在作业管理界面内您可以查看作业概览、集群概览等。
通过概览,您可以直观查看当前空间的作业情况(作业的类型数量,作业运行停止数量以及作业异常的数量),查看空间绑定集群的详情等。
说明:
指标告警作业总数为统计本空间内最近1天有未恢复的告警的作业数量。
事件异常作业总数为统计本空间内最近6个小时有异常事件的作业数量。
集群概览展示本空间绑定的包年包月集群的详情。

【版权声明】
©2013-2026 腾讯云版权所有
本⽂档著作权归腾讯云单独所有,未经腾讯云事先书⾯许可,任何主体不得以任何形式复制、修改、抄袭、传播全部或部分本⽂档内容。
【商标声明】

及其他腾讯云服务相关的商标均为腾讯集团下的相关公司主体所有。另外,本⽂档涉及的第三⽅主体的商标,依法由权利⼈所有。
【服务声明】
本⽂档意在向客户介绍腾讯云全部或部分产品、服务的当时的整体概况,部分产品、服务的内容可能有所调整。您所购买的腾讯云产品、服务的种类、服务标准等应由您与腾讯云之间的商业合同约定,除⾮双⽅另有约定,否则,腾讯云对本⽂档内容不做任何明⽰或默⽰的承诺或保证。
最近更新时间:2023-11-08 10:14:44
最近更新时间:2023-11-08 10:15:15
最近更新时间:2023-11-08 10:11:57
字段 | 含义 |
作业名称 | 该作业的名称(在创建作业中自己填写的自定义名称,可更改) |
集群 | 作业所在集群名称 |
集群 ID | 作业所在集群 ID |
作业 ID | 该作业的 Serial ID 信息,通常以 cql- 开头(随机分派,不可更改) |
作业类型 | 作业的类型,目前有 JAR、SQL 、Python 和 ETL 四种类型 |
运行状态 | 作业的当前状态,例如未初始化、未发布、操作中、运行中、停止、故障等 |
地域 | 作业运行的集群所在的地理大区,例如广州、上海、北京等 |
可用区 | 作业运行的集群的可用区,例如上海三区 |
线上版本 | 正在运行的版本 |
创建时间 | 作业被创建的时间点 |
累计运行时长 | 作业历史上总共运行的时长 |
开始运行时间 | 作业本次开始运行的时间点 |
运行时长 | 作业本次运行所持续的时长 |
计算资源 | 作业本次运行所占用的 CU 数 = JobManager CU 数 + TaskManager CU 数,其中:JobManager CU 数 = 1(每个作业默认占用1个)TaskManager CU 数 = 最大并行度 * 单个并行度的 CU 数 |
最近更新时间:2023-11-08 10:12:49
最近更新时间:2023-11-08 10:09:41
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.BATCH);
env_settings = EnvironmentSettings.new_instance().in_batch_mode().use_blink_planner().build()table_env = TableEnvironment.create(env_settings)
最近更新时间:2025-11-11 16:26:52
state.backend: filesystem
restart-strategy: fixed-delayrestart-strategy.fixed-delay.attempts: 100restart-strategy.fixed-delay.delay: 5 s
taskmanager.memory.jvm-overhead.fraction: 0.3
execution.checkpointing.mode: AT_LEAST_ONCE
pipeline.operator-chaining: false
execution.checkpointing.timeout: 3000s
execution.checkpointing.timeout: 1000s
set CHECKPOINT_TIMEOUT= '1000 s';
DELETE_ON_CANCELLATION, RETAIN_ON_CANCELLATION 和 RETAIN_ON_SUCCESS。Flink 作业默认快照保存策略为 DELETE_ON_CANCELLATION,如果不设置该参数,自动采用默认策略。快照保存策略 | 快照清理行为 |
DELETE_ON_CANCELLATION (默认策略) | 1. 停止时快照,原有 Checkpoint 删除,无法从 Checkpoint 恢复 2. 停止时不进行快照,原有 Checkpoint 删除,无法从 Checkpoint 恢复 |
RETAIN_ON_CANCELLATION | 1. 停止时快照,原有 Checkpoint 删除,无法从 Checkpoint 恢复 2. 停止时不进行快照,原有 Checkpoint 不删除,可以从 Checkpoint 恢复 |
RETAIN_ON_SUCCESS | 1. 停止时快照,原有 Checkpoint 不删除,可以从 Checkpoint 恢复 2. 停止时不进行快照,原有 Checkpoint 不删除,可以从 Checkpoint 恢复 |
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_SUCCESS
禁用参数 |
kubernetes.container.image |
kubernetes.jobmanager.cpu |
taskmanager.cpu.cores |
kubernetes.taskmanager.cpu |
jobmanager.heap.size |
jobmanager.heap.mb |
jobmanager.memory.process.size |
taskmanager.heap.size |
taskmanager.heap.mb |
taskmanager.memory.process.size |
