- 动态与公告
- 新手指引
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 最佳实践
- 运维开发指南
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Instance APIs
- RenameInstance
- OfflineIsolatedDBInstance
- ModifyDBInstanceSpec
- IsolateDBInstance
- DescribeSpecInfo
- DescribeDBInstances
- DescribeClientConnections
- CreateDBInstanceHour
- AssignProject
- RenewDBInstances
- DescribeSlowLogs
- DescribeSlowLogPatterns
- InquirePriceRenewDBInstances
- InquirePriceModifyDBInstanceSpec
- InquirePriceCreateDBInstances
- DescribeDBInstanceDeal
- DescribeSecurityGroup
- DescribeInstanceParams
- ModifyDBInstanceSecurityGroup
- ModifyDBInstanceNetworkAddress
- Backup APIs
- Account APIs
- Task APIs
- Other APIs
- Data Types
- Error Codes
- SDK 参考
- 常见问题
- 词汇表
- 联系我们
- 动态与公告
- 新手指引
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 最佳实践
- 运维开发指南
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Instance APIs
- RenameInstance
- OfflineIsolatedDBInstance
- ModifyDBInstanceSpec
- IsolateDBInstance
- DescribeSpecInfo
- DescribeDBInstances
- DescribeClientConnections
- CreateDBInstanceHour
- AssignProject
- RenewDBInstances
- DescribeSlowLogs
- DescribeSlowLogPatterns
- InquirePriceRenewDBInstances
- InquirePriceModifyDBInstanceSpec
- InquirePriceCreateDBInstances
