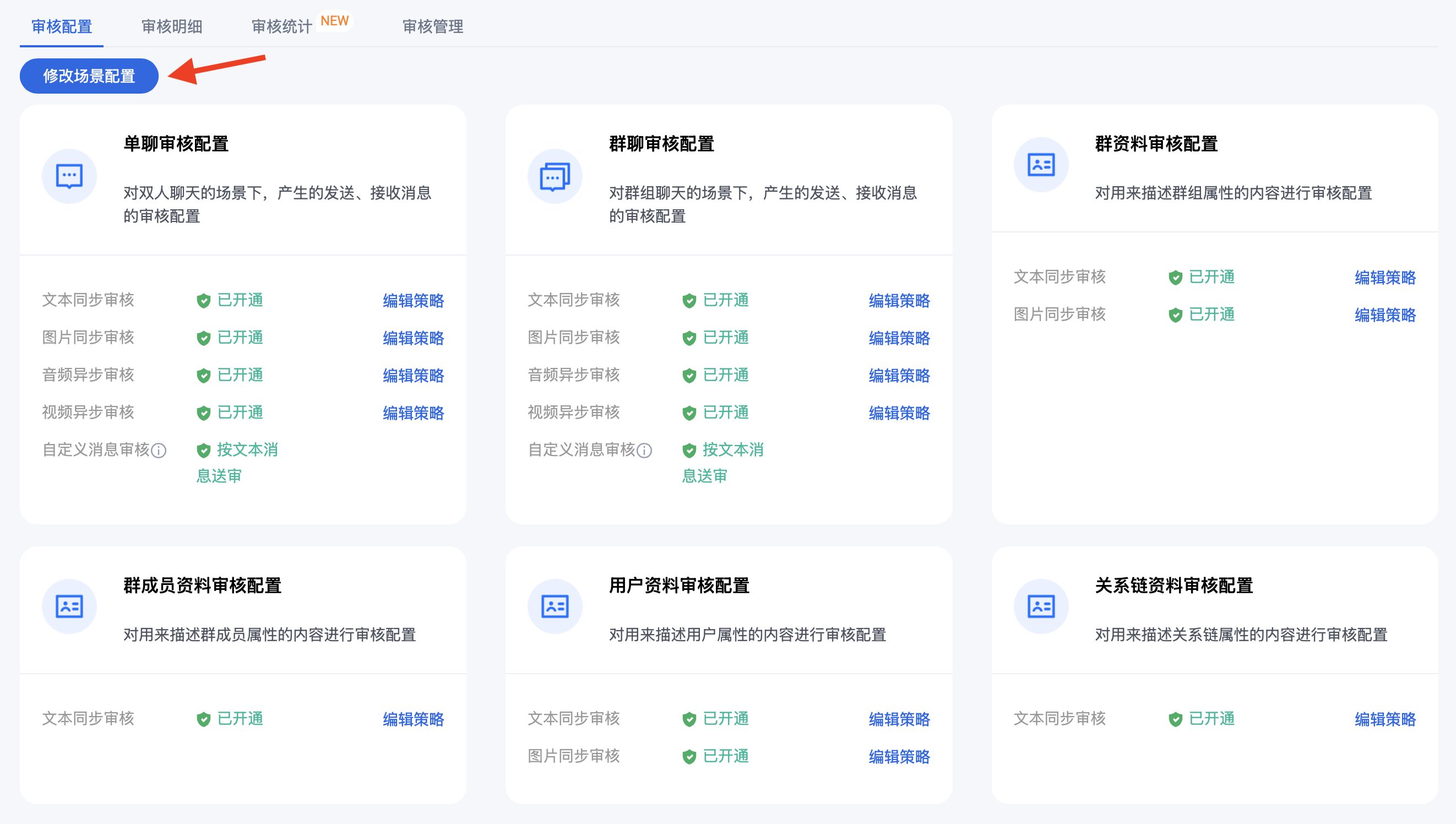
配置内容理解场景和策略
Download
聚焦模式
字号
注意:
当前功能仅支持白名单用户使用,需开通白名单权限后方可访问。
通用场景及策略配置
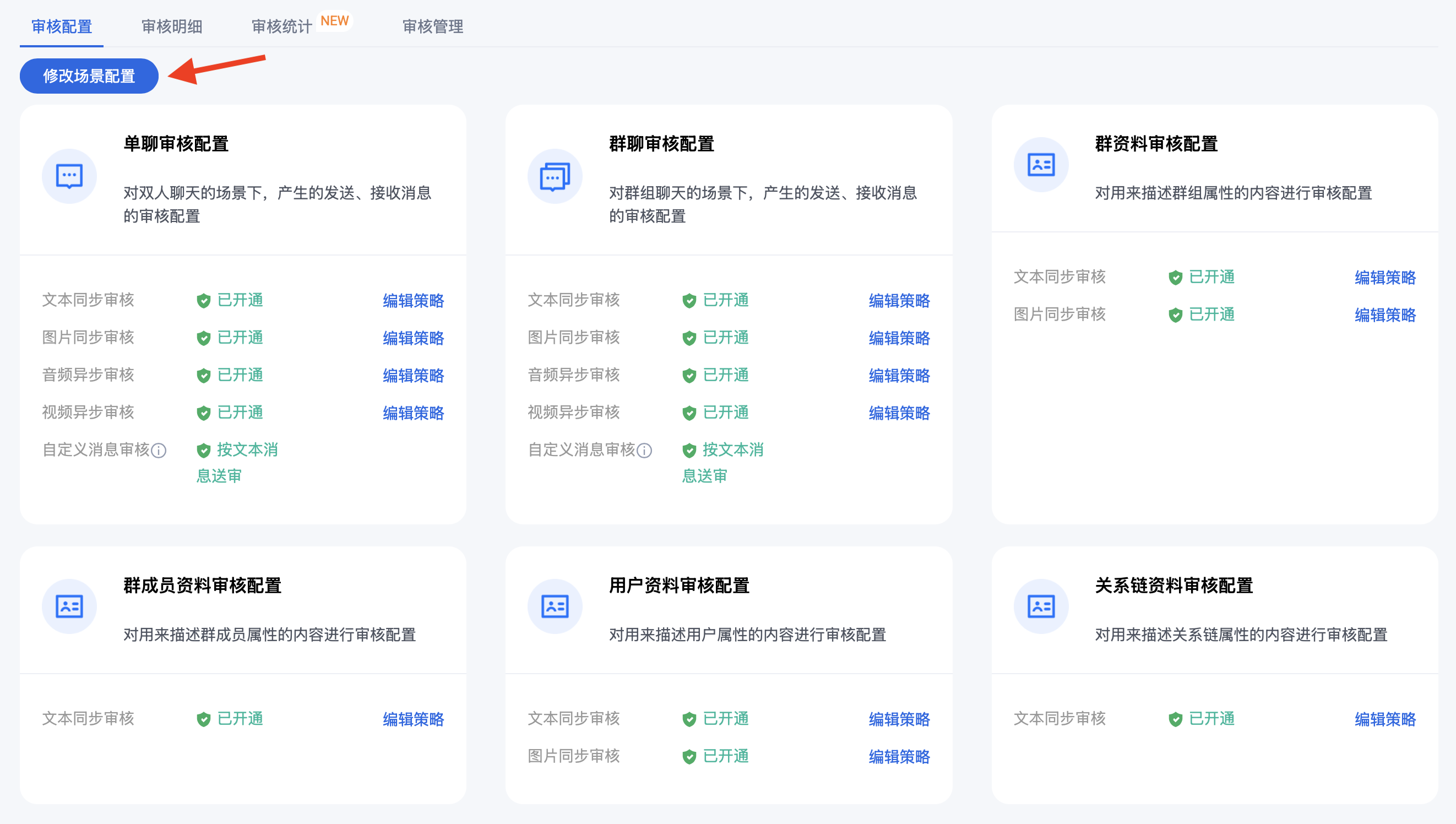
在弹窗中勾选/取消勾选对应项目,点击确定即可。
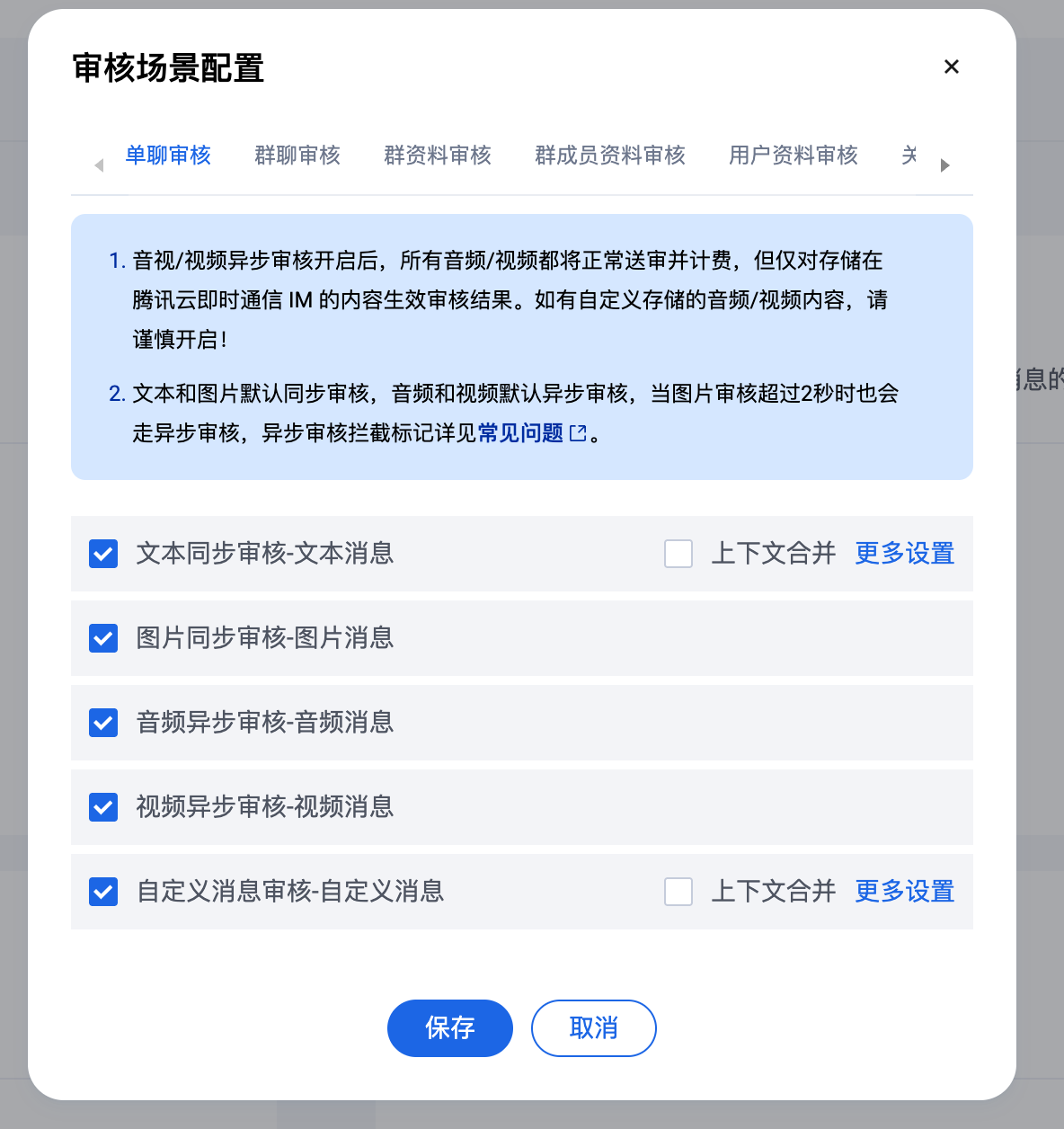
音视图文消息检测
按照业务所需,勾选/取消勾选 对应场景下的文本、图片、音频、视频类型内容即可。
注意:
单聊、群聊场景下,将音频/视频异步审核开启后,所有音频/视频都将正常识别并计费,对存储在腾讯云即时通信 IM 的文件会拦截。如有自定义存储的音频/视频内容,请谨慎开启!如需识别和自定义存储的音频/视频内容,请通过监听音频/视频消息终端违规回调的方式,进行 UI 处理。