taskmanager.numberOfTaskSlots |
env.java.opts(但是允许用户配置 env.java.opts.taskmanager 和 env.java.opts.jobmanager 两个独立参数) |
最近更新时间:2023-11-07 18:31:56
2048。 128,若需要将这些作业扩容至超过128个并行度,则需要手动修改该参数值,并丢弃现有运行时状态后重新启动作业。pipeline.max-parallelism 的最小取值是作业中的所有算子的最大并行度,例如一个作业有5个算子,各个算子的并行度依次是[1, 5, 100, 2, 2],那么 pipeline.max-parallelism 能设置的最小值是100。pipeline.max-parallelism 最大值硬限制为16384,但我们强烈建议将 pipeline.max-parallelism 维持在 2048 及以下的数值,以避免增加无谓的运行开销,或降低作业的处理能力。最近更新时间:2023-11-08 10:06:05
最近更新时间:2023-11-08 10:07:48
最近更新时间:2023-11-07 18:07:31
Status.JVM.CPU.Load 代表 JVM 最近 CPU 利用率Status.JVM.GarbageCollector.<GarbageCollector>.Count,GC(垃圾回收)次数Status.JVM.GarbageCollector.<GarbageCollector>.Time,GC(垃圾回收)时间Status.JVM.CPU.Load 代表 JVM 最近 CPU 利用率Status.JVM.GarbageCollector.<GarbageCollector>.Count,GC(垃圾回收)次数Status.JVM.GarbageCollector.<GarbageCollector>.Time,GC(垃圾回收)时间最近更新时间:2023-11-08 10:19:21
最近更新时间:2023-11-08 16:37:11
字段名 | 说明 | 例 |
instanceId | 作业ID | cql-xxxxxx |
folderId | 作业所在目录ID | folder-xxxxxxxx |
creatorUin | 作业创建人uin | 123456 |
clusterId | 作业所在集群ID | cluster-xxxxxxxx |
workSpaceId | 作业所在工作空间ID | space-xxxxxxxx |
最近更新时间:2023-11-07 18:17:39
指标中文名 | 指标含义 | 示例值 |
作业每秒输入的记录数 | 作业所有数据源(Source)每秒输入的数据总条数 | 22478.14 Record/s |
作业每秒输出的记录数 | 作业所有数据目的(Sink)每秒输出的数据总条数 | 12017.09 Record/s |
作业每秒输入的数据量 | 作业所有数据源(Source)每秒输入的数据总量(仅对 Kafka Source 有效) | 786576 Byte/s |
作业每秒输出的数据量 | 作业所有数据目的(Sink)每秒输出的数据总量(仅对 Kafka Sink 有效) | 156872 Byte/s |
算子计算总耗时 | 数据流经各个算子时的耗时总和。可能存在采样误差,数值仅供参考 | 275 ms |
目的端 Watermark 延时 | 当前时间戳与数据目的(Sink)输入侧 Watermark 之间的差值(多个 Sink 则取最大值) | 5432 ms |
TaskManager CPU 使用率 | 作业中所有 TaskManager 的平均 CPU 使用率 | 23.85% |
TaskManager 堆内存使用率 | 作业中所有 TaskManager 的平均堆内存使用率 | 57.12% |
TaskManager 堆内存用量 | 作业中所有 TaskManager 的当前堆内存用量总和 | 830897056.00 Bytes |
TaskManager 已提交的堆内存容量 | 作业中所有 TaskManager 已提交(committed)的堆内存容量总和 | 4937220096.00 Bytes |
TaskManager 堆内存最大容量 | 作业中所有 TaskManager 的堆内存最大(max)容量总和 | 4937220096.00 Bytes |
TaskManager 非堆内存用量 | 作业中所有 TaskManager 非堆内存(JVM 元空间、代码缓存等)用量总和 | 296651064.00 Bytes |
TaskManager 已提交的非堆内存容量 | 作业中所有 TaskManager 已提交(committed)的非堆内存(JVM 元空间、代码缓存等)用量总和 | 103219200.00 Bytes |
TaskManager 非堆内存最大容量 | 作业中所有 TaskManager 非堆内存(JVM 元空间、代码缓存等)最大容量总和 | 780140544.00 Bytes |
所有 TaskManager JVM 的物理内存用量的最大值 | 作业中所有 TaskManager 所在的 JVM 的物理内存用量(RSS)的最大值,包括堆内、堆外、Native 等所有区域的总内存用量。该指标可用于对容器 OOM Killed 事件的预警 | 3597035110.00 Bytes |
TaskManager 堆外直接内存缓存数 | 作业中所有 TaskManager 堆外直接内存(Direct Buffer Pool)中的缓存(Buffer)个数之和 | 10993.00 Items |
TaskManager 堆外直接内存用量 | 作业中所有 TaskManager 堆外直接内存(Direct Buffer Pool)的用量之和 | 360328431.00 Bytes |
