Schema Registry 接入 CKafka
Download
聚焦模式
字号
无论是使用传统的 Avro API 自定义序列化类与反序列化类,还是使用 Twitter 的 Bijection 类库实现 Avro 的序列化与反序列化,两种方法有相同的缺点:在每条 Kafka 记录里都嵌入了 Schema,从而导致记录的大小成倍增加。但是不管怎样,在读取记录时仍然需要用到整个 Schema,所以要先找到 Schema。
CKafka 提供了数据共用一个 Schema 的方法:将 Schema 中的内容注册到 Confluent Schema Registry,Kafka Producer 和 Kafka Consumer 通过识别 Confluent Schema Registry 中的 schema 内容进行序列化和反序列化。
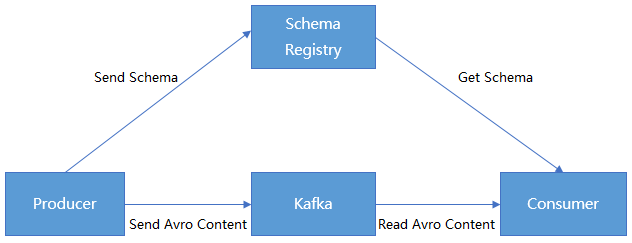
前提条件
下载 Download JDK 8。
已 创建实例。
操作步骤
步骤1:获取实例接入地址并开启自动创建 Topic
1. 登录 CKafka 控制台。
2. 在左侧导航栏选择实例列表,单击实例的“ID”,进入实例基本信息页面。
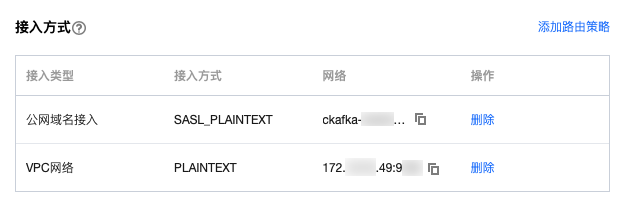
3. 在实例的基本信息页面的接入方式模块,可获取实例的接入地址。
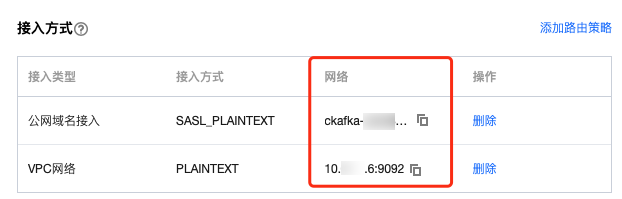
4. 在自动创建 Topic模块开启自动创建 Topic。
说明
启动 oss 会创建 schemas 主题,所以实例中需要开启自动创建主题。
步骤2:准备 Confluent 配置
1. 修改 oss 配置文件中的 server 地址等信息。
PLAINTEXT 接入方式,配置信息如下:
kafkastore.bootstrap.servers=PLAINTEXT://xxxxkafkastore.topic=schemasdebug=true
SASL_PLAINTEXT 接入方式,配置信息如下:
kafkastore.bootstrap.servers=SASL_PLAINTEXT://ckafka-xxxx.ap-xxx.ckafka.tencentcloudmq.com:50004 kafkastore.security.protocol=SASL_PLAINTEXT kafkastore.sasl.mechanism=PLAIN kafkastore.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username='ckafka-xxxx#xxxx' password='xxxx';kafkastore.topic=schemasdebug=true
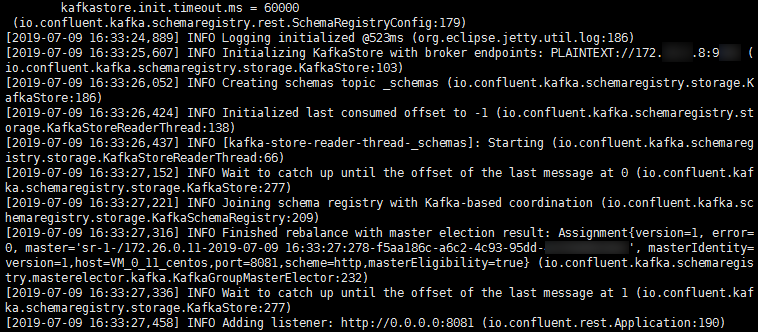
2. 执行如下命令启动 Schema Registry。
bin/schema-registry-start etc/schema-registry/schema-registry.properties
运行结果如下:
步骤3:收发消息
现有 schema 文件,其中内容如下:
{"type": "record","name": "User","fields": [{"name": "id", "type": "int"},{"name": "name", "type": "string"},{"name": "age", "type": "int"}]}
1. 注册 schema 到对应 Topic(注册 Topic 名为 test)。
下面的脚本是直接在 Schema Registry 部署的环境中使用 curl 命令调用对应 API 实现注册的一个示例:
curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" \\--data '{"schema": "{\\"type\\": \\"record\\", \\"name\\": \\"User\\", \\"fields\\": [{\\"name\\": \\"id\\", \\"type\\": \\"int\\"}, {\\"name\\": \\"name\\", \\"type\\": \\"string\\"}, {\\"name\\": \\"age\\", \\"type\\": \\"int\\"}]}"}' \\http://127.0.0.1:8081/subjects/test/versions
2. Kafka Producer 发送数据:
package schemaTest;import java.util.Properties;import java.util.Random;import org.apache.avro.Schema;import org.apache.avro.generic.GenericData;import org.apache.avro.generic.GenericRecord;import org.apache.kafka.clients.producer.KafkaProducer;import org.apache.kafka.clients.producer.Producer;import org.apache.kafka.clients.producer.ProducerRecord;public class SchemaProduce {public static final String USER_SCHEMA = "{\\"type\\": \\"record\\", \\"name\\": \\"User\\", " +"\\"fields\\": [{\\"name\\": \\"id\\", \\"type\\": \\"int\\"}, " +"{\\"name\\": \\"name\\", \\"type\\": \\"string\\"}, {\\"name\\": \\"age\\", \\"type\\": \\"int\\"}]}";public static void main(String[] args) throws Exception {Properties props = new Properties();// 添加CKafka实例的接入地址props.put("bootstrap.servers", "xx.xx.xx.xx:xxxx");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 使用 Confluent 实现的 KafkaAvroSerializerprops.put("value.serializer", "io.confluent.kafka.serializers.KafkaAvroSerializer");// 添加 schema 服务的地址,用于获取 schemaprops.put("schema.registry.url", "http://127.0.0.1:8081");Producer<String, GenericRecord> producer = new KafkaProducer<>(props);Schema.Parser parser = new Schema.Parser();Schema schema = parser.parse(USER_SCHEMA);Random rand = new Random();int id = 0;while(id < 100) {id++;String name = "name" + id;int age = rand.nextInt(40) + 