本文档介绍可能导致 Pod 一直处于 Pending 状态的几种情形,以及如何通过排查步骤定位异常原因。请按照以下步骤依次进行排查,定位问题后恢复正确配置即可。
现象描述
当 Pod 一直处于 Pending 状态时,说明该 Pod 还未被调度到某个节点上,需查看 Pod 分析问题原因。例如执行 kubectl describe pod <pod-name> 命令,则获取到的事件信息如下:
$ kubectl describe pod tikv-0
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 3m (x106 over 33m) default-scheduler 0/4 nodes are available: 1 node(s) had no available volume zone, 2 Insufficient cpu, 3 Insufficient memory.
可能原因
节点资源不足
不满足 nodeSelector 与 affinity
Node 存在 Pod 没有容忍的污点
低版本 kube-scheduler 的 bug
kube-scheduler 未正常运行
驱逐后其他可用节点与当前节点的有状态应用不在相同可用区
排查方法
检查节点是否资源不足
问题分析
节点资源不足有以下几种情况:
CPU 负载过高。
剩余可以被分配的内存不足。
剩余可用 GPU 数量不足(通常在机器学习场景、GPU 集群环境)。
为进一步判断某个 Node 资源是否足够,可执行以下命令获取资源分配信息:
kubectl describe node<node-name>
在返回信息中,请注意关注以下内容:
Allocatable:表示此节点能够申请的资源总和。
Allocated resources:表示此节点已分配的资源(Allocatable 减去节点上所有 Pod 总的 Request)。
造成影响
前者与后者相减,即可得出剩余可申请的资源大小。如果该值小于 Pod 的 Request,则不满足 Pod 的资源要求,Scheduler 在 Predicates(预选)阶段就会剔除掉该 Node,不会调度 Pod 到该 Node。
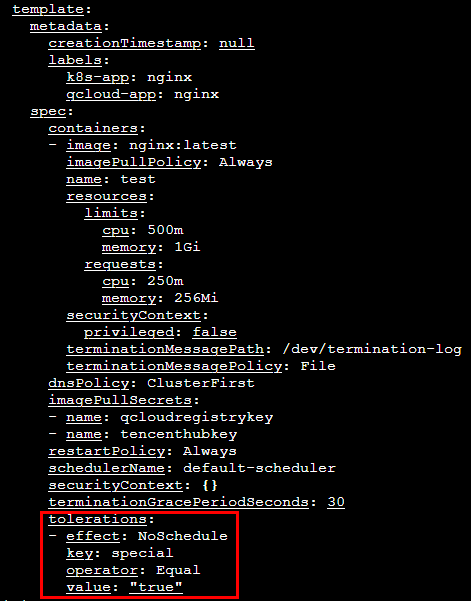
检查 nodeSelector 及 affinity 的配置
假设 Pod 中 nodeSelector 指定了节点 Label,则调度器将只考虑调度 Pod 到包含该 Label 的 Node 上。当不存在符合该条件的 Node 时,Pod 将无法被调度。更多相关信息可前往 Kubernetes 官方网站 进行查看。
此外,如果 Pod 配置了 affinity(亲和性),则调度器根据调度算法可能无法发现符合条件的 Node,从而无法调度。affinity 包括以下几类:
nodeAffinity:节点亲和性,可以看作增强版的 nodeSelector,用于限制 Pod 只允许被调度到某一部分符合条件的 Node。
podAffinity:Pod 亲和性,用于将一系列有关联的 Pod 调度到同一个地方,即同一个节点或同一个可用区的节点等。
podAntiAffinity:Pod 反亲和性,防止某一类 Pod 调度到同一个地方,可以有效避免单点故障。例如,将集群 DNS 服务的 Pod 副本分别调度到不同节点,可避免因一个节点出现故障而造成整个集群 DNS 解析失败,甚至使业务中断。
服务部署成功且正在运行时,若此时节点突发故障,就会触发 Pod 驱逐,并创建新的 Pod 副本调度到其他节点上。对于已挂载了磁盘的 Pod,通常需要被调度到与当前故障节点和挂载磁盘所处同一个可用区的新的节点上。若集群中同一个可用区内不具备满足可调度条件的节点时,即使其他可用区内具有满足条件的节点,此类 Pod 仍不会调度。
限制已挂载磁盘的 Pod 不能调度到其他可用区的节点的原因如下:
云上磁盘允许被动态挂载到同一个数据中心上的不同机器,为了有效避免网络时延极大地降低 IO 速率,通常不允许跨数据中心挂载磁盘设备。