TaskManager 堆外直接内存总容量 | 作业中所有 TaskManager 堆外直接内存(Direct Buffer Pool)的最大容量之和 | 360328431.00 Bytes |
TaskManager 堆外映射内存缓存数 | 作业中所有 TaskManager 堆外映射内存(Mapped Buffer Pool)中的缓存(Buffer)个数之和 | 4 Items |
TaskManager 堆外映射内存用量 | 作业中所有 TaskManager 堆外映射内存(Mapped Buffer Pool)的用量之和 | 33554432.00 Bytes |
TaskManager 堆外映射内存总容量 | 作业中所有 TaskManager 堆外映射内存(Mapped Buffer Pool)的最大容量之和 | 33554432.00 Bytes |
JobManager 老年代 GC 次数 | 当前作业 JobManager 老年代 GC 次数 | 3.00 Times |
JobManager 老年代 GC 时间 | 当前作业 JobManager 老年代 GC 时间 | 701.00 ms |
JobManager 年轻代 GC 次数 | 当前作业 JobManager 年轻代 GC 次数 | 53.00 Times |
JobManager 年轻代 GC 时间 | 当前作业 JobManager 年轻代 GC 时间 | 4094.00 ms |
最近一次的 Checkpoint 耗时 | 当前作业最近一次的 Checkpoint 耗时 | 723.00 ms |
最近一次的 Checkpoint 大小 | 当前作业最近一次的 Checkpoint 大小 | 751321.00 Bytes |
TaskManager 老年代 GC 次数 | 作业中所有 TaskManager 老年代 GC 次数之和 | 9.00 Times |
TaskManager 老年代 GC 时间 | 作业中所有 TaskManager 老年代 GC 时间之和 | 2014.00 ms |
TaskManager 年轻代 GC 次数 | 作业中所有 TaskManager 年轻代 GC 次数之和 | 889.00 Times |
TaskManager 年轻代 GC 时间 | 作业中所有 TaskManager 年轻代 GC 时间之和 | 15051.00 ms |
Checkpoint 成功完成次数 | 当前作业 Checkpoint 成功完成次数 | 11.00 Times |
Checkpoint 失败次数 | 当前作业 Checkpoint 失败(例如超时、遇到异常等)的次数 | 1.00 Times |
正在进行的 Checkpoint 个数 | 当前作业进行中(未完成)的 Checkpoint 个数 | 1.00 Times |
Checkpoint 总次数 | Checkpoint 总次数(进行中、已完成和失败的总和) | 13.00 Times |
严重异常数据个数 | 算子中发生严重异常(例如抛出各种 Exception)的数据个数,如果大于1则会影响 Exactly-Once 语义(试验参数,仅供参考) | 0.00 Times |
当前实例崩溃重启次数 | 当前实例 JobManager 记录的任务崩溃重启次数(不含 JobManager 退出后作业重新拉起的场景) | 10.00 Times |
JobManager 堆内存使用率 | 当前作业 JobManager 堆内存使用率 | 31.34% |
JobManager 堆内存的用量 | 当前作业 JobManager 堆内存的用量 | 1040001560.00 Bytes |
JobManager 已提交的堆内存容量 | 当前作业 JobManager 已提交(committed)的堆内存容量 | 3318218752.00 Bytes |
JobManager 堆内存最大容量 | 当前作业 JobManager 堆内存最大容量 | 3318218752.00 Bytes |
JobManager 非堆内存用量 | 当前作业 JobManager 非堆内存(JVM 元空间、代码缓存等)用量 | 117362656.00 Bytes |
JobManager 已提交的非堆内存容量 | 当前作业已提交(committed)的 JobManager 非堆内存(JVM 元空间、代码缓存等)容量 | 122183680.00 Bytes |
JobManager 非堆内存最大容量 | 当前作业 JobManager 非堆内存(仅限 JVM 元空间、代码缓存等)的最大容量 | 780140544.00 Bytes |
JobManager 所在的 JVM 的物理内存用量 | 当前作业 JobManager 所在的 JVM 的物理内存用量(RSS),包括堆内、堆外、Native 等所有区域的总内存用量。该指标可用于对容器 OOM Killed 事件的预警 | 3597035110.00 Bytes |
JobManager CPU 使用率 | 当前作业 JobManager 的 CPU 使用率 | 7.12% |
JobManager CPU 使用时长 | 当前作业 JobManager CPU 使用时长(毫秒) | 834490.00 ms |
作业中断运行时间 | 对于失败或恢复等非运行状态的作业,表示本次中断运行的时长。对于正在运行中的作业,值为0 | 1088466.00 ms |
作业无中断持续执行的时间 | 对于运行中的作业,表示当次作业持续处于运行中的时长 | 202305.00 ms |
作业重启耗时 | 作业最近一次重启耗时 | 197181.00 ms |
作业最近一次恢复的时间戳 | 作业最近一次从快照恢复的 Unix 时间戳(以毫秒为单位,如果未恢复过则是-1) | 1621934344137.00 ms |
JobManager 堆外映射内存缓存数 | JobManager 堆外映射内存(Mapped Buffer Pool)中的缓存(Buffer)个数 | 4.00 Items |