自定义消息检测
开启云端审核后,单聊、群聊的自定义消息默认当作文本识别。如果自定义消息结构为 json,只希望识别自定义消息的部分内容,可以参见如下方式:
方式一:按预设字段过滤识别
{"To_Account":"lumotuwe5","MsgRandom":121212,"MsgBody":[{"MsgType":"TIMCustomElem","MsgContent":{"Data":"{\\"key1\\":\\"value1\\",\\"message\\":\\"hello\\",\\"IMAuditContentType\\":\\"Text\\",\\"IMAuditContent\\":\\"hello\\"}","Desc":"hello","Ext":"www.qq.com","Sound":"dingdong.aiff"}}]}
参数说明:
字段 | 类型 | 说明 |
IMAuditContentType | String | 指定识别的内容类型:Text/Image/Audio/Video/JSONText。 |
IMAuditContent | String | 指定识别的内容。 类型为:Image/Audio/Video,该字段填文件 URL。 类型为:JSONText,该字段为自定义消息 JSON 结构体按照(单)多阶 key 值使用 . 拼接(string.string)的格式填写(最多两阶)。参考 固定字段识别示例。 |
说明:
指定的字段,需要放置在自定义消息 json 结构体的第一层 kv 元素里面。该方式支持音视图文等消息的审核,当识别的内容为音视频文件,违规的消息处置请参见 回调配置。如果一条自定义消息,有多个元素需要同时识别,支持按如下配置提取相应内容识别,最多支持10个元素识别:
