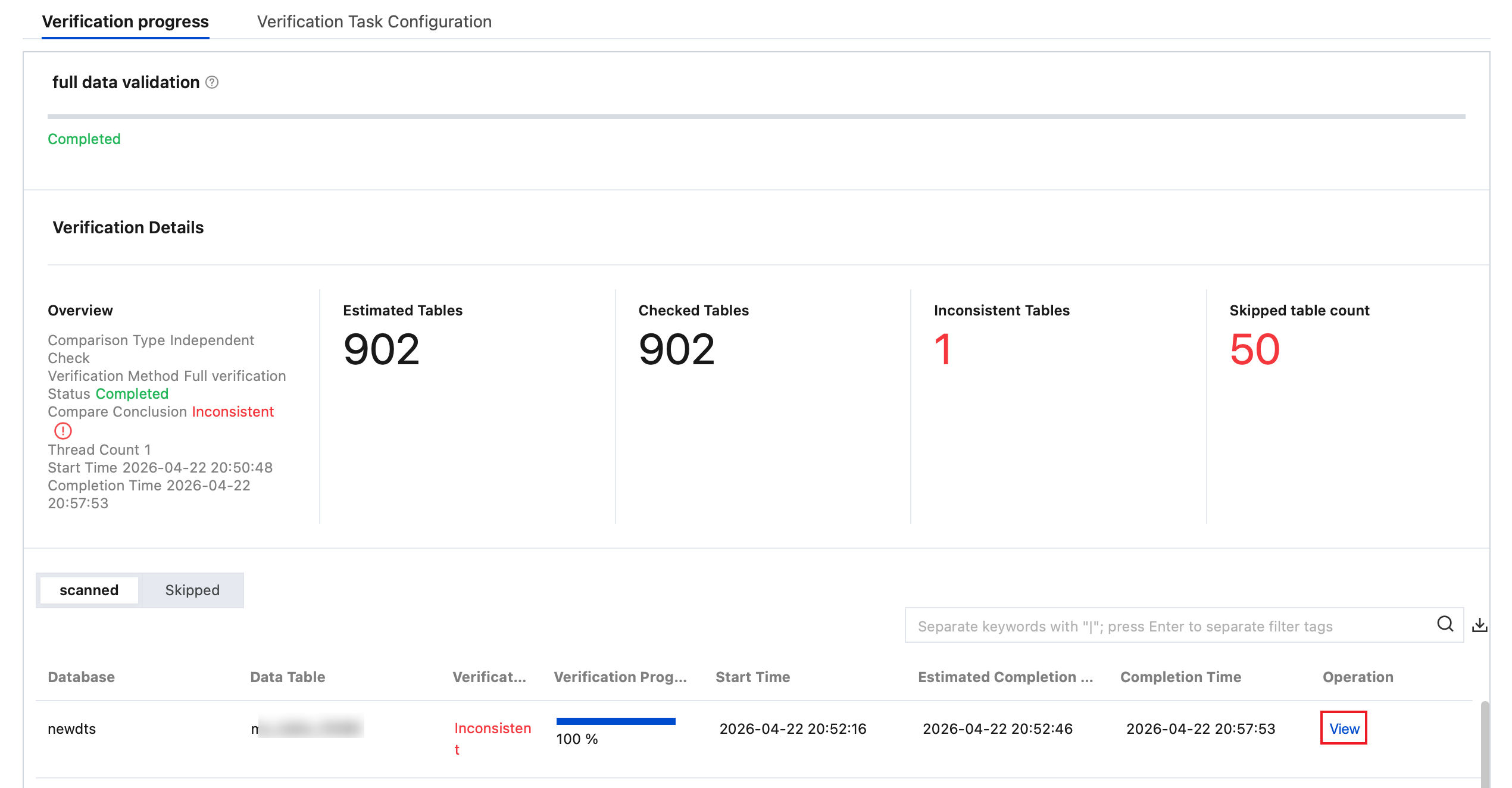
4. View inconsistency details.
In the Built-in Check scenario, for inconsistent results, you need to manually compare the corresponding content between the source and target databases.
Follow the parameters prompted on the page, including Database, Data Table, Index Name, First Index Key, and Last Index Key, to locate the specific position for comparison.
