2. On the left sidebar, click Ops Feature Management to enter the feature management page.
3. Find the target cluster and click Settings.
4. In the pop-up window, click Edit in the Log Collection column.
5. Click Upgrade Component.
Network and Permission
What should I do if the TencentCloud API domain name is inaccessible?
cls-provisioner, the component for communication between the TKE log collection component and CLS, uses a TencentCloud API domain, which must be kept accessible. If the component deployment fails, or you find the following error in logs, the domain name is inaccessible.
As shown above, a cls-provisioner start exception occurred, and you can find in logs that the cls.internal.tencentcloudapi.com domain name is inaccessible.
The private and public domain names are accessible by default from servers in Tencent Cloud. A common cause of this problem is that the DNS configuration on the TKE node is modified. You can fix it in the following two ways:
Add the default Tencent Cloud DNS configuration to the DNS configuration on the TKE node server.
If the DNS of the host is the server CoreDNS, add Tencent Cloud DNS configure to CoreDNS.
Note:
We recommend you check the DNS configuration on the relevant TKE nodes first when the domain name is inaccessible in the TKE cluster.
What should I do if the CLS log upload domain name is inaccessible?
Log upload domain names are different from TencentCloud API domain names and are in the format of <region>.cls.tencentcs.com (public network domain) or <region>.cls.tencentcs.com (private network domain). For more information, see Available Regions.
Solution:
Make the domain name accessible on the corresponding cluster node server.
What should I do if a no permission error was reported during communication between cls-provisioner and CLS?
Sometimes an error similar to the following may be reported during communication between cls-provisioner and CLS:
Solution:
Associate the QcloudAccessForTKERoleInOpsManagement policy in the TKE_QCSRole role under the account that created the TKE cluster.
Collection
What should I do if logs collected to CLS are truncated?
In some cases, the output type of user logs is standard output, but logs collected to CLS are truncated. This happens as json-tool, the default log collection tool of Docker, limits the size of single-line logs. Therefore, logs exceeding 16 KB in size will be truncated.
Solution:
Modify the log output configuration to make the size of printed single-line logs below 16 KB.
What should I do if the same logs are collected repeatedly?
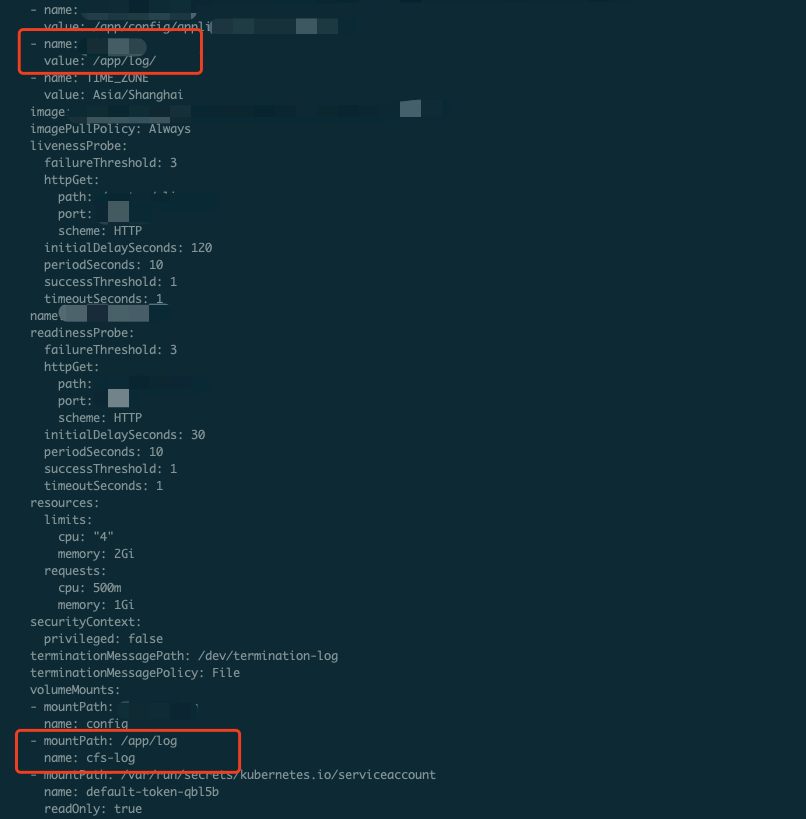
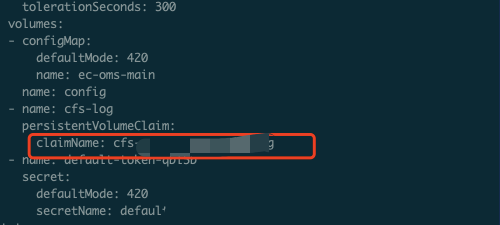
If you find that some logs are collected repeatedly in the CLS console, you can check the log output path first to see whether logs are output to the persistent storage created by PV/PVC.