{"IMAuditContents":[{"IMAuditContentType":"Text","IMAuditContent":"aaaa"},{"IMAuditContentType":"Image","IMAuditContent":"https://example.qq.com/1.jpg"}]} 方式二:按固定字段识别
每种自定义消息 json 结构体按照(单)多阶 key 值使用
. 拼接(string.string)的格式填写(最多两阶),支持多种 json 结构体按 | 拼接(string|string.string)填写(最多三种)。其中 string 字符串不超过 60 个字符。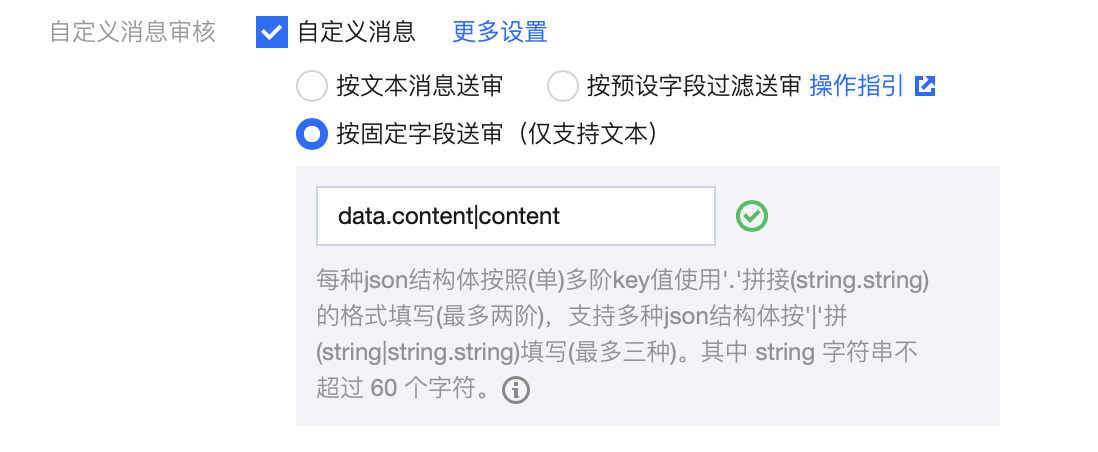