JobManager 堆外映射内存的使用量 | JobManager 堆外映射内存(Mapped Buffer Pool)的用量 | 33554432.00 Bytes |
JobManager 堆外映射内存的总容量 | JobManager 堆外映射内存(Mapped Buffer Pool)的最大用量 | 33554432.00 Bytes |
JobManager 堆外直接内存中的缓存数 | JobManager 堆外直接内存(Direct Buffer Pool)中的缓存(Buffer)个数 | 22.00 Items |
JobManager 堆外直接内存使用量 | JobManager 堆外直接内存(Direct Buffer Pool)的用量 | 575767.00 Bytes |
JobManager 堆外直接内存总容量 | JobManager 堆外直接内存(Direct Buffer Pool)的最大用量 | 577814.00 Bytes |
注册的 TaskManager 数 | 当前作业已注册的 TaskManager 数,通常等于所有算子并行度的最大值。如果 TaskManager 个数减少,说明存在 TaskManager 失联,作业可能崩溃并尝试恢复 | 3.00 TaskManagers |
运行中的作业数 | 正在运行中作业数。如果作业正常运行,则值为1。如果作业崩溃,则值为0 | 1.00 Jobs |
可用任务槽数量 | 如果作业正常运行,则可用的任务槽(Task Slot)数为0。如果不为0,则说明作业可能出现短时间的非运行状态 | 0.00 Slots |
任务槽总数 | Oceanus 中一个 TaskManager 只有一个任务槽,因此任务槽总数等于注册的 TaskManager 数 | 3.00 Slots |
JobManager 活动线程数 | 当前作业 JobManager 中活动的线程数,含 Daemon 和非 Daemon 线程 | 77.00 Threads |
TaskManager CPU 使用时长 | 作业中所有 TaskManager CPU 使用时长总和(毫秒) | 2029230.00 ms |
TaskManager 可用的 MemorySegment 个数 | 作业中所有 TaskManager 的可用 MemorySegment 个数之和 | 32890.00 Items |
TaskManager 已分配的 MemorySegment 总数 | 作业中所有 TaskManager 已分配的 MemorySegment 个数总和 | 32931.00 Items |
TaskManager 活动线程数 | 作业中所有 TaskManager 中活动的线程数之和,含 Daemon 和非 Daemon 线程 | 207.00 Threads |
上次 Checkpoint 大小 | 上个快照存储的大小 | 1024字节 |
Checkpoint 耗时 | 上个快照存储所耗时间 | 100ms |
Checkpoint 失败总次数 | 保存快照累计失败次数 | 1次 |
JM CPU Load | JobManager 维度的 JVM 最近 CPU 利用率 | 12% |
JM Heap Memory | JobManager 维度的堆内存使用情况 | 1次 |
JM GC Count | JobManager 维度的 Status.JVM.GarbageCollector.<GarbageCollector>.Count,GC(垃圾回收)次数 | 5次 |
JM GC Time | JobManager 维度的 Status.JVM.GarbageCollector.<GarbageCollector>.Time,GC(垃圾回收)时间 | 64ms |
TaskManager CPU Load | 选中的 TaskManager 维度的 JVM 最近 CPU 利用率 | 70% |
TaskManager Heap Memory | 选中的 TaskManager 维度的堆内存使用情况 | 50字节 |
TaskManager GC Count | 选中的 TaskManager 维度的 Status.JVM.GarbageCollector.<GarbageCollector>.Count,GC(垃圾回收)次数 | 5次 |
TaskManager GC Time | 选中的 TaskManager 维度的 Status.JVM.GarbageCollector.<GarbageCollector>.Time,GC(垃圾回收)时间 | 5ms |
Task OutPoolUsage | 输出队列百分比,达到100%时任务达到完全反压状态 | 64% |
Task OutputQueueLength | 输出队列个数 | 6 |
Task InPoolUsage | 输入队列百分比,达到100%时任务达到完全反压状态 | 64% |
Task InputQueueLength | 输入队列个数 | 6 |
Task CurrentInputWatermark | 当前水位 | 1623814418 |
数据流入耗时(ETL) | 当前作业 Source 拿到数据已经产生的延迟时间 | 10 ms |
作业每秒输入的记录条数(ETL) | 当前作业所有 source 的加和速率 | 342 条/秒 |
批间隔时间(ETL) | 当前作业 Source 处理数据的批间隔,间接反应 source 空闲状态 | 24532223 ms |
source 处理延迟(ETL) | 当前作业 Source 拿到数据并处理的延迟时间 | 1345 ms |
Binglog/lsn 的位点信息(ETL) | 当前作业 mysql binlog 的 pos 点位/pg 的 lsn 号 | 260690147 |
算子计算总耗时(ETL) | 当前作业统计 Sink 与 Source算子之间的平均延迟时间 | 49 ms |