If logs are output to the persistent storage, when a business Pod is recreated, logs will be collected again. You can run the following command to view the YAML definition of the Pod:
kubectl get pods <pod_name> -n <namespace> -o yaml |less
If information similar to the following is returned, logs are output to the persistent storage.
The business uses CFS, and CFS is mounted to the container.
CFS is used.
Solution:
If logs don't need to be persistently stored, you can enable log collection in the container cluster to collect logs to CLS.
If logs need to be persistently stored, you can modify the collection policy to Incremental collection when configuring the LogListener rule in the CLS console; however, incremental collection cannot ensure that all logs will be collected.
What should I do if some logs are not collected?
LogListener currently doesn't support logs stored in NFS. It subscribes to Linux kernel events to get the file update information instead of actively scanning target files.
As NSF file update information is generated on the NFS server, and file update events cannot be generated in the local kernel, such information cannot be perceived by LogListener. Therefore, NFS file logs cannot be collected in real time.
What should I do if the collection configuration doesn't match the Pod?
You can troubleshoot as follows:
1. Run the following command to check whether Pod labels match the collection configuration:
kubectl get pods <pod_name> -n <namespace> --show-labels
If so, proceed to the next step.
If not, modify the collection configuration according to the correct content.
2. Check whether the Pod workload (Deployment or StatefulSets) match the collection configuration.
kubectl get pods -n <namespace>|grep testa
If so, proceed to the next step.
If not, modify the collection configuration according to the correct content.
3. Use the following command to view the YAML definition of the Pod and check whether the container name matches that specified in the collection configuration.
kubectl get pods <pod_name> -n <namespace> -o yaml
If so, the task is completed.
If not, modify the collection configuration according to the correct content.
What should I do if the collection path is incorrect?
When collecting container files or host files, check whether the collection directory path is correct and contains logs complying with the collection rule.
Can I use soft links for log files?
In container file collection scenarios, matched log files cannot have soft links.
In Kubernetes scenarios, CLS collects logs by parsing the location of the container file on the host. As a container soft link points to a path within the container, if a matched file to be collected has a soft link, it cannot be reached correctly.
Solution:
Modify the collection rule path and matched files to use the actual log file path and log files to be collected, so as to avoid matching soft links.
What are the limits for collection scale?
As resources are restricted when LogListener is used to collect container logs, the numbers of directories and files listened on are also limited as follows:
Directories listened on: 5,000
Files listened on: 10,000
You may encounter such problems when collecting container or host files. Generally, the following information will be displayed in LogListener logs if expired log files are not cleared:
Files and directories exceeding the limits will not be listened on by LogListener; therefore, some target log files may not be collected.
For more information, see LogListener Limits.
Solution:
In the log directory, run the tree command to check whether the current numbers of directories and files in the entire directory structure reach the LogListener limits.
If not, run tree -L 5 under /var/log/tke-log-agent on the host of the business container to check whether the host limits are reached
As LogListener limits take effect for the entire host, if the number of files listened on in a container doesn't reach the threshold, the reason may be that the number of files in all containers on the host has reached the limit.
If so, archive expired logs in time to reduce the resources consumed by directories and files listened on by LogListener.
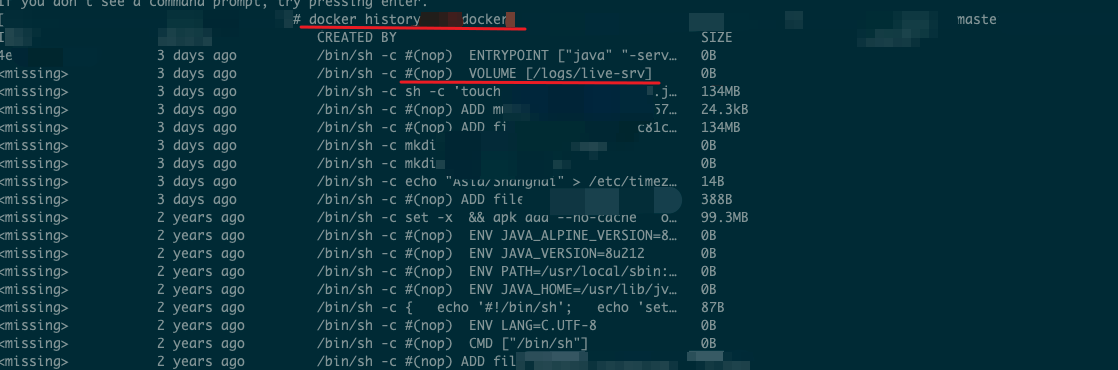
What should I do if a volume is defined in Dockerfile?