填写固定字段
data.content|content,其中 data.content 配置针对以下两种自定义消息 json 结构体过滤:{"data":{"content": "123"},"avatar":"http://xxxxx"}{"data":"{\\"content\\":\\"123\\"}","avatar":"http://xxxxx"}
配置通用场景策略
每个场景及内容类型均已配置默认识别策略,默认识别并拦截包含高风险色情/辱骂等内容,如果您需要更严格/更宽松的审核策略请按照下方指引操作。
如果需要编辑策略,请点击对应场景及内容类型右侧的编辑策略。
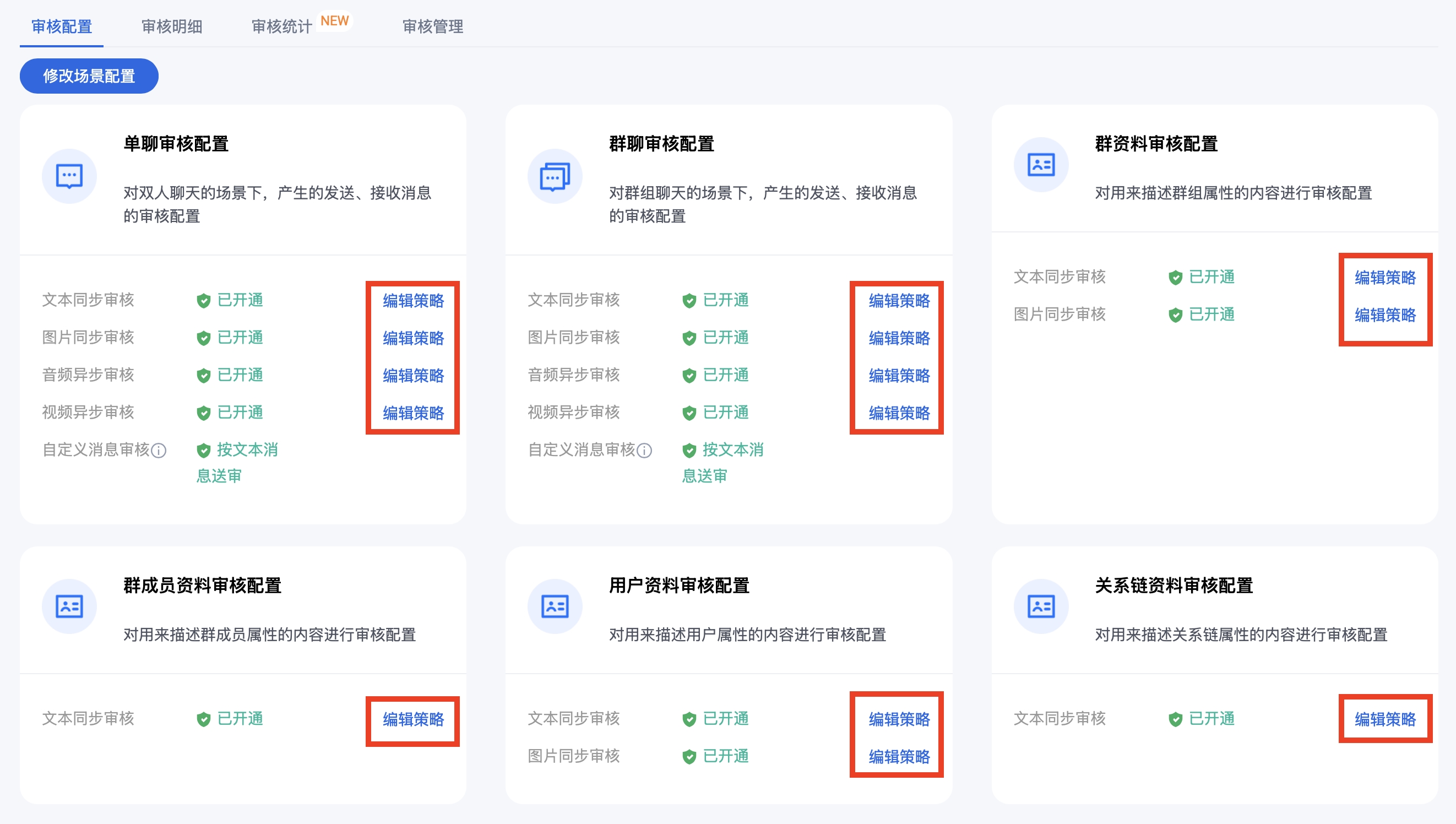
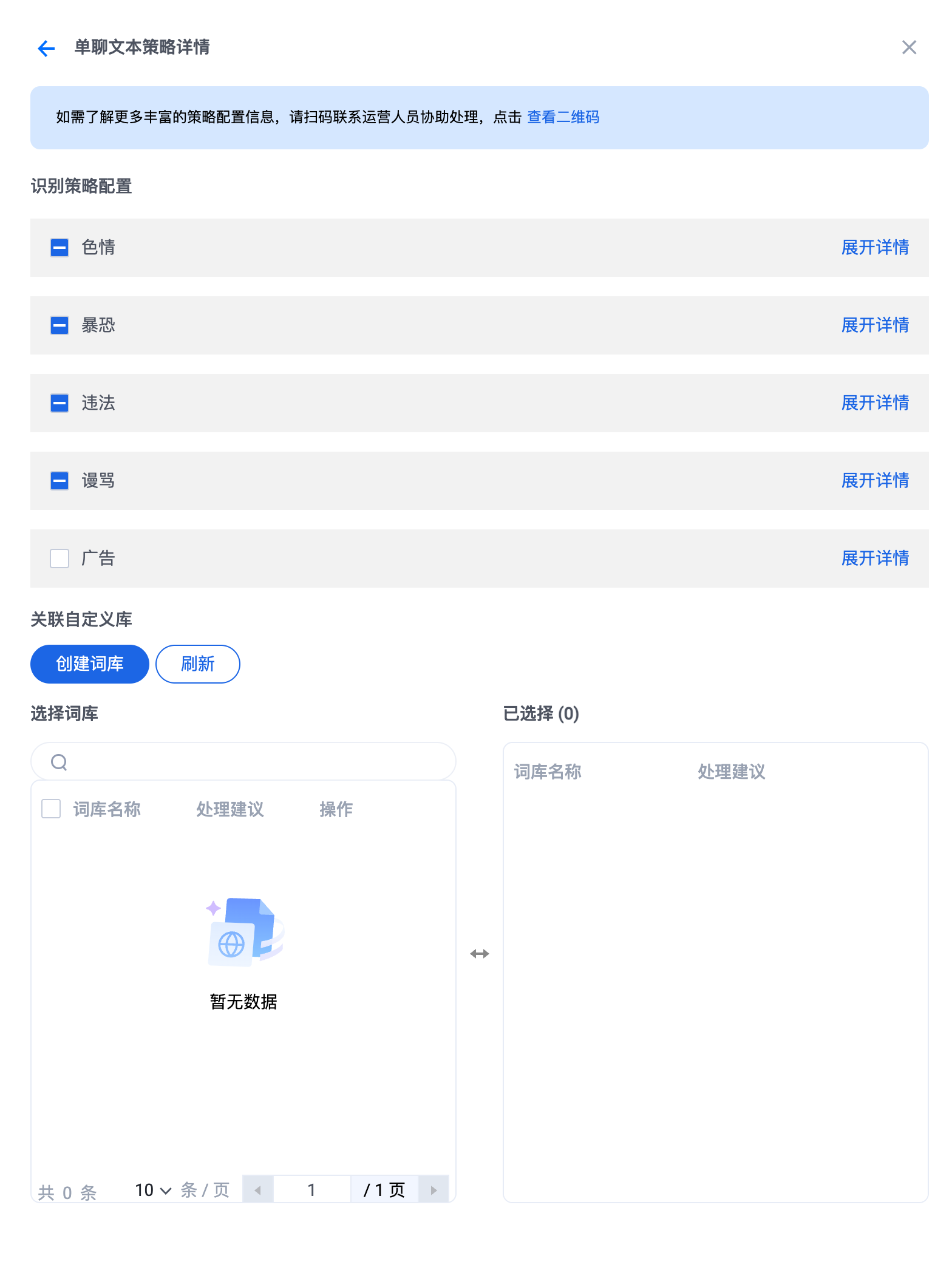