Operations for reference:
1. Log in to the source database and query the prompted index range.
select * from table_name where col_index >=1 and col_index <=5;
2. Log in to the target database and query the prompted index range.
3. Compare the data discrepancy between the target and source.
Independent check scenario
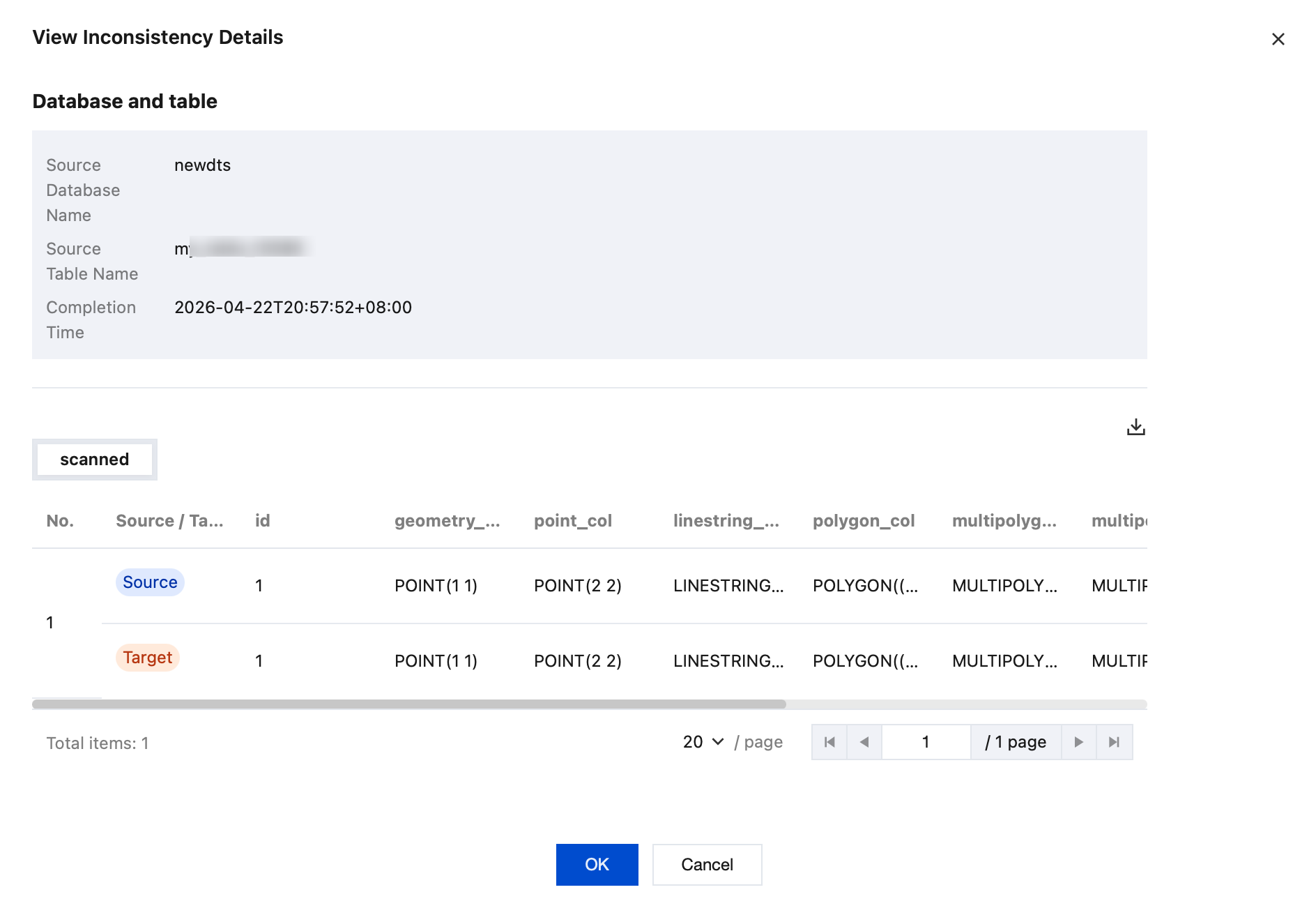
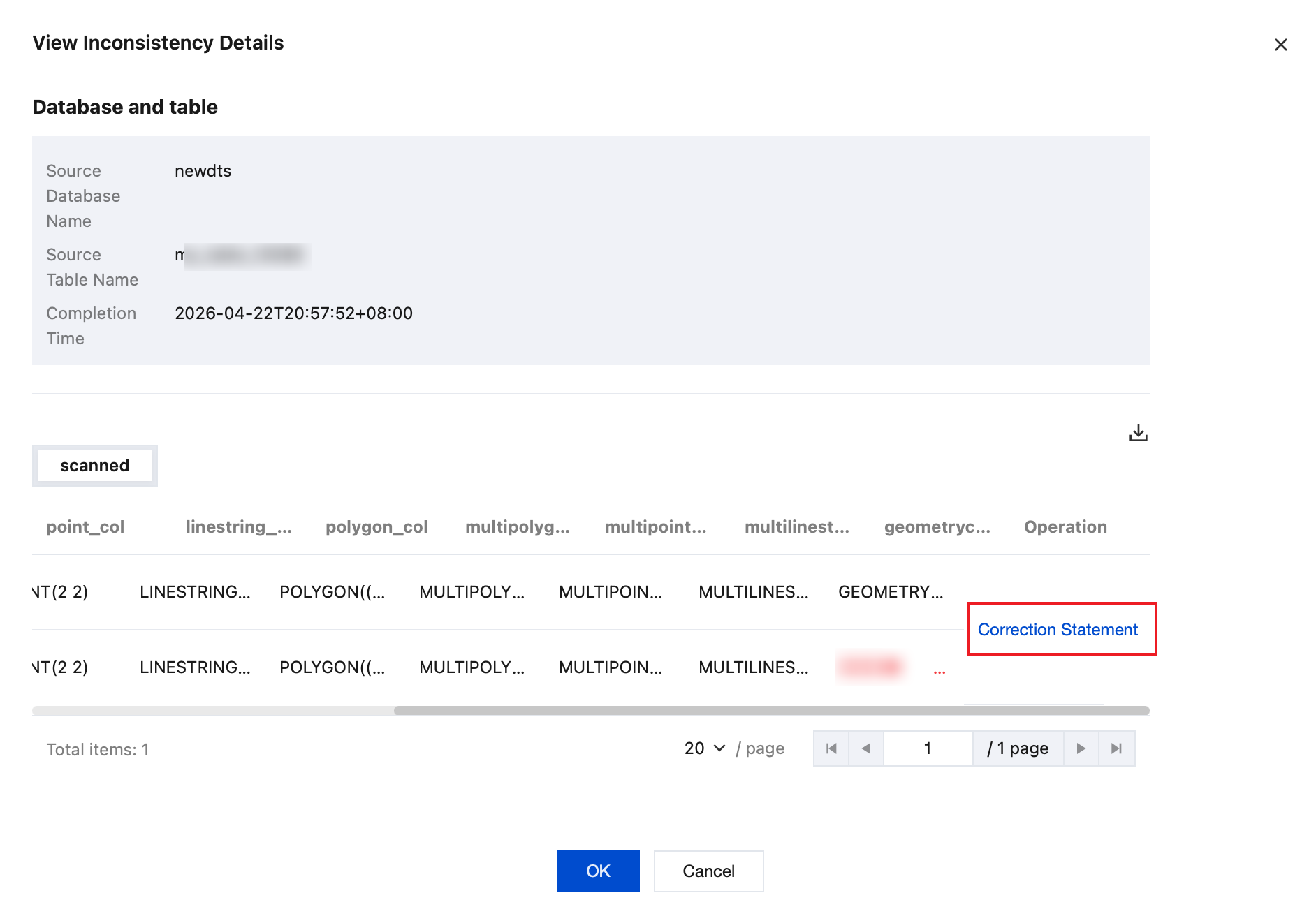
4.1.1 In the Detected section, click View in the Operation column of the corresponding table to view inconsistent data details.