sink 刷新延迟(ETL) | 当前作业 sink 的延迟 flush 时间+异步回调时间 | 30 ms |
作业每秒输出的记录条数(ETL) | 当前作业所有 sink 的加和速率 | 234 条/秒 |
数据源-存量同步(ETL) | 当前作业存量数据的同步进度 | 30% |
数据源-增量同步(ETL) | 针对 mysql 同步延迟指的是当前 souce 处理 binlog 位点和 mysql 实例源最新的 binlog 的最后一次采样的缺口值,针对 postgresql 同步延迟指的是当前 souce 处理 lsn 日志号和 postgresql 实例源最新的 lsn 日志号的最后一次采样缺口值 | 205 |
Kafka - Records_Lag 最大值 | Taskmanager 上报的 kafka-lag-max 最大值(kafka-lag-max:生产者当前偏移量和消费者当前偏移量之间的计算差值) | 100 |
Kafka - Records_Lag 最小值 | Taskmanager 上报的 kafka-lag-max 最小值(kafka-lag-max:生产者当前偏移量和消费者当前偏移量之间的计算差值) | 50 |
Kafka - Records_Lag 均值 | Taskmanager 上报的 kafka-lag-max 均值(kafka-lag-max:生产者当前偏移量和消费者当前偏移量之间的计算差值) | 80 |
Kafka - Records_Lag 求和值 | 各个 Taskmanager 上报的 kafka-lag-max 的求和值(kafka-lag-max:生产者当前偏移量和消费者当前偏移量之间的计算差值) | 500 |
数据在外部系统的滞留时间 (毫秒) | 指标计算公式:数据被 Source 读取的时间(FetchTime)- 数据事件时间(EventTime)。该指标反映了数据在外部系统的滞留情况 | 10 |
数据在外部系统和 Source 中的滞留时间 (毫秒) | 指标计算公式:数据离开 Source 的时间(EmitTime)- 数据事件时间(EventTime)。该指标反映了数据在外部系统和 Source 中的滞留情况 | 20 |
反压指标(%) | 作业所有 SubTask 的反压百分比的最大值 | 30% |
数据倾斜程度 | 指标为每个作业的 SubTask 的数据输入量的离散系数(=标准差/均值)的最大值,小于 10% 属于弱倾斜 | 10% |
最近更新时间:2023-11-07 18:00:39

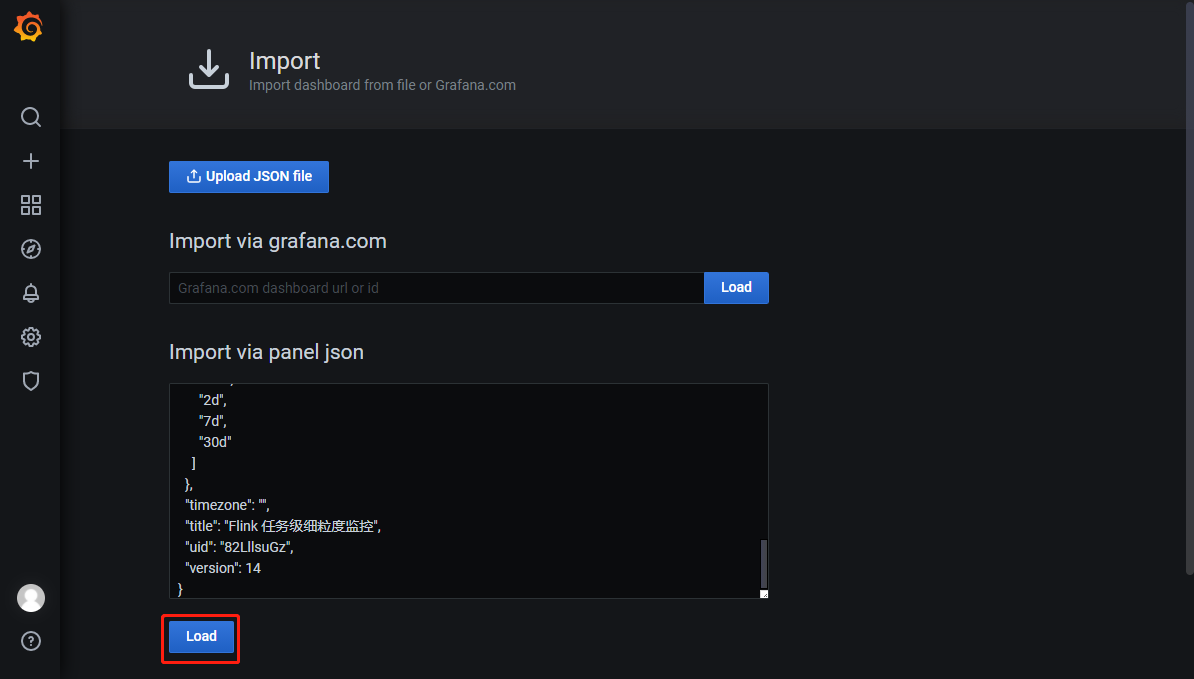
metrics.reporters: promgatewaymetrics.reporter.promgateway.host: ${Prometheus PushGateway 的 IP 地址}metrics.reporter.promgateway.port: ${Prometheus PushGateway 的端口}
metrics.reporter.promgateway.needBasicAuth: truemetrics.reporter.promgateway.password: ${Prometheus 访问密码}
Checkpoint 失败数。
instance_id="$InstanceId" 等。如果需要按条件筛选,请在 { } 中填入具体值,例如 instance_id="cql-abcd0012"。{{ $labels.job_id }},而查询语句的值可以用 {{ $value }} 表示。
最近更新时间:2023-11-07 17:49:03
最近更新时间:2023-11-07 17:27:57
job-running-log/ 。DEBUG , INFO , WARN , ERROR ; 作业配置日志级别之后,作业日志会按照配置的级别输出,如果不支持选择日志级别,可以 提交工单 申请升级。DEBUG , INFO , WARN , ERROR)后点击确定按钮即可完成批量配置,作业日志会按照配置的级别输出,如果不支持选择日志级别,可以 提交工单 申请升级。最近更新时间:2023-11-07 17:54:03
from RUNNING to FAILED 关键字可以搜索到作业崩溃的直接原因,异常栈中的 Caused by 后即为故障信息。java.lang.OutOfMemoryError 关键字,说明很可能出现了 OOM 堆内存溢出。需尝试增加作业的算子并行度(CU)数和优化内存占用,避免内存泄露。exit code OR shutting down JVM OR fatal OR kill OR killing
fatal 关键字declined 表示由于资源未到位(作业并未处于运行中)、个别算子已进入 FINISHED 状态、快照超时、快照文件不完整等原因,造成了快照的失败。Checkpoint was declinedCheckpoint was canceledCheckpoint expiredjob has failedTask has failedFailure to finalize
Timeout expired while fetching topic metadata 表示初始化超时;MySQL 的 Communications link failure 表示连接中断(可能是很长时间没有数据流入,造成客户端超时)。java.util.concurrent.TimeoutExceptiontimeoutfailuretimed outfailed