文本/图片策略配置:可以修改通用识别策略配置与自定义库信息。
通用识别策略配置:勾选需要识别的风险类型。
自定义库信息:勾选需要关联的自定义词库(最多可支持设置5个自定义词库)。
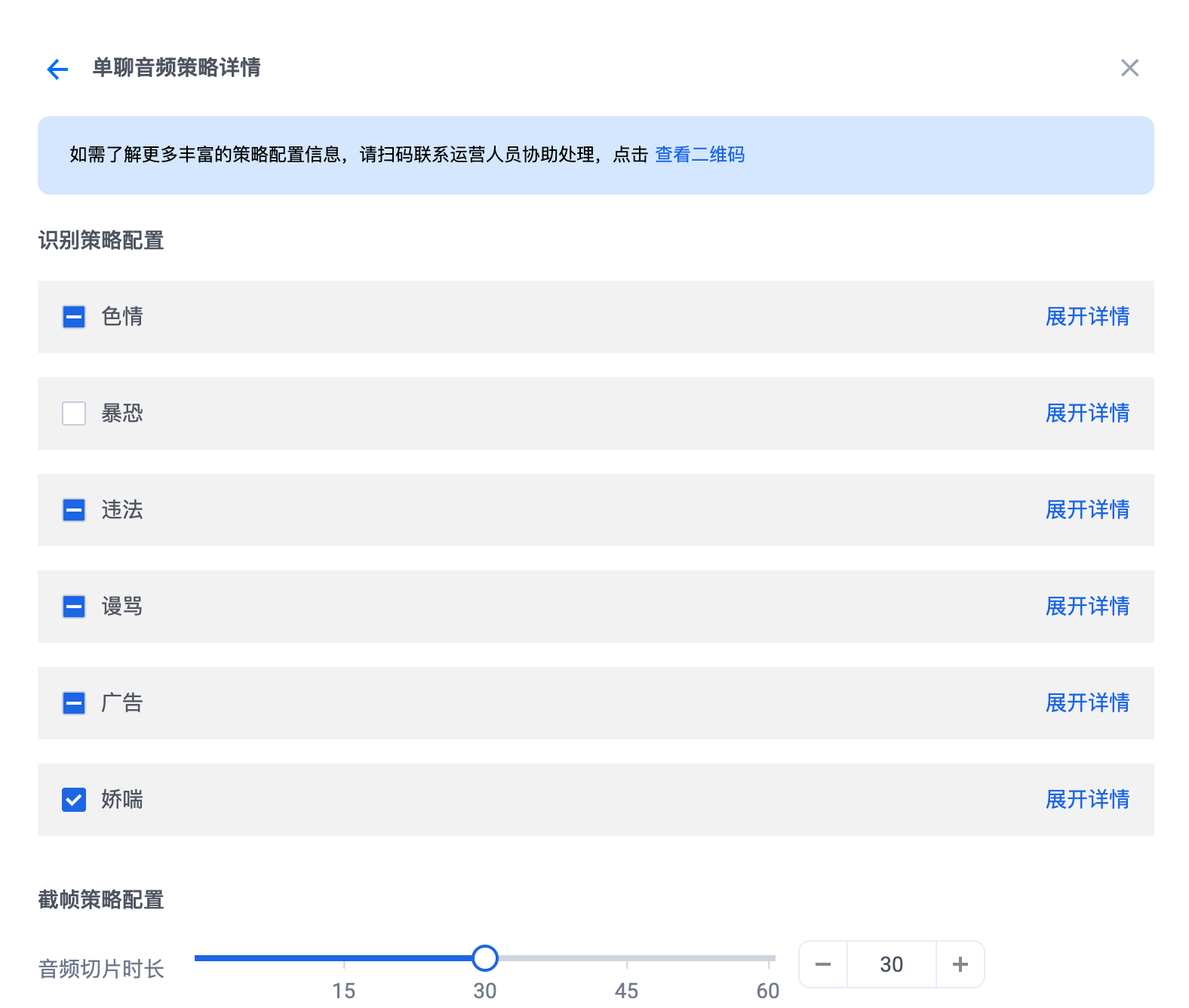
音频策略配置:可以修改通用识别策略配置、截帧策略配置与自定义库信息。
通用识别策略配置:勾选需要识别的风险类型。
截帧策略配置:音频切片时长配置,支持滑动设定或填写整数,范围[1,60]。
自定义库信息:勾选需要关联的自定义词库(最多可支持设置5个自定义词库)。
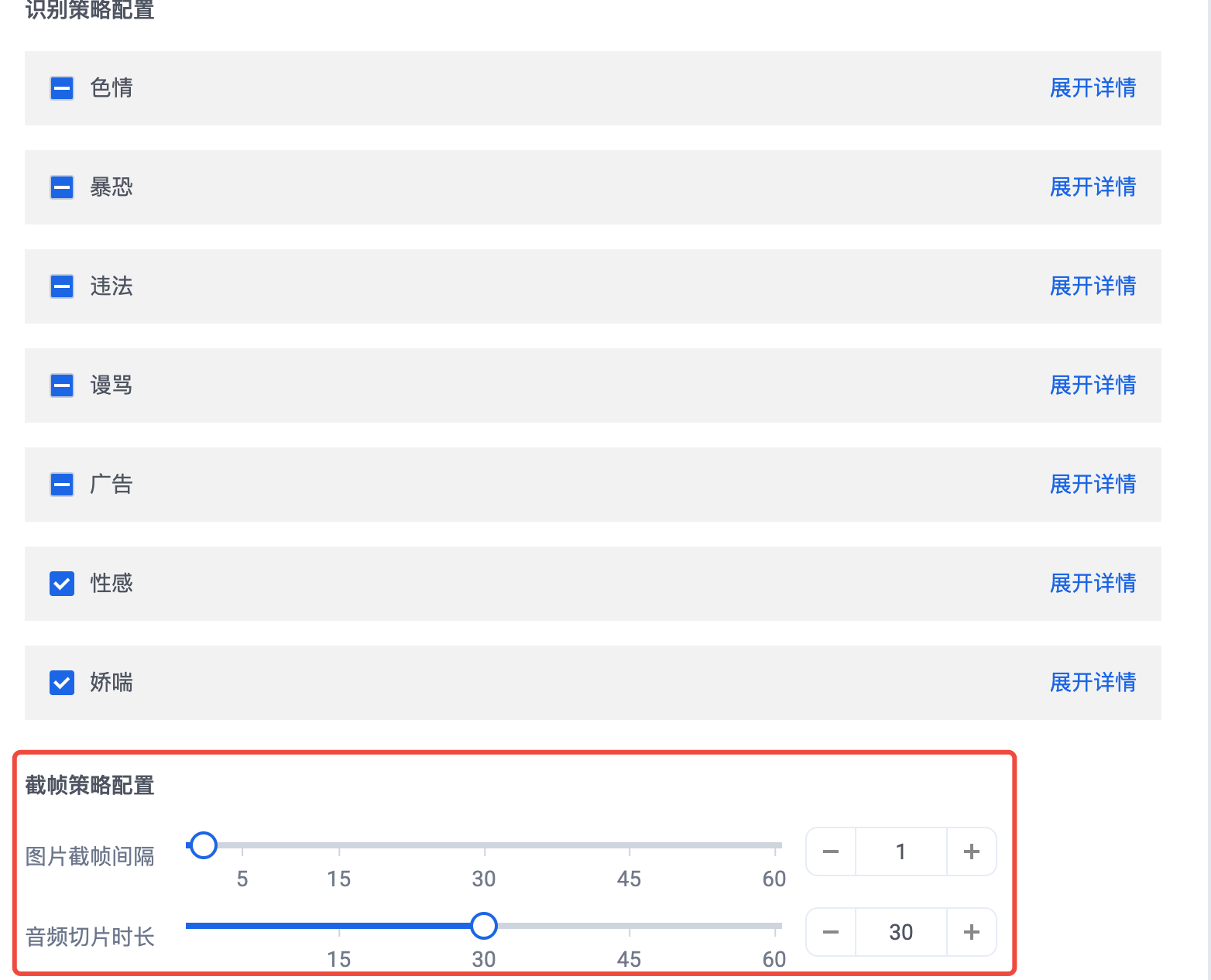
视频策略配置:可以修改通用识别策略配置、截帧策略配置与自定义库信息。
通用识别策略配置:勾选需要识别的风险类型,包括对图片和音频的识别。
