服务端接入 AI 转录与翻译
下载
聚焦模式
字号
本文将介绍通过服务端配置接入 AI 转录和翻译功能。
说明:
功能说明
通过 AI 转录与翻译功能,您可以将房间内每位用户的音频流实时转换为文本,并支持多语言翻译。
转录功能:由语音识别引擎(ASR)将语音转写为文本。系统支持多语种、热词权重配置、VAD 检测以及实时流式识别。
翻译功能:可在语音转写的基础上开启翻译功能。系统会将转写后的文本通过 LLM 翻译引擎进行翻译处理,并同时输出原文转写内容以及翻译结果,该功能为可选项。
注意:
单个应用默认支持 100 路任务并发,所有任务的 ASR 并发总数上限为 200 路。如需更高并发数,请联系技术支持进行评估。接口超时时间为 6 秒。接口 QPS 限制 20,如需提高请联系 技术支持 进行评估。
场景说明
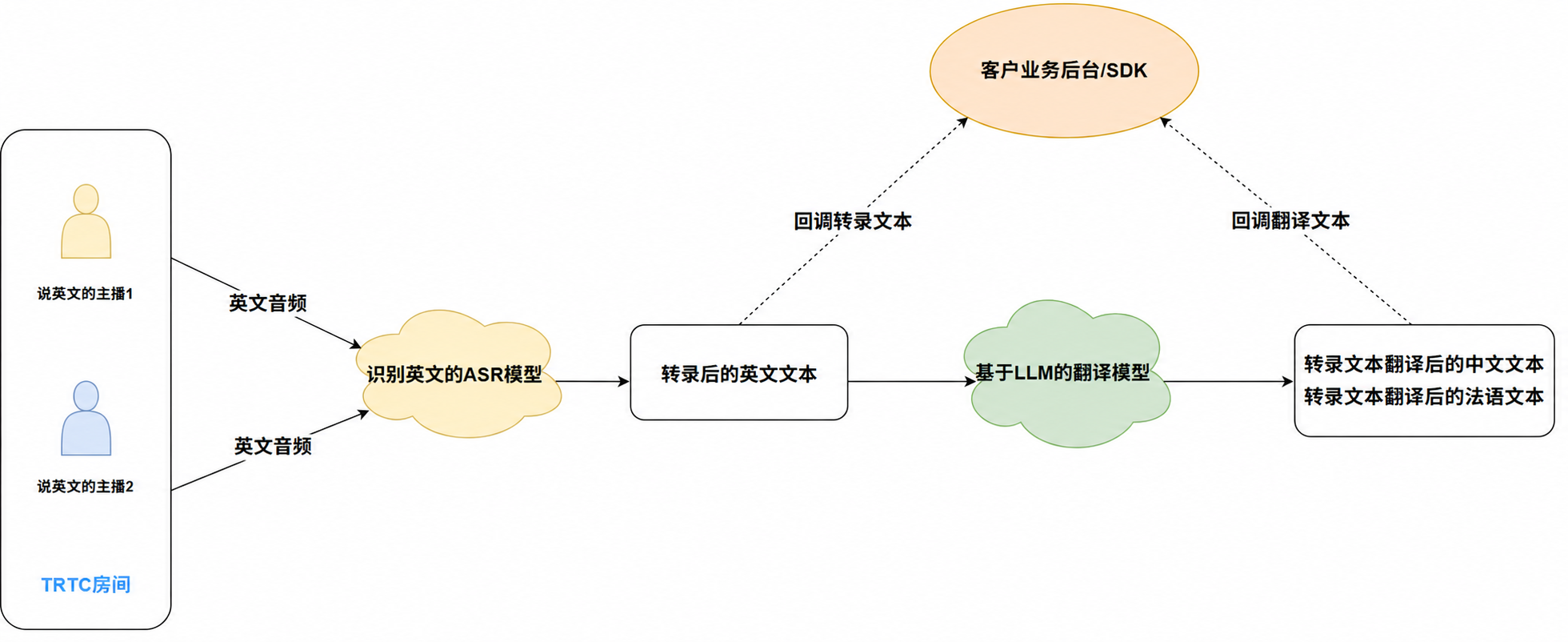
房间内的所有用户均使用同一种语言
在如图所示的 TRTC 房间中,有多位主播使用英文进行交流。您可以发起任务订阅所有用户的英文音频流,并选择英文 ASR 模型将音频实时转录为英文文本。转录结果将通过回调方式返回。同时,您可以设置翻译目标语言,翻译模型会将转录后的英文文本翻译成指定语言,并通过回调发送翻译结果。
说明:
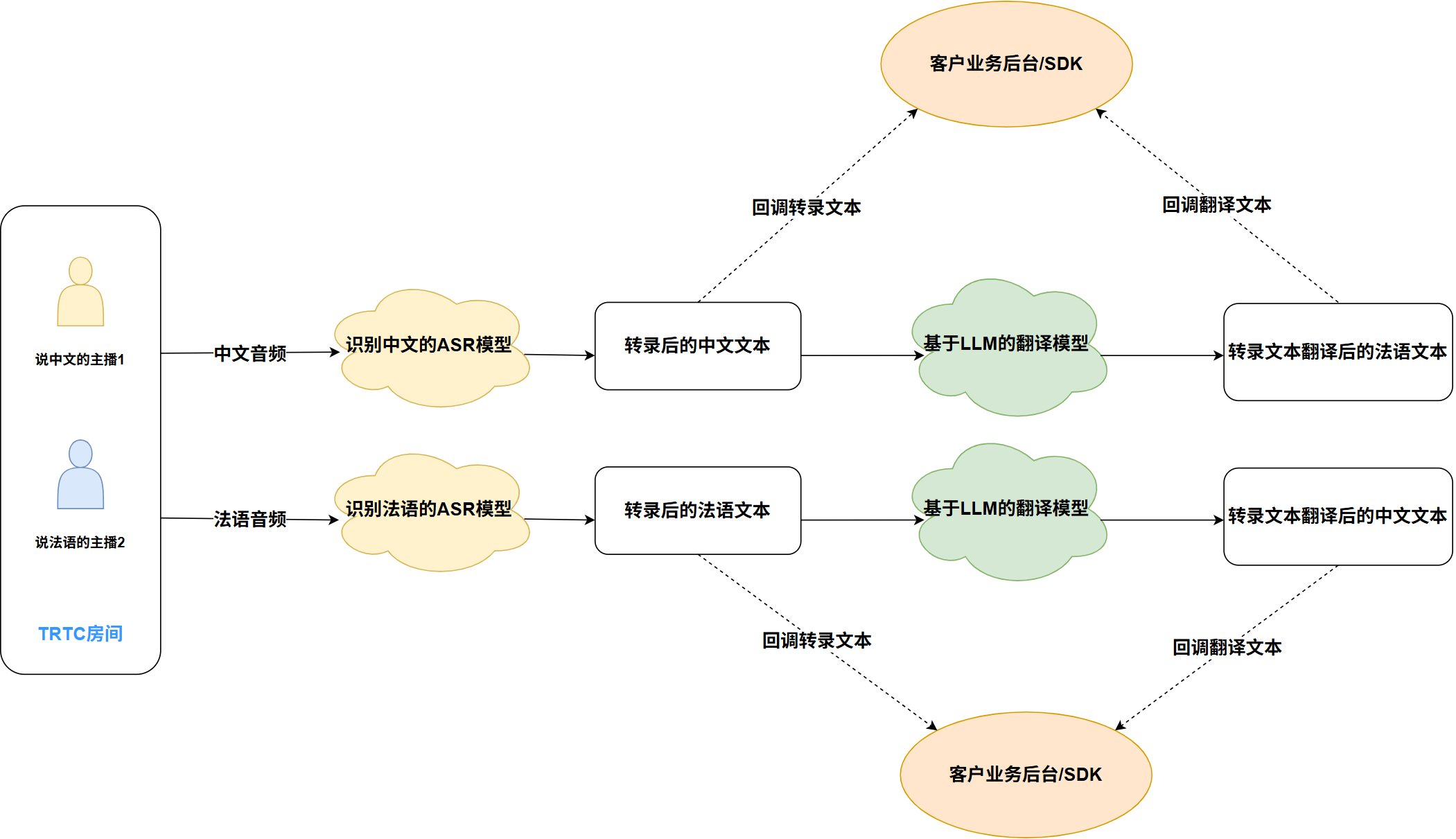
房间内的用户使用多种语言
在如图所示的 TRTC 房间中,两位主播分别使用中文和法语进行交流。由于单个任务的 ASR 模型仅支持特定语言的识别,需要发起以下两项任务:
1. 任务一:订阅主播 1 的中文音频,选择中文 ASR 模型进行实时转录,生成中文文本并通过回调返回。可设置翻译目标语言为法语,系统将自动转录文本翻译为法语,翻译结果同样通过回调返回。
2. 任务二:订阅主播 2 的法语音频,选择法语 ASR 模型进行实时转录,生成法语文本并通过回调返回。可设置翻译目标语言为中文,系统将自动转录文本翻译为中文,翻译结果同样通过回调返回。
通过以上两项任务,主播 1 和主播 2 即可实现实时的跨语言交流。
接入说明
前提条件
步骤1:集成 TRTC SDK
步骤2:RESTful API 发起任务
通过您的服务器调用 REST API (CreateCloudTranscription)可以启动转录任务,请重点关注任务 ID(TaskId)参数;这个参数是本次任务的唯一标识,您需要保存这个任务 ID 作为后续针对这个任务接口操作的输入参数。任务具体发起步骤如下:
1. 设置基本参数
您需要指定发起转录翻译任务的基本信息,例如您的应用 ID(sdkappid)、房间信息(RoomId)、房间类型(RoomIdType)。这些参数均为必填的。
2. 设置进房订阅参数
