プロダクト概要
Download
フォーカスモード
フォントサイズ
テンセントクラウドデータレイクコンピュート DLC(Data Lake Compute、DLC)は、敏捷で効率的なデータレイク分析とコンピューティングサービスを提供します。このサービスはサーバーレスアーキテクチャ(Serverless)で設計されており、ユーザーは基盤となるアーキテクチャやコンピューティングリソースのメンテナンスを気にする必要がなく、標準SQLを使用してオブジェクトストレージサービス(COS)やその他のクラウドデータ施設の連携分析計算を完了できます。このサービスを利用することで、ユーザーは従来のデータ階層モデリングを行う必要がなく、大量のデータ分析の準備時間を大幅に短縮し、企業のデータ敏捷性を効果的に向上させます。
データレイクコンピューティング DLC は、SaaS に類似したサービス設計により、クラウドネイティブなエンタープライズ向け敏捷でインテリジェントなデータレイクソリューションを提供し、以下の特徴を備えています:
テンセントクラウドのビッグデータコア技術の強化能力を基盤として、企業に安定した、安全で高性能なコンピューティングリソースを提供します。
標準SQL構文を使用して、データ処理やマルチソースデータの連携計算などのデータ作業を完了でき、ユーザーのデータ分析サービスの構築コストと使用コストを効果的に削減し、企業のデータ敏捷性を向上させます。
ストレージとコンピューティングの分離および分単位の弾性的スケーリング能力に基づき、企業により低いコストモデルと正確なコスト管理能力を提供します。
SaaS化されたすぐに使える体験を提供し、基盤アーキテクチャやコンピューティングリソースのメンテナンスを気にする必要がなく、企業のトレーニングや使用のハードルをさらに低くします。
製品機能
敏捷リアルタイムデータレイク分析
DLCは、ストレージとコンピューティングを分離した大規模データ分析アーキテクチャを採用し、ビッグデータコンポーネントのコンテナ化に基づいて迅速かつ柔軟なデプロイを実現し、クラウドネイティブオブジェクトストレージ方式で無限の拡張を可能にします。DLCの先進的なクラウドネイティブエラスティックモデルを組み合わせることで、ビジネスの実際の使用曲線に完全に適合し、真にコストを削減します。DLCは、低コストで高弾力性のクラウドネイティブデータレイクソリューションにより、企業が統一されたデータ資産を構築し、性能優位性を最大限に発揮させ、ビジネスアプリケーションの敏捷なイノベーションを可能にします。
企業向けアジャイルデータプラットフォーム
データレイクコンピューティング DLC は、新しいデータアーキテクチャとして、軽量で敏捷、使いやすく、低コストの閉ループビッグデータ分析能力を提供し、ユーザーはデータレイクが提供する統一されたメタデータ管理ビューを活用して、データサイロを解消できます。同時に、クラウド上の豊富なビッグデータ製品の利点を組み合わせることで、さまざまなデータのリアルタイム分析やオフライン分析シナリオに対応し、企業のあらゆる問題を包括的に解決します。データの迅速で容易な流動性により、異なるクラウド製品の能力と利点を有機的に組み合わせることができ、DLC は企業にとって最適なデータ中台とデータ起動の場として機能します。
クロスソースデータレイク連邦分析
DLCは、お客様がデータベースシナリオからビッグデータシナリオへシームレスにアップグレードすることを支援し、オブジェクトストレージ、クラウドデータベース、その他のデータサービスなど、多様なソースからの異種データに対する連合クエリ分析をサポートします。ユーザーは統一されたデータビューを通じて、標準SQLを使用して迅速にマルチソースデータ連合分析を実現し、データサイロを解消してデータの価値を引き出すことができます。
豊富なマルチソースデータサイエンスサポート
データレイクはAIシナリオにおけるビッグデータ基盤であり、古典的な機械学習シナリオや深層学習シナリオでユーザーにサービスを提供します。DLCは様々なAI機能とプラットフォームを組み合わせ、迅速に多様な機械学習機能をサポートし、様々なインテリジェントデータレイク分析シナリオで総合的なソリューションを提供します。DLCは複数の業界データをユーザーに無料で開放し、データ取得やクリーニングなしで直接データ分析段階に進むことができます。本製品は強力なBI機能を提供し、ユーザーが予測分析を通じて迅速にデータインサイトを実現することを支援します。
製品アーキテクチャ
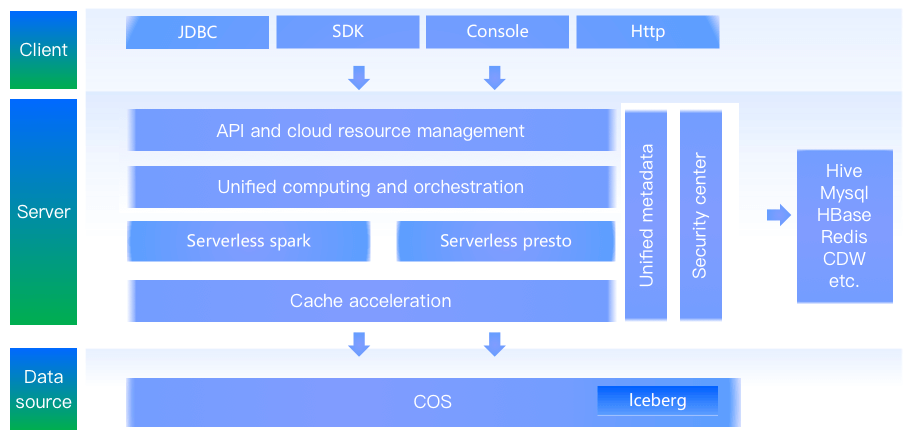
JDBC、SDKモードの開発をサポートし、同時にビジュアルインタラクティブコンソールを提供し、様々な使用シナリオに対応します。
複数のデータソースをサポートし、統一されたメタデータ管理とデータ列レベルのセキュリティ管理を提供し、データの一貫性とセキュリティを保証します。
SparkとPrestoの2つのエンジンを同時にサポートし、複数のエンジンSQL構文を統一します。
クエリキャッシュの高速化により、データのクエリ分析をより迅速かつ効率的に完了できます。
COSおよびIcebergに基づくデータストレージにより、データのACIDトランザクション性を保証します。
フィードバック