截帧策略配置:审核配置,支持仅识别视频画面、仅识别音频和全部识别;图片截帧间隔,支持滑动设定或填写整数,范围 [1,60];音频切片时长配置,支持滑动设定或填写整数,范围 [1,60]。
自定义库信息:勾选需要关联的自定义词库(最多可支持设置5个自定义词库)。
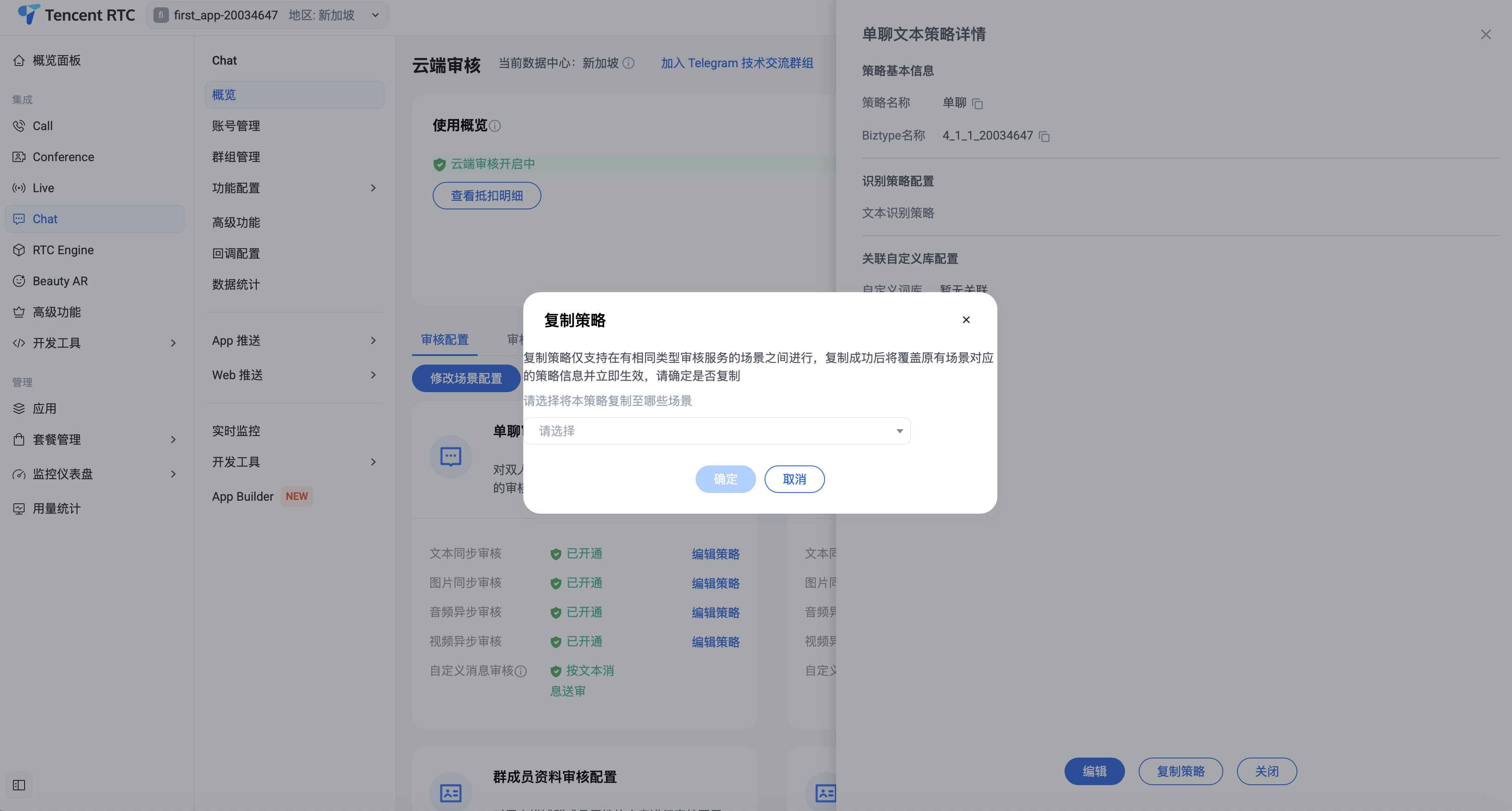
复制策略:图文音视的编辑策略时,点击复制策略,可以将本策略复制到下拉选择的其他场景。
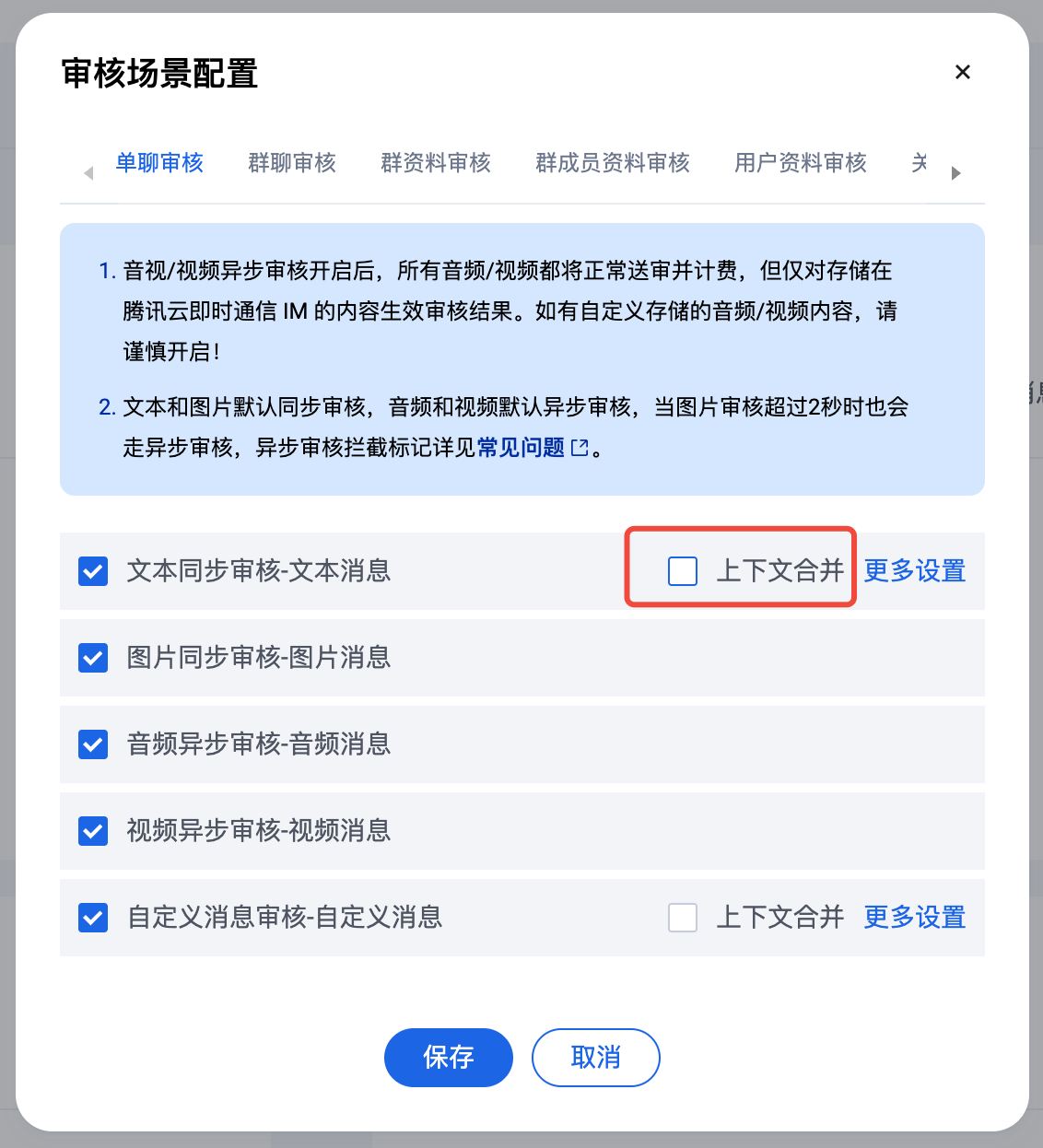
配置上下文合并识别
上下文合并识别主要用于在单聊或者群聊中,由于黑产为了规避检测风险,通常将一段违规文本拆分成多个消息进行发送,通过上下文合并识别功能,可以有效打击黑产电话、手机号码引流等情况。
开通云端审核服务后,如果需要聊天文本内容上下文合并识别,请点击修改场景配置。