Exception 关键字代表可能发生了异常。例如,下图某个 Flink 作业的启动日志,它因为异常而没有提交成功。搜索 Exception 关键字,可以从各级异常栈的 Caused by 中看到具体的异常:WARN 和 ERROR 关键字的日志,可能有较多结果,请注意筛选过滤有价值的信息。例如, WARN 和 ERROR 报错是正常的,并不代表有错误出现。WARN org.apache.flink.core.plugin.PluginConfig - The plugins directory [plugins] does not exist.WARN org.apache.flink.shaded.zookeeper3.org.apache.zookeeper.ClientCnxn - SASL configuration failed: javax.security.auth.login.LoginException: No JAAS configuration section named 'Client' was found in specified JAAS configuration file: '/tmp/jaas-00000000.conf'. Will continue connection to Zookeeper server without SASL authentication, if Zookeeper server allows it.ERROR org.apache.flink.shaded.curator4.org.apache.curator.ConnectionState - Authentication failedWARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicableWARN org.apache.flink.kubernetes.utils.KubernetesInitializerUtils - Ship directory /data/workspace/.../shipFiles is not exists. Ignoring it.WARN org.apache.flink.configuration.GlobalConfiguration - Error while trying to split key and value in configuration file /opt/flink-1.11.0/conf/flink-conf.yamlWARN org.apache.flink.shaded.curator4.org.apache.curator.utils.ZKPaths - The version of ZooKeeper being used doesn't support Container nodes. CreateMode.PERSISTENT will be used instead.WARNING: Unable to load JDK7 types (annotations, java.nio.file.Path): no Java7 support added
最近更新时间:2023-11-07 16:39:56
RUNNING 状态变成 重启中 RESTARTING 或 失败 FAILED 等异常状态),则会生成一条“发生作业失败”事件。如果后续作业又进入了 RUNNING 状态,则会生成一条“作业失败已恢复”事件。最近更新时间:2023-11-07 16:43:10
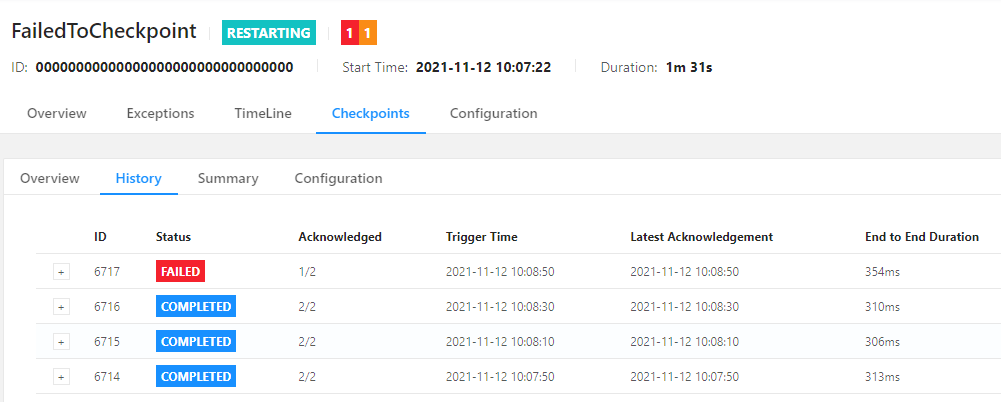
FAILED。COMPLETED。最近更新时间:2023-11-07 16:46:16
RUNNING 状态变为 FAILED、RESTARTING 等异常状态时(后续 Flink JobManager 负责自动恢复作业,耗时约 10s,恢复后运行实例 ID 不变)。restart-strategy.fixed-delay.attempts 参数控制,默认为5,实际生产环境下建议调大),导致 JobManager 和 TaskManager 整体退出时(后续会被系统从最近一次成功的快照点尝试恢复,耗时约2分钟,恢复后运行实例 ID 会增加1)。RUNNING 状态时,会发送 “作业失败已恢复” 事件,代表本次告警结束。from RUNNING to FAILED 关键字前后的报错信息是导致作业失败的直接原因。我们建议结合 JobManager 和 TaskManager 的日志一起分析。最近更新时间:2023-11-07 17:35:05
状态码 | 可能原因 | 解决方案 |
137 | 作业内存占用过大,超出 Pod 配额,导致被 OOMKilled | |
-1 | 兜底策略,表示 Pod 退出但是并未得到退出码,可能是系统错误等 | |
0 | Pod 启动过程中,由于无法在用户绑定的子网中分配 IP(例如 IP 耗尽),导致启动失败退出 | |
1 | Flink 初始化期间发生了异常,导致启动失败 | 通常是基础类冲突或者关键配置文件被覆盖导致的,可在日志中搜索 Could not start cluster entrypoint 关键字附近的异常信息。 |
2 | Flink JobManager 启动期间发生了致命错误 | 日志中搜索 Fatal error occurred in the cluster entrypoint 关键字附近的异常信息。 |
239 | Flink 的执行线程发生了未捕获的致命错误 | 日志中搜索 produced an uncaught exception. Stopping the process 等关键字附近的异常信息。 |
最近更新时间:2023-11-07 16:35:27
状态码 | 可能原因 | 解决方案 |
137 | 作业内存占用过大,超出 Pod 配额,导致被 OOMKilled | 可能是 Source Connector 实现不当,给 JobManager 造成较大内存压力。 |
-1 | 兜底策略,表示 Pod 退出但是并未得到退出码,可能是系统错误等 | |
0 | Pod 启动过程中,由于无法在用户绑定的子网中分配 IP(例如 IP 耗尽),导致启动失败退出 | |