1;GenericRecord user = new GenericData.Record(schema);user.put("id", id);user.put("name", name);user.put("age", age);ProducerRecord<String, GenericRecord> record = new ProducerRecord<>("test", user);producer.send(record);Thread.sleep(1000);}producer.close();}}
3. Kafka Consumer 消费数据:
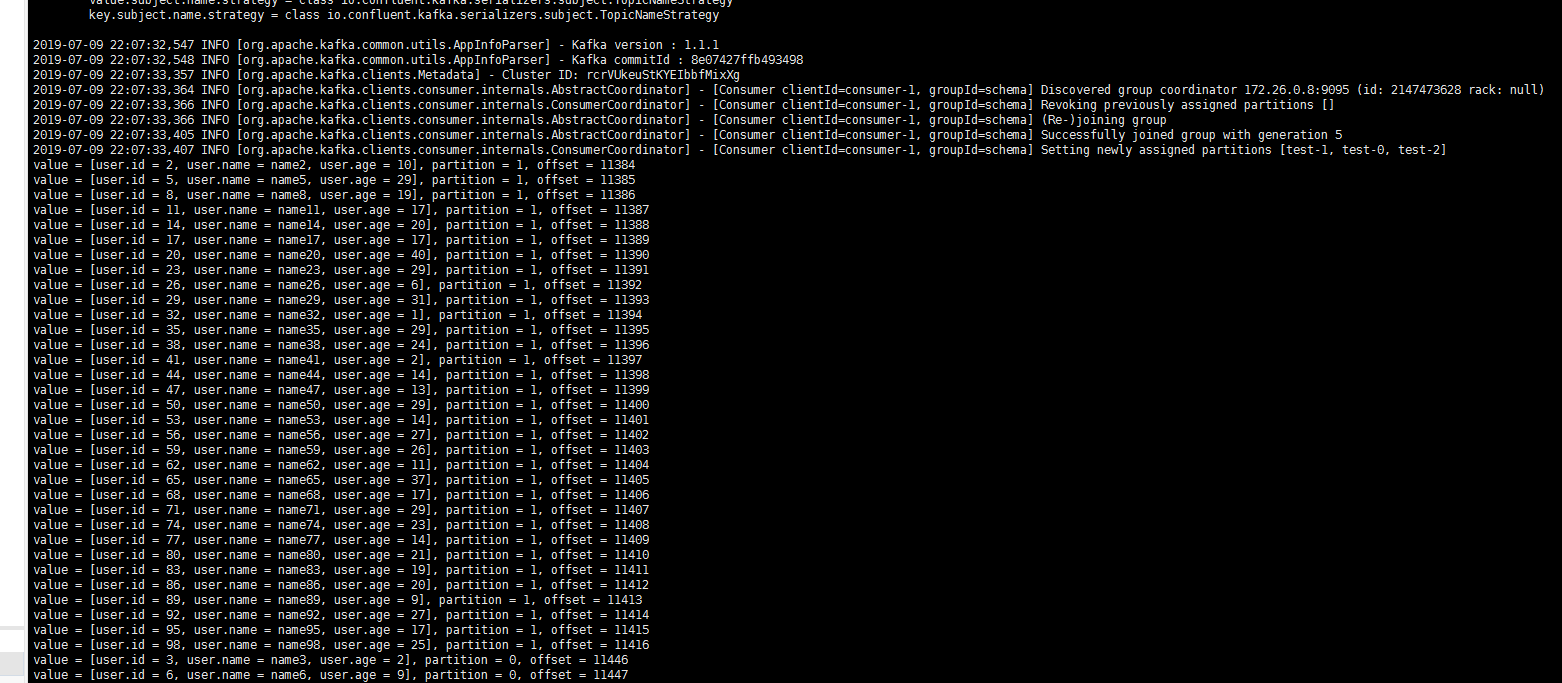
package schemaTest;import java.util.Collections;import java.util.Properties;import org.apache.avro.generic.GenericRecord;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.apache.kafka.clients.consumer.ConsumerRecords;import org.apache.kafka.clients.consumer.KafkaConsumer;public class SchemaProduce {public static void main(String[] args) throws Exception {Properties props = new Properties();props.put("bootstrap.servers", "xx.xx.xx.xx:xxxx"); //CKafka实例的接入地址props.put("group.id", "schema");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 使用Confluent实现的KafkaAvroDeserializerprops.put("value.deserializer", "io.confluent.kafka.serializers.KafkaAvroDeserializer");// 添加schema服务的地址,用于获取schemaprops.put("schema.registry.url", "http://127.0.0.1:8081");KafkaConsumer<String, GenericRecord> consumer = new KafkaConsumer<>(props);consumer.subscribe(Collections.singletonList("test"));try {while (true) {ConsumerRecords<String, GenericRecord> records = consumer.poll(10);for (ConsumerRecord<String, GenericRecord> record : records) {GenericRecord user = record.value();System.out.println("value = [user.id = " + user.get("id") + ", " + "user.name = "+ user.get("name") + ", " + "user.age = " + user.get("age") + "], "+ "partition = " + record.partition() + ", " + "offset = " + record.offset());}}} finally {consumer.close();}}}
启动消费者进行消费,下图为消费日志截图:
文档反馈