使用 AI 转录/翻译服务时,将会有机器人作为虚拟观众加入房间,订阅需要识别的音频流。您需要通过 TranscriptionParams 指定进房机器人的参数和转录订阅的用户参数。进房机器人的参数包括 ID(UserId)、签名(UserSig)、任务空闲等待时间(MaxIdleTime)。您可以通过白名单(SubscribeUids)指定需要进行转录翻译任务的主播,通过黑名单(UnSubscribeList)指定不需要进行转录翻译任务的主播,通过
SendCustomMode 参数指定接收转录和翻译文本的方式。3. 配置 ASR 参数
说明:
4. 开启翻译(可选)
翻译目标语言代码 | 对应语种 |
"zh" | 中文 |
"en" | 英语 |
"es" | 西班牙语 |
"pt" | 葡萄牙语 |
"fr" | 法语 |
"de" | 德语 |
"ru" | 俄语 |
"ar" | 阿拉伯语 |
"ja" | 日语 |
"ko" | 韩语 |
"vi" | 越南语 |
"ms" | 马来语 |
"id" | 印度尼西亚语 |
"it" | 意大利语 |
"th" | 泰语 |
注意:
翻译配置不是必填项,若您只需要语音转文本功能,则无需填写翻译参数,不影响 AI 转录整体功能使用。
实时翻译功能输入源语种和翻译后输出语种目前支持15种语言:中文、英语、西班牙语、葡萄牙语、法语、德语、俄语、阿拉伯语、日语、韩语、越南语、马来语、印度尼西亚语、意大利语、泰语。若前置 ASR 转录语种不在上述范围,翻译功能无法开启。如需其他语种支持可以联系 技术支持。
由于受不同语境或语种差异的影响,AI 翻译的译文内容适用于辅助参考,不应作为唯一专业意见或结论。
步骤3:接收转录翻译的结果回调
方式一:通过服务端回调接收
方式二:通过客户端 SDK 接收回调
您可以参考以下代码,从
TranscriberStore 的响应式数据中监听回调并刷新 UI。请在您的
build.gradle 中添加 依赖,然后执行 Gradle Sync。implementation 'io.trtc.uikit:atomicx-core:4.0.0.110'implementation "com.tencent.liteav:LiteAVSDK_Professional:13.1.0.19861"implementation "com.tencent.imsdk:imsdk-plus:8.7.7201"
然后按以下代码监听消息列表的回调,更新到相应 UI 上,messages 是
TranscriberMessage 的列表。// 假如以 RecyclerView 显示消息列表,则通过 submitList 发送消息列表即可。AITranscriberStore.shared.transcriberState.realtimeMessageList.collect { messages ->adapter.submitList(messages.toList())}