1 | Flink 初始化期间发生了异常,导致启动失败 | 通常是基础类冲突或者关键配置文件被覆盖导致的,可在日志中搜索 Could not start cluster entrypoint 关键字附近的异常信息。 |
2 | Flink JobManager 启动期间发生了致命错误 | 日志中搜索 Fatal error occurred in the cluster entrypoint 关键字附近的异常信息。 |
239 | Flink 的执行线程发生了未捕获的致命错误 | 日志中搜索 produced an uncaught exception. Stopping the process 等关键字附近的异常信息。 |
最近更新时间:2023-11-07 16:33:42
taskmanager.memory.managed.size 的值,也可以起到增加堆内存空间的效果。但请务必在熟悉 Flink 内存分配机制的专家指导下进行调优,否则极有可能造成其他问题。OutOfMemoryError: Java heap space 等关键字,还可以启用 Pod 崩溃事件采集,并设置文中描述的 -XX:+HeapDumpOnOutOfMemoryError 参数,以便在作业发生 OOM(内存不足)崩溃时,及时捕捉到堆内存的现场 Dump 文件以供后续分析。OutOfMemoryError: Java heap space 等关键字,且目前作业暂时正常运行,我们建议对该作业 配置告警,将流计算作业失败事件加入告警规则,以第一时间获取作业崩溃的事件推送。最近更新时间:2023-11-08 10:21:08
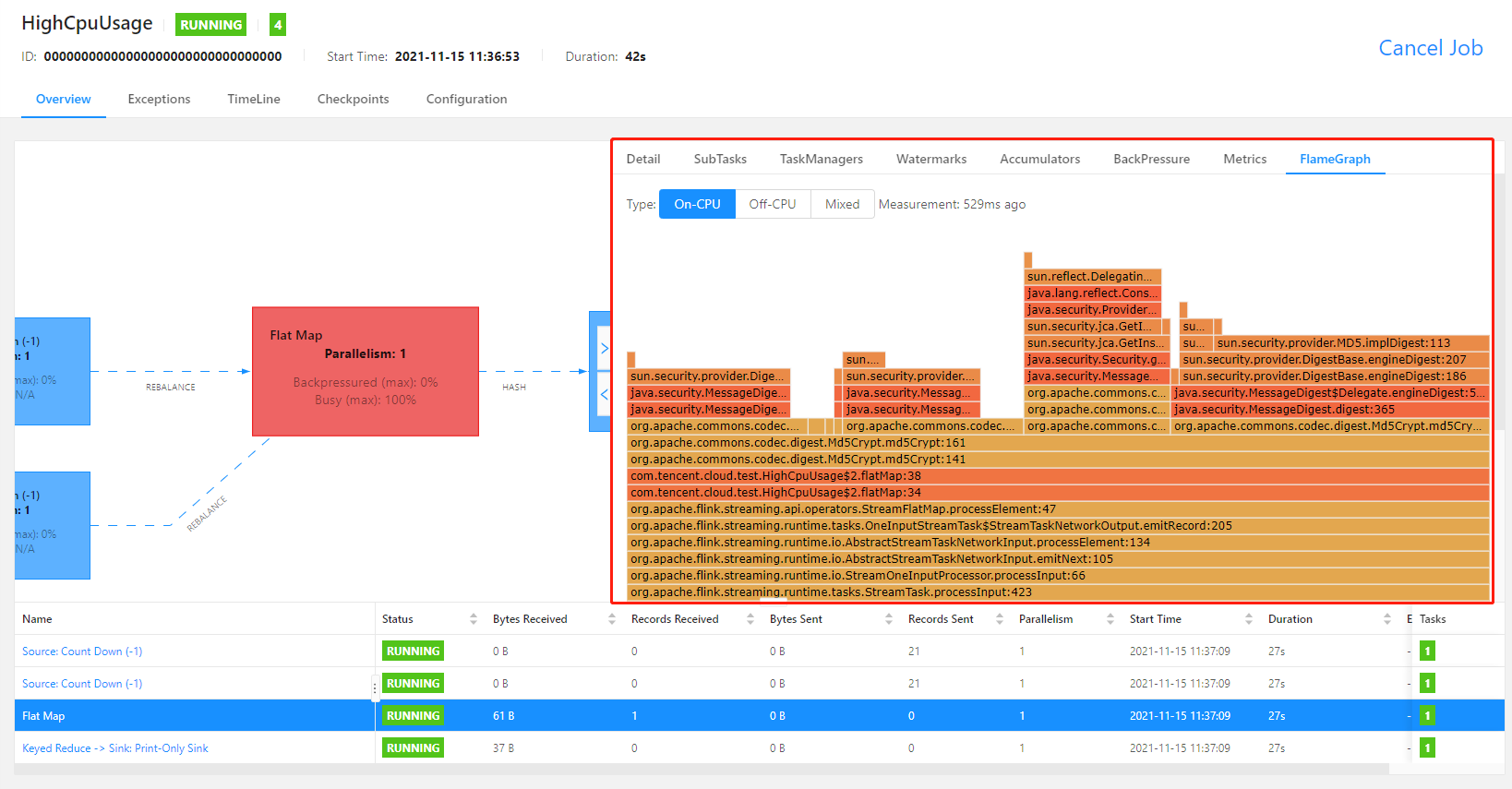
rest.flamegraph.enabled: true 参数,并重新发布作业版本,才可使用火焰图绘制功能),如下图:
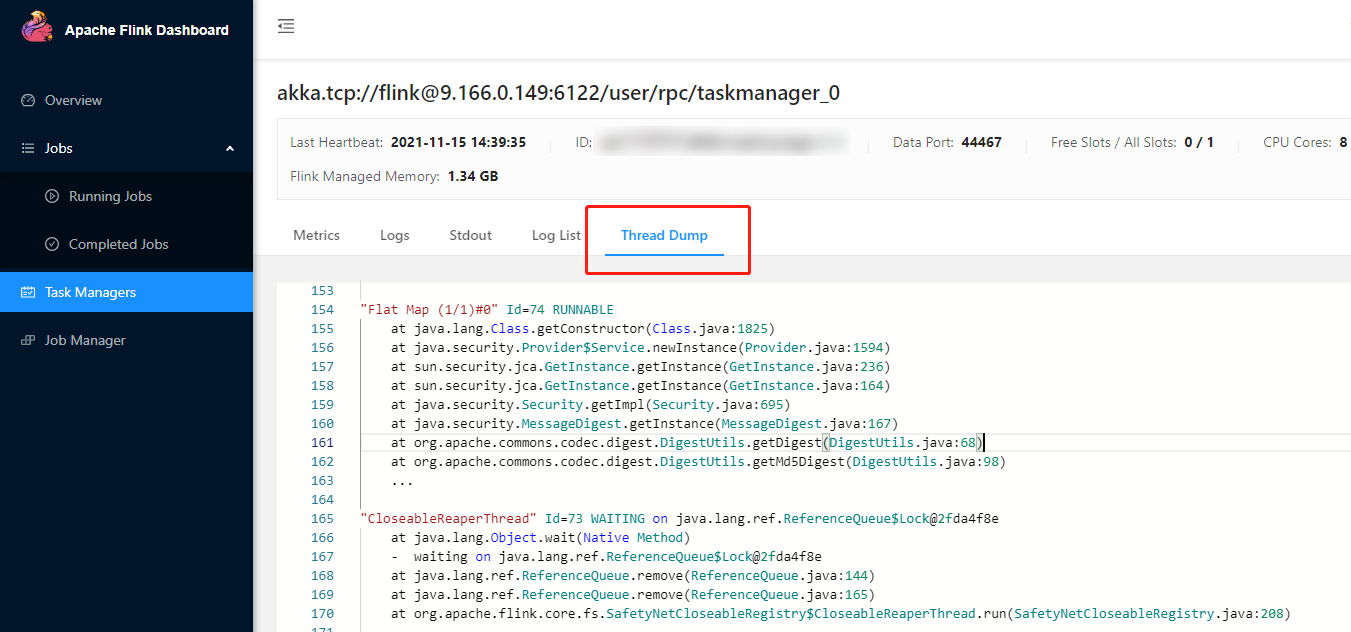
最近更新时间:2023-11-07 16:24:13
rest.flamegraph.enabled: true 参数,并重新发布作业版本,才可使用火焰图绘制功能)。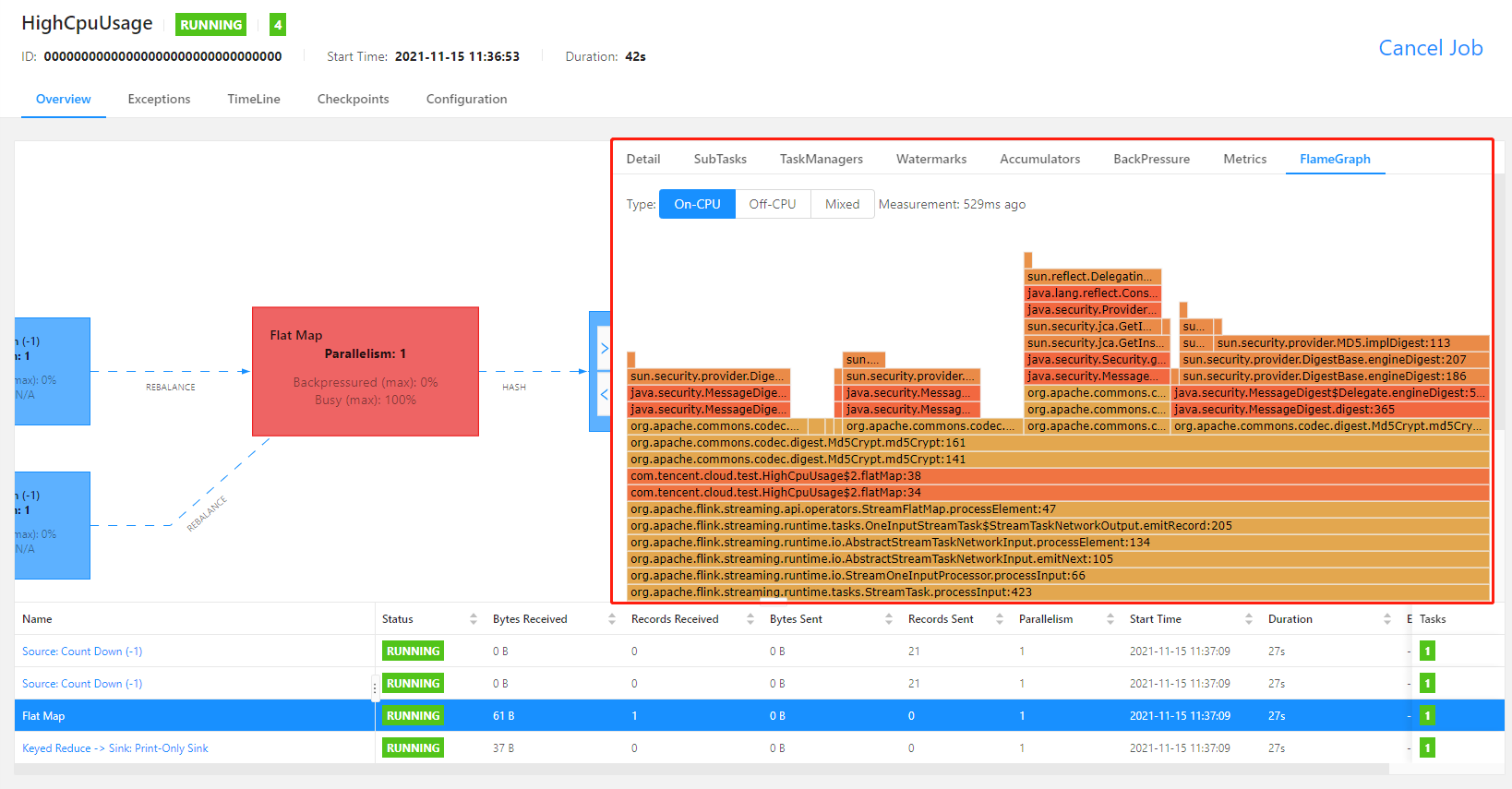
最近更新时间:2023-11-07 15:41:45
最近更新时间:2023-11-07 15:44:22
scan.incremental.snapshot.chunk.size 参数,以避免分片数过多导致 JobManager 堆内存用尽。OutOfMemoryError: Java heap space 等关键字,且目前作业暂时正常运行,我们建议对该作业 配置告警,将流计算作业失败事件加入告警规则,以第一时间获取作业崩溃的事件推送。最近更新时间:2023-11-07 16:30:18
[_dc]和默认数据库[_db]。
在库表引用功能界面中,选择右上角的新建 > 数据库,在弹窗中选择 Catalog,输入库名,然后单击确定。${变量名}:默认值。例如:${job_name}:job_test。最近更新时间:2023-11-07 16:26:08
${变量名称}:默认值_ 。最近更新时间:2023-11-07 16:28:52
Flink 版本 | 说明 |
1.11 | 不支持 |
1.13 | 支持 hive 版本2.2.0、2.3.2、2.3.5、3.1.1 |
1.14 | 不支持 |
hive --service metastore:开启 Hive Metastore 服务。ps -ef|grep metastore:查询 Hive Metastore 服务是否已开启。_dc,单击新建 Hive Catalog。
上传4个配置文件 hive-site.xml ,hdfs-site.xml ,hivemetastore-site.xml ,hiveserver2-site.xml 配置文件下载,其中 hive-site.xml 中需要添加 urls 的地址。catalog_name.database_name。CREATE DATABASE IF NOT EXISTS `hiveCatalogName`.`databaseName`;
catalog_name.database_name.table_name。CREATE TABLE IF NOT EXISTS `hiveCatalogName`.`databaseName`.`tableName` (user_id INT,item_id INT,category_id INT,-- ts AS localtimestamp,-- WATERMARK FOR ts AS ts,behavior VARCHAR) WITH ('connector' = 'datagen','rows-per-second' = '1', -- 每秒产生的数据条数'fields.user_id.kind' = 'sequence', -- 有界序列(结束后自动停止输出)'fields.user_id.start' = '1', -- 序列的起始值'fields.user_id.end' = '10000', -- 序列的终止值'fields.item_id.kind' = 'random', -- 无界的随机数'fields.item_id.min' = '1', -- 随机数的最小值'fields.item_id.max' = '1000', -- 随机数的最大值'fields.category_id.kind' = 'random', -- 无界的随机数'fields.category_id.min' = '1', -- 随机数的最小值'fields.category_id.max' = '1000', -- 随机数的最大值'fields.behavior.length' = '5' -- 随机字符串的长度);
