MLflow is an open-source platform designed to help machine learning practitioners and teams manage the complexities of the machine learning process. MLflow focuses on the entire lifecycle of machine learning projects, ensuring that each stage is manageable, traceable, and reproducible. This article provides a simple introduction on using MLflow on EMR with an example. For detailed documentation, see MLflow Official Documentation.
Prerequisites
A machine learning cluster of EMR on TKE has been created and the MLflow service has been selected. For details, see Creating a Cluster.
Access the MLflow WebUI
1. You can enable public network access on the Edit Deployment page of the MLflow service when purchasing a cluster, or enter the cluster console Cluster Service after purchasing the cluster. Select MLflow service, and click Enable Network Access in Role Management.
2. After enabling network access, click View WebUI in the upper right corner to open the MLflow WebUI (the security group needs to enable port 5000).
Usage Example
MLflow Tracking is one of the main service components of MLflow. We take notebook as an example to demonstrate how to use MLflow Tracking. For the examples on code, see MLflow Official Website Quick Start.
Operation steps can be divided into preparing the dataset, training the model and recording the model and its metadata into MLflow, loading the model as a Python function, and using the loaded model to predict new data.
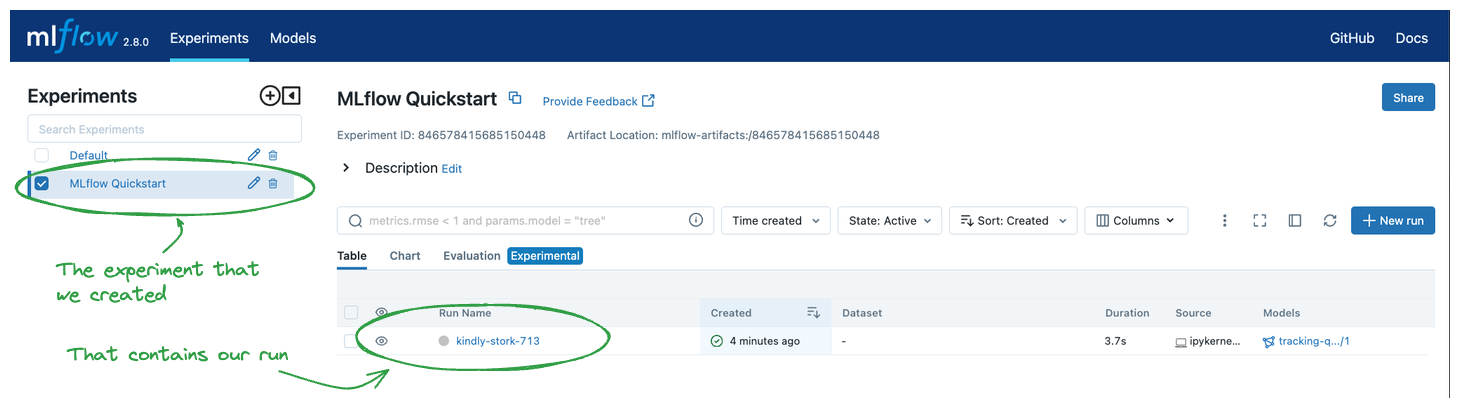
After executing the above, you can view the execution results in the MLflow UI, as shown below. Click Run Task Name to enter Details Page for more information.