在弹窗中勾选/取消勾选对应场景的上下文合并开关,点击保存即可。
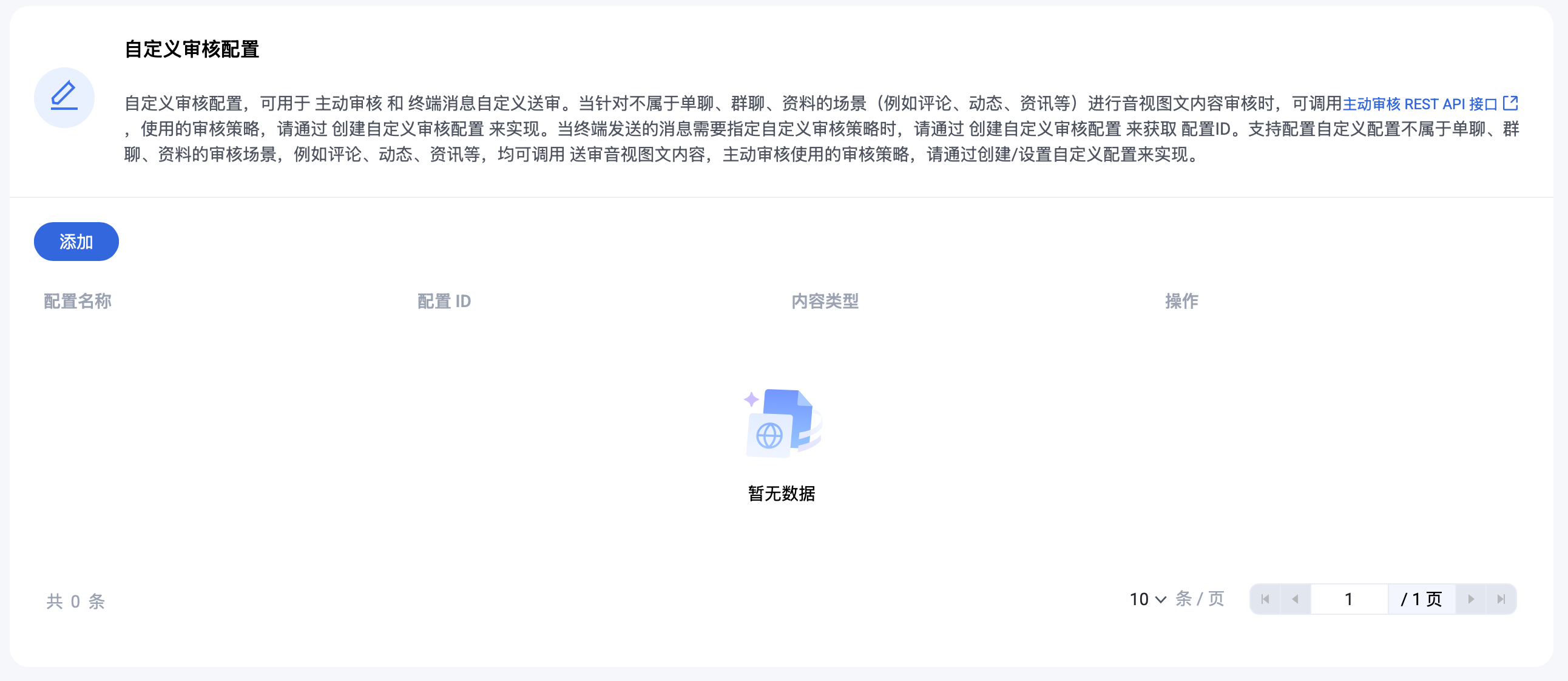
自定义识别场景及配置
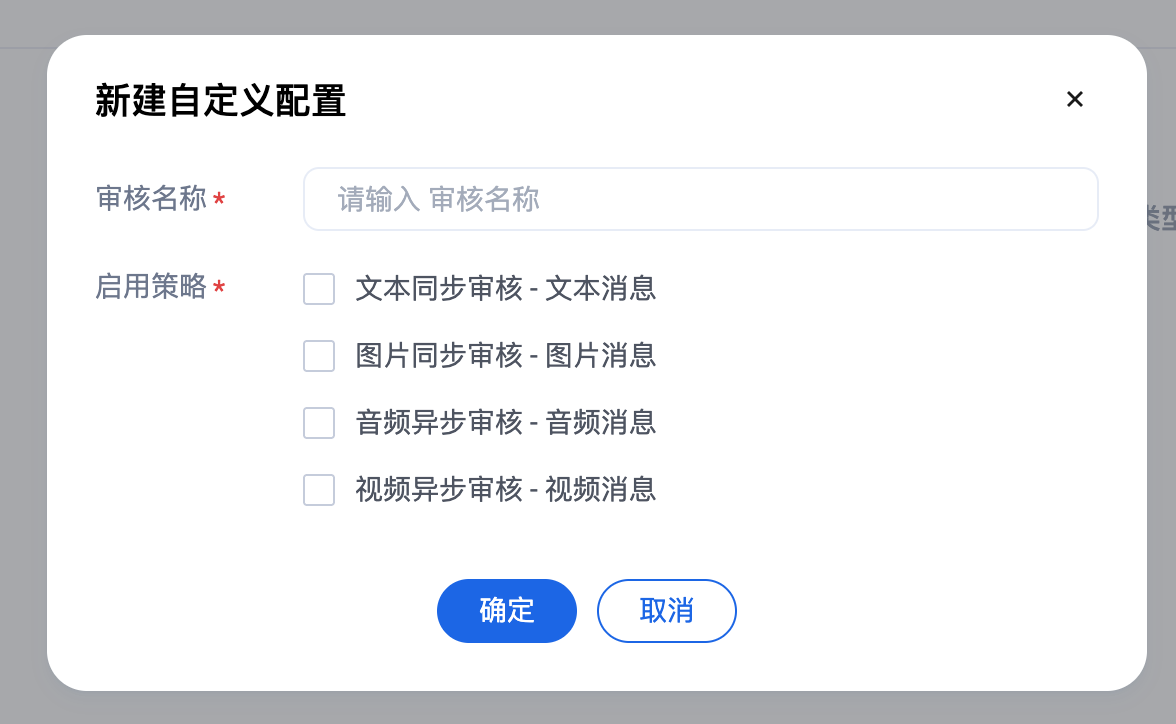
点击添加,输入名称,勾选启用策略,点击确定,即可完成一个自定义配置的创建操作。
创建完成后,可在列表中,看到新创建的配置信息。点击复制图标,获取配置 ID:
当终端发送的消息需要指定自定义识别策略时,请通过创建自定义识别配置来获取配置 ID,在终端发消息接口中赋值;当针对不属于单聊、群聊、资料的场景(例如评论、动态、资讯等)进行音视图文内容识别时,可调用 主动审核 REST API 接口,接口使用的识别策略,请通过创建自定义识别配置来获取配置 ID 给 AuditName 赋值。
文档反馈