- DescribeDBInstanceDeal
- DescribeSecurityGroup
- DescribeInstanceParams
- ModifyDBInstanceSecurityGroup
- ModifyDBInstanceNetworkAddress
- Backup APIs
- Account APIs
- Task APIs
- Other APIs
- Data Types
- Error Codes
- SDK 参考
- 常见问题
- 词汇表
- 联系我们
问题描述
在日常运维中,MongoDB 数据库,如果 CPU 利用率过高,通常容易导致系统异常。例如读写速率变慢、链接耗光、超时增加等,大量的访问超时还会触发客户端反复重连认证,最终可能会引起数据库“雪崩”。
生产中的 MongoDB 数据库,出现 CPU 利用率过高场景是很常见的,这种问题一般由 SQL 异常、流量过高、产生内存排序、语句无索引、或索引使用不当等情况导致。
当数据库执行查询、修改等操作时,CPU 会先从存储引擎 cache 中请求数据:
如果引擎 cache 中存在对应的数据,CPU 执行计算任务后会将结果返回给用户,与此同时,还可能涉及到排序类高消耗 CPU 的动作。
如果内存中不存在对应的数据,还会触发从磁盘获取数据的动作。
这两个数据获取过程分别称为逻辑读和物理读。因此,性能较低的 SQL,在执行时容易让数据库产生大量的逻辑读,从而导致 CPU 利用率过高,也可能让数据库产生大量的物理读,从而导致 IOPS 和 I/O 时延过高。
解决方案
使用数据库智能管家 DBbrain,通过异常诊断功能,可定位 CPU 过高的异常问题,可确定问题发生时间,确定造成问题的具体 SQL,还能给您对应的处理措施;在解决问题的同时,结合慢 SQL 优化功能 ,通过语句优化分析建议,可帮您精准分析语句情况,避免类似问题再次产生。
异常诊断:7 * 24小时异常发现诊断,提供实时优化建议。
慢 SQL 分析:针对当前实例出现的慢 SQL 进行分析,并给出慢 SQL 的优化建议。
实时会话:查看当前生产库中正在执行中的操作,可针对异常操作做处理。
方式一:使用“异常诊断”功能排查数据库异常情况(推荐)
异常诊断功能提供故障主动定位和优化,不需要任何数据库运维经验,不仅能发现 CPU 利用率过高的异常情况,经过多年 MongoDB 运维专家经验沉淀,结合机器学习、大数据与智能分析算法的运用,快速复制资深数据库专家经验,赋能您的数据库,智能运维 MongoDB 数据库,可以实时发现 MongoDB 生产数据库中几乎全部的异常与故障问题。
操作步骤及示例如下:
1. 登录 DBbrain 控制台,在左侧导航选择诊断优化,在上方选择异常诊断页。
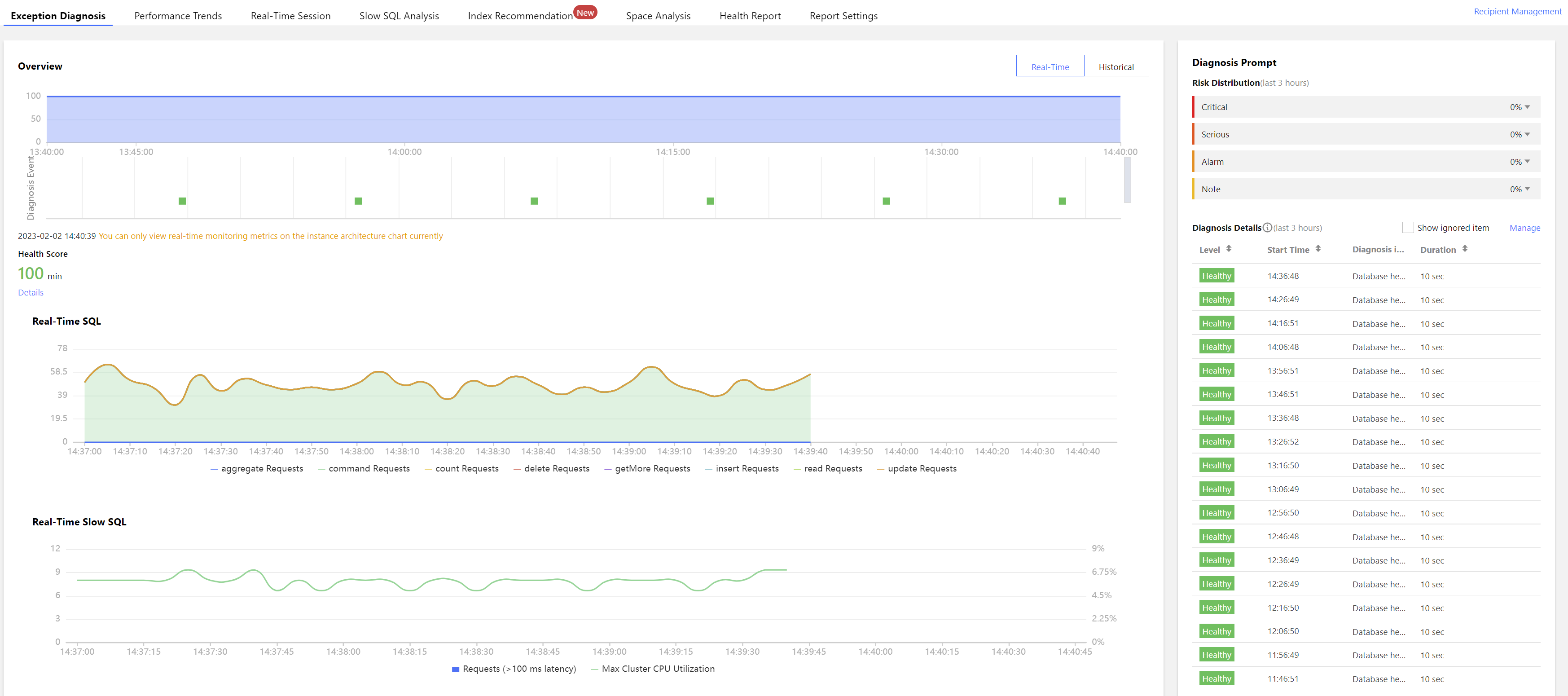
2. 在左上角选择实例 ID(可输入和搜索),切换至目标实例。