In Docker scenario, run the docker history $image command to view the image rebuild information.
In Containerd scenarios, run the crictl inspecti $image command to view the image rebuild information.
The following information is returned. You can see that the /logs/live-srv volume is customized in the Dockerfile, which also happens to be the log directory. Such an operation prevents the log collection component from finding correct log files.
Solution:
Modify the Dockerfile to remove the volume, rebuild the image, and redeploy the service.
Modify the directory to which service logs are written, so that logs are not written to the volume path defined in the Dockerfile.
Others
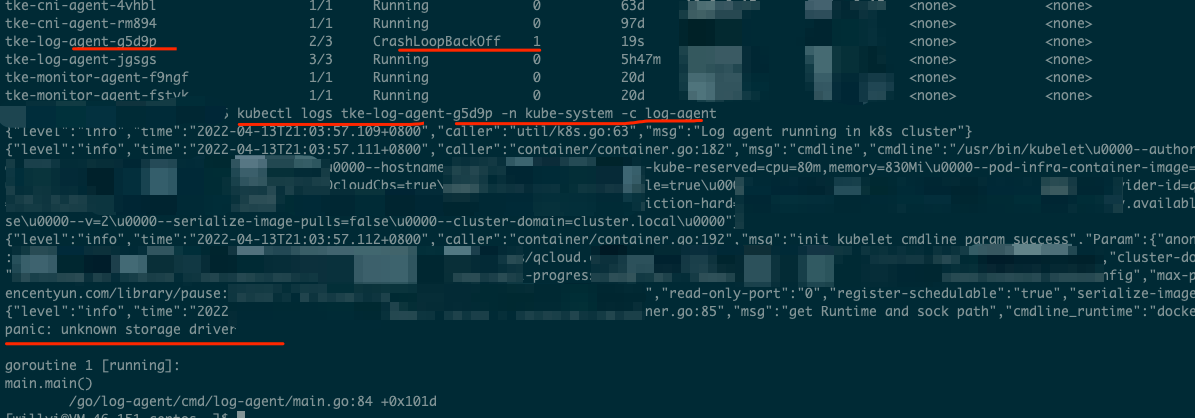
What should I do if the identified container engine type is incorrect?
In some Docker scenarios, bugs on earlier versions may be triggered, causing a log collection component start failure and generating panic logs.
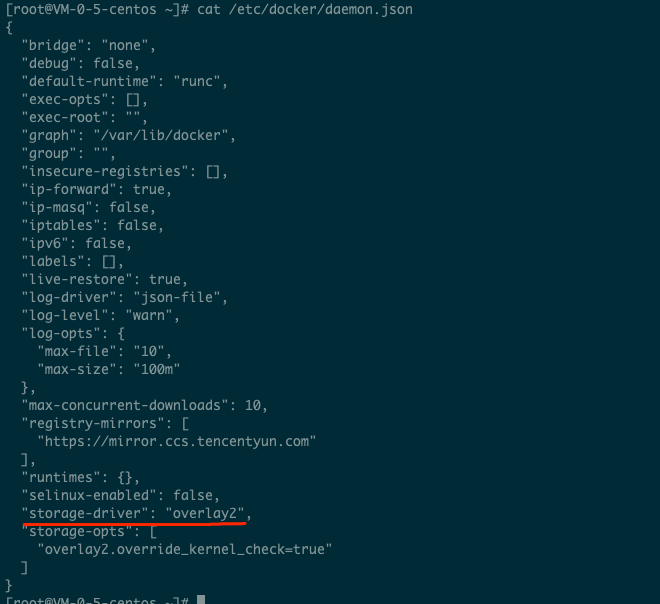
This happens mainly because the Docker configuration of TKE cluster nodes is customized, leading to the error as shown below:
Solution:
Add "storage-driver": "overlay2" to the /etc/docker/daemon.json configuration file as shown below:
Upgrade the log collection component version in the TKE console. As this problem has been fixed on new versions of the component, you don't need to modify the Docker configuration.
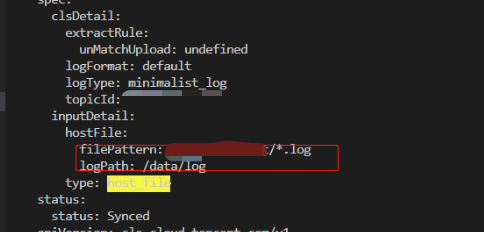
What should I do if a subdirectory is set in filePattern?
As shown below, a subdirectory is set in the filePattern parameter, making it unable to collect logs.
Solution:
Set the log file directory in the logPath parameter, and set only the file type parameter in filePattern.