TranscriberMessage 参数说明:参数名 | 类型 | 描述 |
segmentId | String | 用户的每句话都对应一个唯一的 segmentId。 |
speakerUserId | String | 说话用户的 ID。 |
speakerUserName | String | 说话用户的昵称。 |
sourceText | String | 用户的语音转文本。 |
translationTexts | Map<TranslationLanguage, String> | 用户语音文本对应的翻译文本,可翻译成多种语言。 |
timestamp | Long | 当前句子的时间戳。 |
isCompleted | Boolean | 当前句子是否已经完成。 |
请在您的 Podfile 文件中添加 pod 'AtomicXCore' 依赖,然后执行
pod install。target 'xxxx' dopod 'AtomicXCore'end
然后按以下代码监听消息列表的回调,更新到相应 UI 上,
messages 是 TranscriberMessage 的列表。// 假如以 UITableView 显示消息列表,更新消息后,reloadData 即可。AITranscriberStore.shared.state.subscribe(StatePublisherSelector(keyPath: \\.realtimeMessageList)).receive(on: RunLoop.main).sink { [weak self] in self?.updateMessages($0) }.store(in: &cancellables)
TranscriberMessage 参数说明参数名 | 类型 | 描述 |
segmentId | String | 用户的每句话都对应一个唯一的 segmentId。 |
speakerUserId | String | 说话用户的 ID。 |
speakerUserName | String | 说话用户的昵称。 |
sourceText | String | 用户的语音转文本。 |
translationTexts | [TranslationLanguage: String] | 用户语音文本对应的翻译文本,可翻译成多种语言。 |
timestamp | Int64 | 当前句子的时间戳。 |
isCompleted | Bool | 当前句子是否已经完成。 |
实践教程
转录任务创建与错误处理实践教程