INSERT INTO`hiveCatalogName`.`databaseName`.`sink_tableName`SELECT*FROM`hiveCatalogName`.`databaseName`.`source_tableName`;
useradd flinkgroupadd supergroupusermod -a -G supergroup flinkhdfs dfsadmin -refreshUserToGroupsMappings
<property><name>hive.metastore.authorization.storage.checks</name><value>true</value><description>Should the metastore do authorization checks againstthe underlying storage for operations like drop-partition (disallowthe drop-partition if the user in question doesn't have permissionsto delete the corresponding directory on the storage).</description><property>
最近更新时间:2023-11-08 10:17:15
最近更新时间:2023-11-07 15:50:49
最近更新时间:2023-11-07 15:54:02
最近更新时间:2023-11-07 15:51:40
字段 | 含义 |
集群名称 | 自定义集群名称 |
集群 ID | 系统自动生成的集群唯一识别序列号 |
集群状态 | 集群目前的运行状态 |
集群描述 | 用户自定义的帮助识别此集群的描述 |
计算资源(CU) | 集群空闲的 CU/集群总共拥有的 CU |
地域/可用区 | 此集群所在的地域/可用区 |
VPC | 独享集群关联的 VPC 和子网,流计算 Oceanus 通过弹性网卡将流计算独享集群与用户的 VPC 网络打通,从而可以访问该网络环境下的资源和服务 |
COS 存储 | 集群创建时绑定的 COS 存储桶 |
日志 | 集群创建时绑定的 CLS 日志集和日志主题 |
标签 | 集群被打上的标签 |
计费模式 | 目前支持按量付费和包年包月 |
Flink 版本 | 集群部署的 Flink 版本号 |
创建时间 | 集群创建的时间 |
DNS | 集群的DNS配置 |
Flink UI 访问策略 | 可以设置 Flink UI 的访问策略,不设置可访问 IP 白名单时,默认所有公网 IP 均可访问 |
最近更新时间:2023-11-07 15:46:32
最近更新时间:2023-11-07 15:48:38
最近更新时间:2023-11-07 15:47:38
最近更新时间:2023-11-07 15:49:59
最近更新时间:2023-11-07 15:44:58
kafka.example.com 来访问 IP 为172.17.0.2的 CKafka 实例。172.17.0.2 kafka.example.com172.17.0.3 mysql.example.com
172.17.0.253 和 172.17.0.254,您的作业中对任何 *.example.com 形式的域名访问,都会通过您的 DNS 服务器解析。您可以在 DNS 服务器中配置 172.17.0.2 kafka.example.com 的映射关系,那么 kafka.example.com 就能解析到地址 172.17.0.2。example.com {forward . 172.17.0.253 172.17.0.254}
最近更新时间:2023-11-07 15:45:22
最近更新时间:2023-11-08 10:18:19
最近更新时间:2023-11-08 10:28:48
QcloudCamRoleFullAccess 权限的子用户、拥有 QcloudCamSubaccountsAuthorizeRoleFullAccess 权限的子用户可以进行自动授权操作。cam:PassRole 权限。{"version": "2.0","statement": [{"effect": "allow","action": "cam:PassRole","resource": "qcs::cam::uin/${OwnerUin}:roleName/Oceanus_QCSRole"}]}
最近更新时间:2023-11-08 10:16:26
功能分类 | 超级管理员 | 空间管理员 | 开发者 | 预览者 |
新建/销毁集群 | ✔️ | ❌ | ❌ | ❌ |
修改集群信息 | ✔️ | ❌ | ❌ | ❌ |
续费/变配 | ✔️ | ❌ | ❌ | ❌ |
查看集群 | ✔️ | ✔️ | ✔️ | ✔️ |
增加/删除空间 | ✔️ | ❌ | ❌ | ❌ |
修改空间属性 | ✔️ | ❌ | ❌ | ❌ |
集群和空间关联/解除关联 | ✔️ | ❌ | ❌ | ❌ |
增加/删除空间成员 | ✔️ | ✔️ | ❌ | ❌ |
修改空间成员角色 | ✔️ | ✔️ | ❌ | ❌ |
编辑超级管理员 | ✔️ | ❌ | ❌ | ❌ |
新建/删除作业 | ✔️ | ✔️ | ✔️ | ❌ |
运行/停止作业 | ✔️ | ✔️ | ✔️ | ❌ |
开发/调试作业 | ✔️ | ✔️ | ✔️ | ❌ |
监控告警 | ✔️ | ✔️ | ✔️ | ❌ |
查看作业 | ✔️ | ✔️ | ✔️ | ✔️ |
创建/删除依赖资源 | ✔️ | ✔️ | ✔️ | ❌ |
编辑依赖资源 | ✔️ | ✔️ | ✔️ | ❌ |
查看依赖资源 | ✔️ | ✔️ | ✔️ | ✔️ |
创建/删除元数据库 | ✔️ | ✔️ | ✔️ | ❌ |
创建/删除元数据表 | ✔️ | ✔️ | ✔️ | ❌ |
查看元数据 | ✔️ | ✔️ | ✔️ | ✔️ |
操作目录 | ✔️ | ✔️ | ✔️ | ❌ |