3. 在页面中选择实时或历史要查询的时间,若该时间段内存在故障,可在右侧的诊断提示中查看到概要信息。
4. 单击实时/历史诊断栏的查看详情或诊断提示栏的诊断项可进入诊断详情页。
事件概要:包括诊断项、起止时间、风险等级、持续时长、概要等信息。
现象描述:异常事件(或健康巡检事件)的外在表现现象的快照和性能趋势。
智能分析:分析导致性能异常的根本原因,定位具体操作。
优化建议:提供优化指导建议。
5. 选择优化建议页,即可查看 DBbrain 针对该故障给出的优化建议。
方式二:使用“慢 SQL 分析”功能排查导致 CPU 利用率过高的库表信息
1. 登录 DBbrain 控制台,在左侧导航选择诊断优化,在上方选择慢 SQL 分析页。
2. 在左上角选择实例 ID(可输入和搜索),切换至目标实例。
3. 在页面中选择要查询的时间,若此实例在该时间段中有慢 SQL,SQL 统计会以柱形图的方式展示慢 SQL 产生的时间点和个数。
单击柱形图,下方的列表会显示对应的所有慢 SQL 信息(模板聚合之后的 SQL),右方会显示该时间段内 SQL 的耗时分布。
4. 针对 SQL 列表中 SQL 执行的数据进行判断和筛选,下面简单介绍一种判断方式:
4.1 先按照平均耗时(或者最大耗时)降序,重点关注耗时较大的 SQL,不推荐使用总耗时,容易受到执行次数多而累加的干扰。
4.2 然后关注返回行数和扫描行数的值。
若发现返回行数与扫描行数值相等的 SQL,大概率是全表查找并返回了。
若发现几行 SQL 都有很多扫描行数,但返回行数都为0或特别小,说明系统产生了大量的逻辑读和物理读。当查找的数据量过大且内存不足时,该请求必然会产生大量的物理 I/O 请求,导致 I/O 资源大量消耗;大量的逻辑读便会占用大量的 CPU 资源,导致 CPU 利用率过高。
方式三:使用“实时会话”功能对慢 SQL 进行 Kill 操作
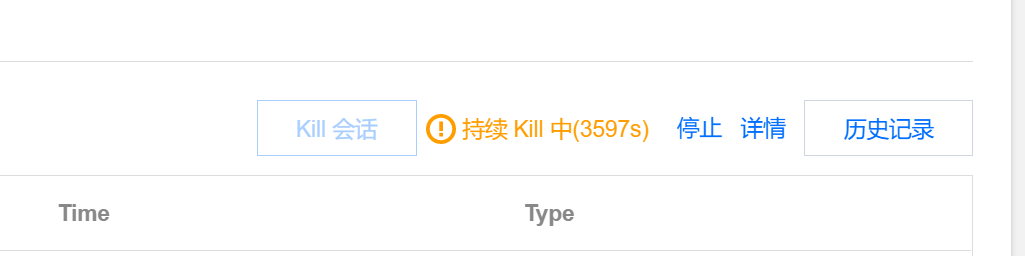
MongoDB 内核会记录当前正在执行的 currentOp 信息,DBbrain 的实时会话功能可以看到数据库正在执行中的所有操作,并且支持 Kill 指定会话,可以把耗时 SQL 直接 Kill 掉来释放 CPU、磁盘 IO 等资源。另外还提供持续 Kill 功能,可以根据条件或信息持续 Kill 会话,在数据库产生堵塞的异常情况下,您可以使用持续 Kill 功能,紧急做异常处理。
获取会话信息,Kill 会话。
根据诊断优化 > 实时会话 > 活跃会话,选择需要 Kill 的会话信息,然后执行 Kill 操作。
持续 Kill 会话。
持续 Kill 会话功能可以针对 DB、HOST、Type、TIME 等维度进行配置,两个触发机制“超时自动退出”和“手动关闭”:
如需停止持续 Kill 会话,则单击停止,即可提前关闭未到超时时间的定时任务,或终止手动触发的任务。

 是
是
 否
否
本页内容是否解决了您的问题?