4.1.2 View inconsistency details in the pop-up dialog box.
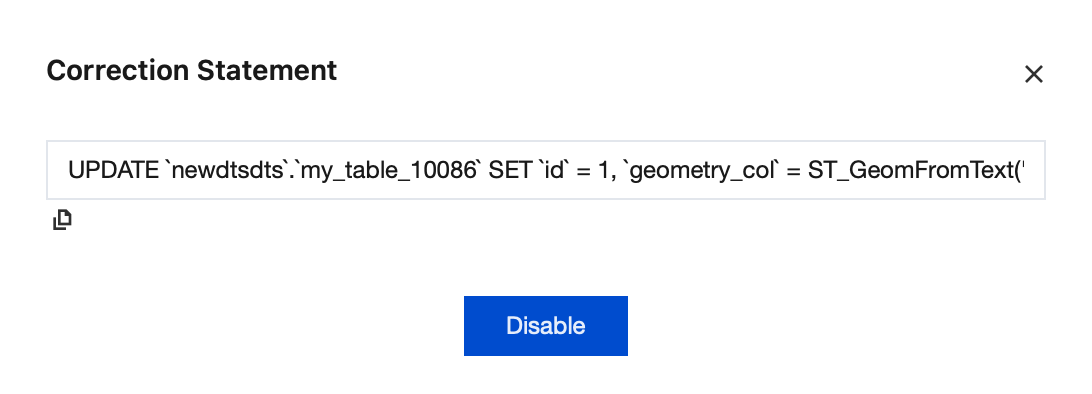
4.1.3 In the Operation column, click Correction Statement.
View the correction statement.
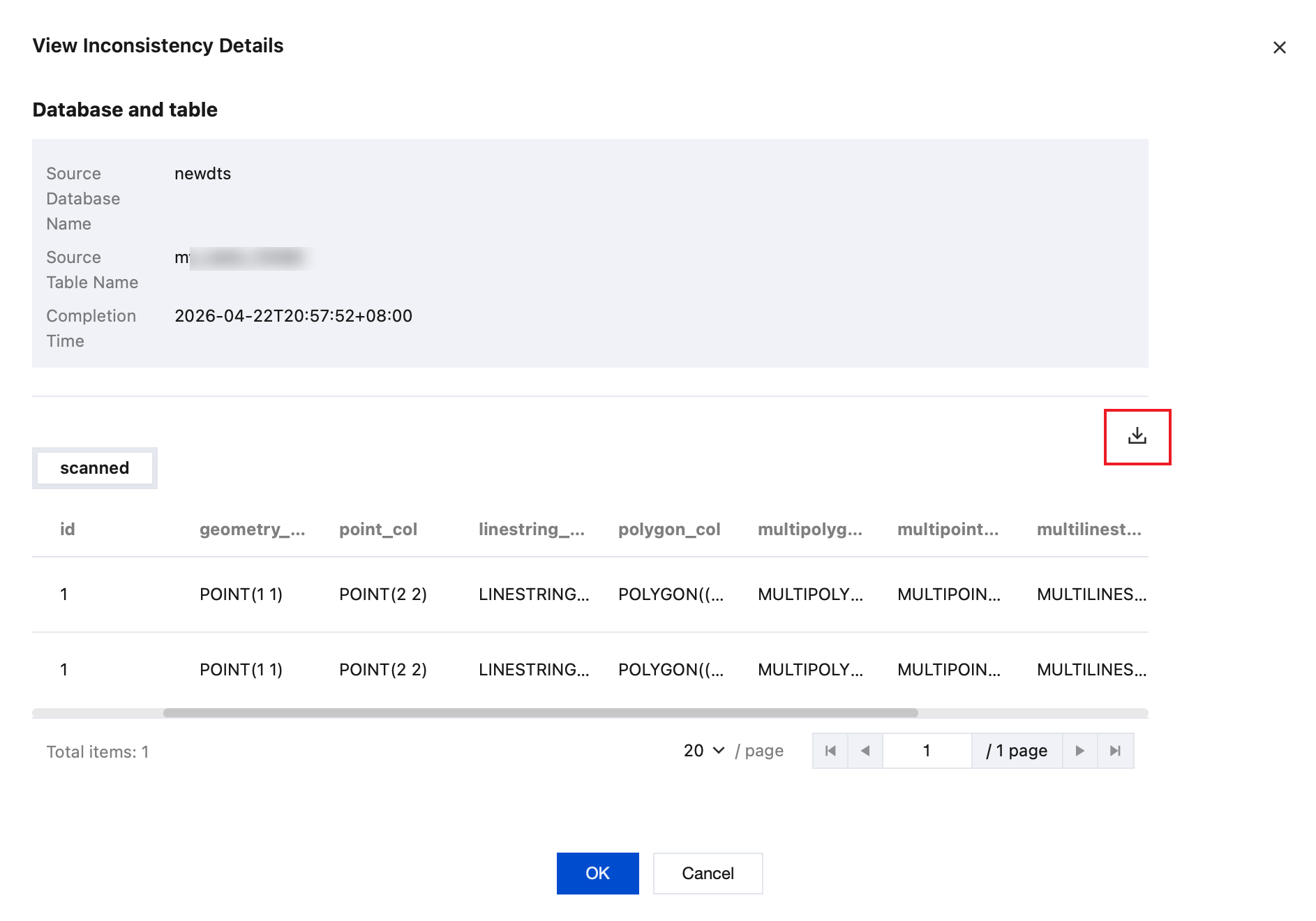
4.1.4 On the right side of the dialog box, click
to download inconsistency details.
