クロスソース分析 EMR Hive データ
Download
フォーカスモード
フォントサイズ
データレイクコンピューティング DLC は、EMR Hive のデータソースを設定してクロスソース連合分析をサポートします。
説明:
標準エンジン Presto はこの機能を暫定的にサポートしていません。SuperSQL タイプのエンジンおよび標準エンジン Spark を使用して分析できます。
SuperSQL タイプエンジンおよび Presto エンジンは提供を終了し、既存ユーザーのみが利用できます。
ご利用前の準備
EMR Hive のアドレスを取得します。
データディレクトリ作成権限を持つアカウントを使用してください。詳細な権限については、DLC権限概要を参照してください。
EMR Hive データソースを作成します
1. データレイクコンピューティング DLC コンソールにログインし、サービス地域を選択します。
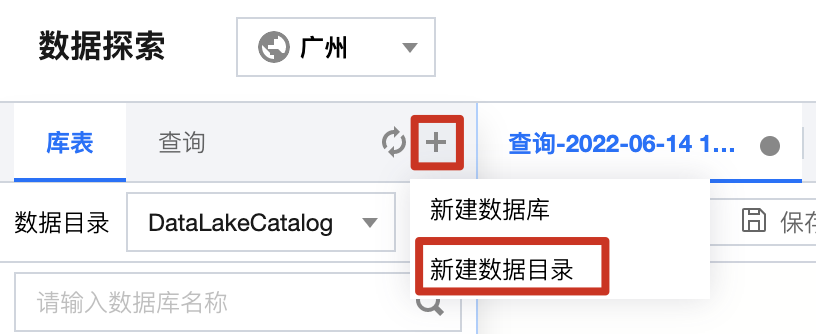
2. 左側のナビゲーションバーからデータ探索に入り、テーブルバーの+ボタンをクリックして、新しいデータカタログを作成を選択します。
3. データカタログ設定に入り、接続タイプを EMR Hive(HDFS)に選択し、接続名は任意に命名します。EMR の対応するインスタンスを選択すると、VPC 情報、Hive アクセスアドレス、クラスタ名、ノードはインスタンス選択後にデフォルトで入力されます。EMR Hive がサポートする Hive のバージョン:2.3.5、2.3.7、3.1.1、3.1.2。
注意:
EMR Hive インスタンスの関連権限が必要です。権限を保有している場合のみ選択できます。
4. 次へをクリックし、ネットワーク設定に入ります。選択したデータエンジンのみがこのデータカタログのデータを読み取ることができ、SparkSQL および Presto の専用データエンジンを選択することがサポートされています。対応するエンジンがない場合は、データエンジンページに移動してデータエンジンを作成してください。購入プロセスについては、専用データエンジンの購入を参照してください。
注意:
選択したデータエンジンのネットワークセグメントは、EMRインスタンスのネットワークセグメントと同じに設定できません。同じに設定すると、ネットワーク競合が発生し、データクエリ分析が行えなくなります。
5. 確認ボタンをクリックすると、データカタログの作成が完了します。
EMR Hive データをクエリします
データカタログの作成が完了したら、データ探索ページのデータカタログメニューでデータカタログを切り替えることができます。
データカタログ作成時にバインドしたデータエンジンを選択すると、実行ボタンをクリックしてクエリ結果を取得できます。
注意:
バインドされたデータエンジンのみがこのデータカタログをクエリでき、他のデータエンジンではクエリできません。バインドするエンジンを変更する必要がある場合は、データカタログ管理の設定ボタンをクリックして編集・修正を行ってください。
フィードバック