为了保障 AI 转录和翻译的高可用性,在集成 RESTful API 的同时请关注以下几点。
调用
CreateCloudTranscription 请求后,请关注 HTTP response,如果请求失败,那么需要根据具体的状态码采取相应的重试策略。错误码是由“一级错误码”和“二级错误码”组合而成,例如:InvalidParameter.SdkAppId。具体情况说明可参考下表:返回错误码 | 问题说明 | 解决措施 |
InvalidParameter.xxxxx | 输入的参数有误。 | 请根据具体提示检查参数填写。 |
InternalError.xxxxx | 遇到服务端错误。 | 可以使用相同的参数重试多次,直到返回正常,拿到 taskid 为止。 建议使用退避重试策略,如第一次3s 重试,第二次6s 重试,第三次12s 重试,以此类推。 |
FailedOperation.RestrictedConcurrency | 并发转录任务数超过了后台预留的资源(默认是 100路)。 |
调用
CreateCloudTranscription 接口时,指定的 UserId/UserSig 是转录作为单独的机器人用户加入房间的 ID,请不要和 TRTC 房间内的其他用户重复。同时,TRTC 客户端加入的房间类型必须和转录接口指定的房间类型保持一致,例如 SDK 创建房间用的是字符串房间号,那么转录任务的房间类型也需要相应设置成字符串房间号。转录状态查询,您可以通过以下几种方式来得到转录相应的任务信息:
成功发起
CreateCloudTranscription 任务后 15s 左右,调用 DescribeCloudTranscription 接口查询转录任务对应的信息,如果查询到状态为 Idle 说明转录机器人没有拉到上行的音频流,请检查房间内是否有主播上行。转录的任务信息会通过回调发送给您。
API 请求频率限制实践教程
腾讯云 API 服务对每个用户的请求频率设置了上限,以保障系统稳定性和资源公平分配。当用户请求频率超过预设阈值时,系统会返回频率限制错误。默认转录接口的 QPS 为 20次/秒。可联系 技术支持 来申请提升限频。通常情况下,QPS 的设置值与在线报备的最高并发的比值是 1:20,例如 2000 路并发在线的转录任务,可以提升 QPS 到 100,实际需要请根据业务实现方式进行合理评估。
如遇到限频错误,短期内可以按照以下方法尝试快速调整:
降低请求频率至限制范围内。
业务实现请求队列。
添加适当的请求间隔时间。
长期方案可以按照以下方法进行调整:
实现指数退避重试机制,如第一次 3s 重试,第二次 6s 重试,第三次 12s 重试,以此类推直到重试成功。
优化业务逻辑,转录提前进房等待,减少并发 API 调用。
文档反馈