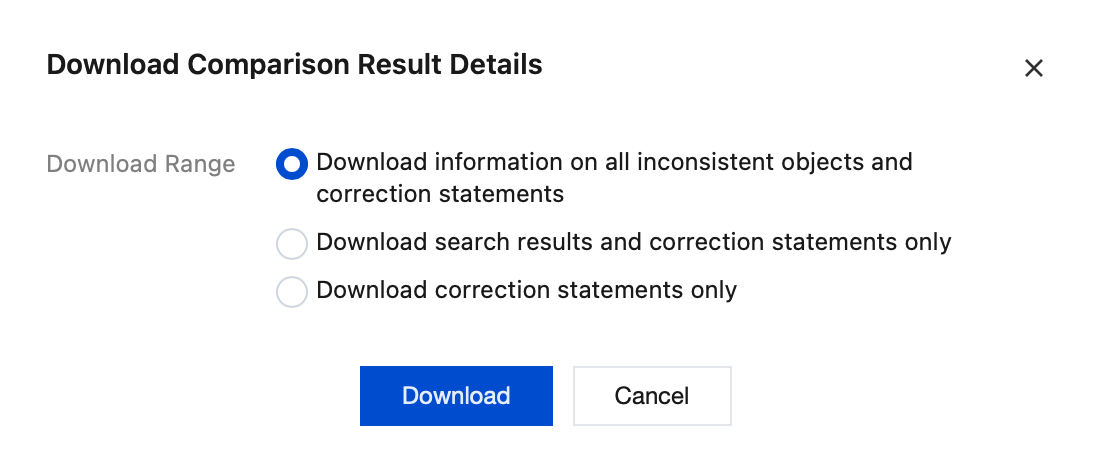
You can download inconsistent information and correction statements, or only the correction statements.
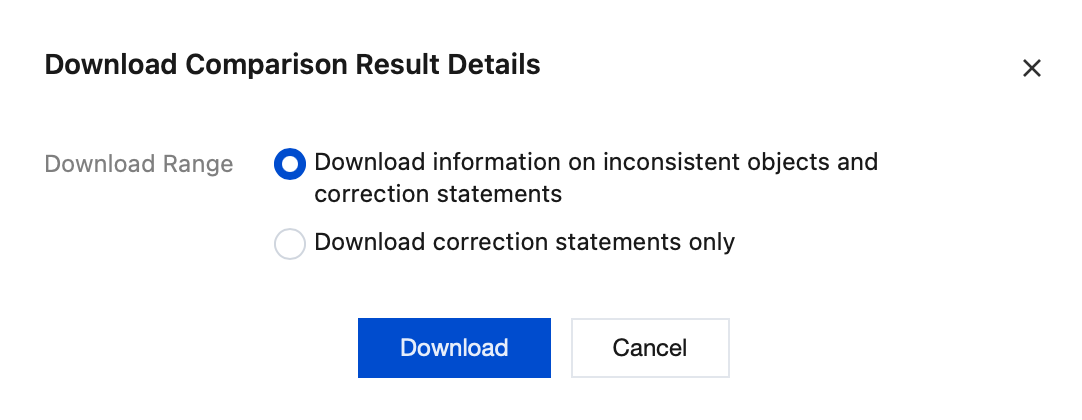
5. Download the comparison result details.
5.1 On the Verification Progress page, click
on the right to download the comparison result details.