Table Creation Practice
Download
Focus Mode
Font Size
DLC (Data Lake Compute) supports creating native tables (Iceberg) and external tables in various scenarios. For Table creation, refer to the following practice cases.
Create Native Table (Iceberg)
Spark ETL Scenarios
Applicable to: Periodically perform batch job operations such as insert into, insert overwrite, merge into, etc.
/**Copy-on-write is the default mode. If it cannot be determined which one of the two modes is used, the copy-on-write mode can be used. The merge-on-read mode has better performance in row-level update scenarios.Applicable scenarios of copy-on-write: Featuring relatively higher query performance but relatively slower writing speed, copy-on-write is suitable for scenarios that have periodic ETL tasks or batch update operations with a large data volume.Applicable scenarios of merge-on-read: Featuring relatively lower query performance but relatively faster writing speed, merge-on-read is suitable for scenarios with high write performance requirements. It has strong row-level update capabilities and significantly improves the write performance for frequent and small-scale (< 10%) merge-into/update/delete operations or Oceanus (Flink stream writing) scenarios*//** Copy-on-write table */CREATE TABLE dlc_db.iceberg_etl (id INT,name string,age INT) TBLPROPERTIES ('format-version' = '2','write.metadata.previous-versions-max' = '100','write.metadata.delete-after-commit.enabled' = 'true');/** merge on read table */CREATE TABLE dlc_db.iceberg_etl (id INT,name string,age INT) TBLPROPERTIES ('format-version' = '2','write.metadata.previous-versions-max' = '100','write.metadata.delete-after-commit.enabled' = 'true','write.update.mode' = 'merge-on-read','write.merge.mode' = 'merge-on-read','write.delete.mode' = 'merge-on-read');
Console Creation: Copy-On-Write Mode
1. lick to create native tables.
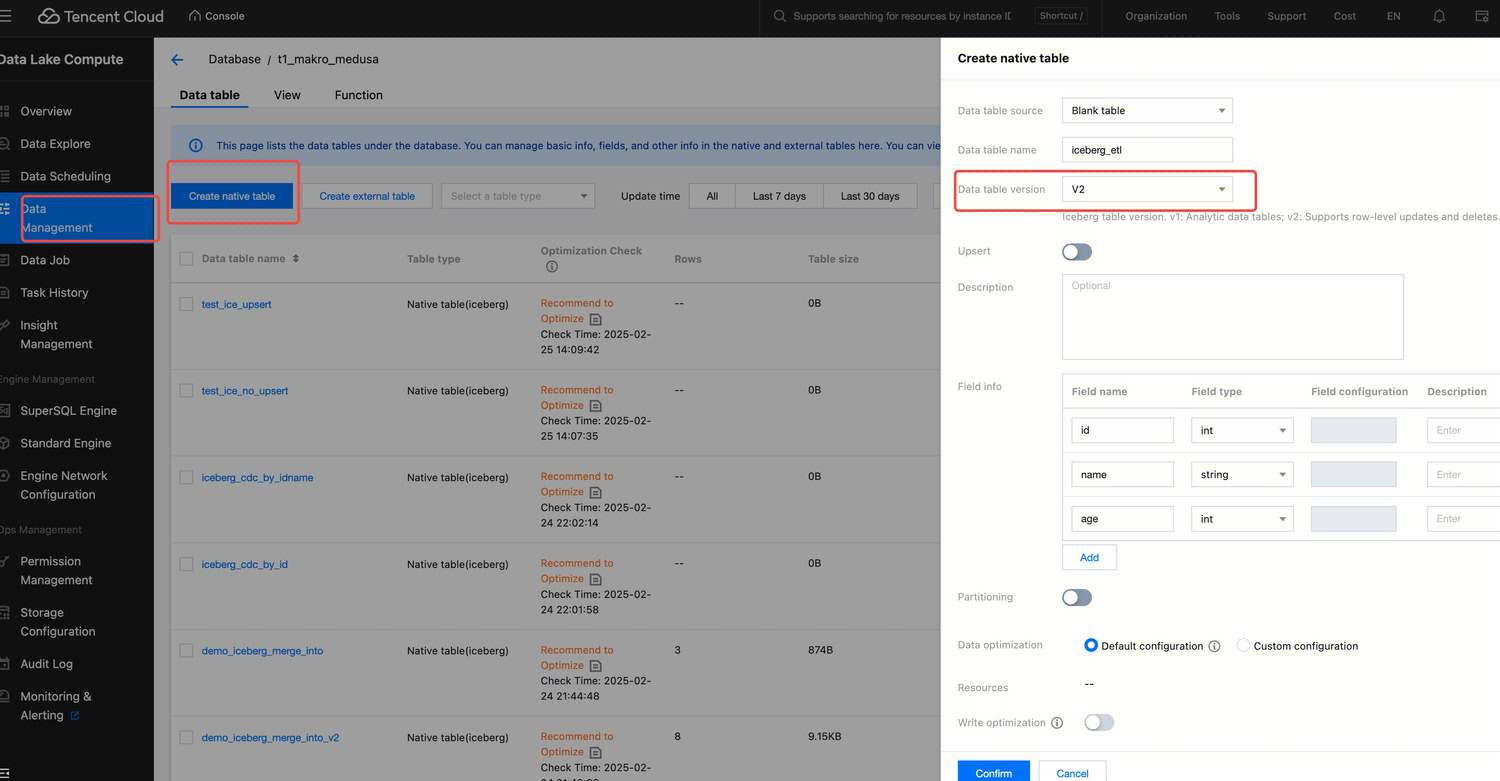
2. Select the data table version.
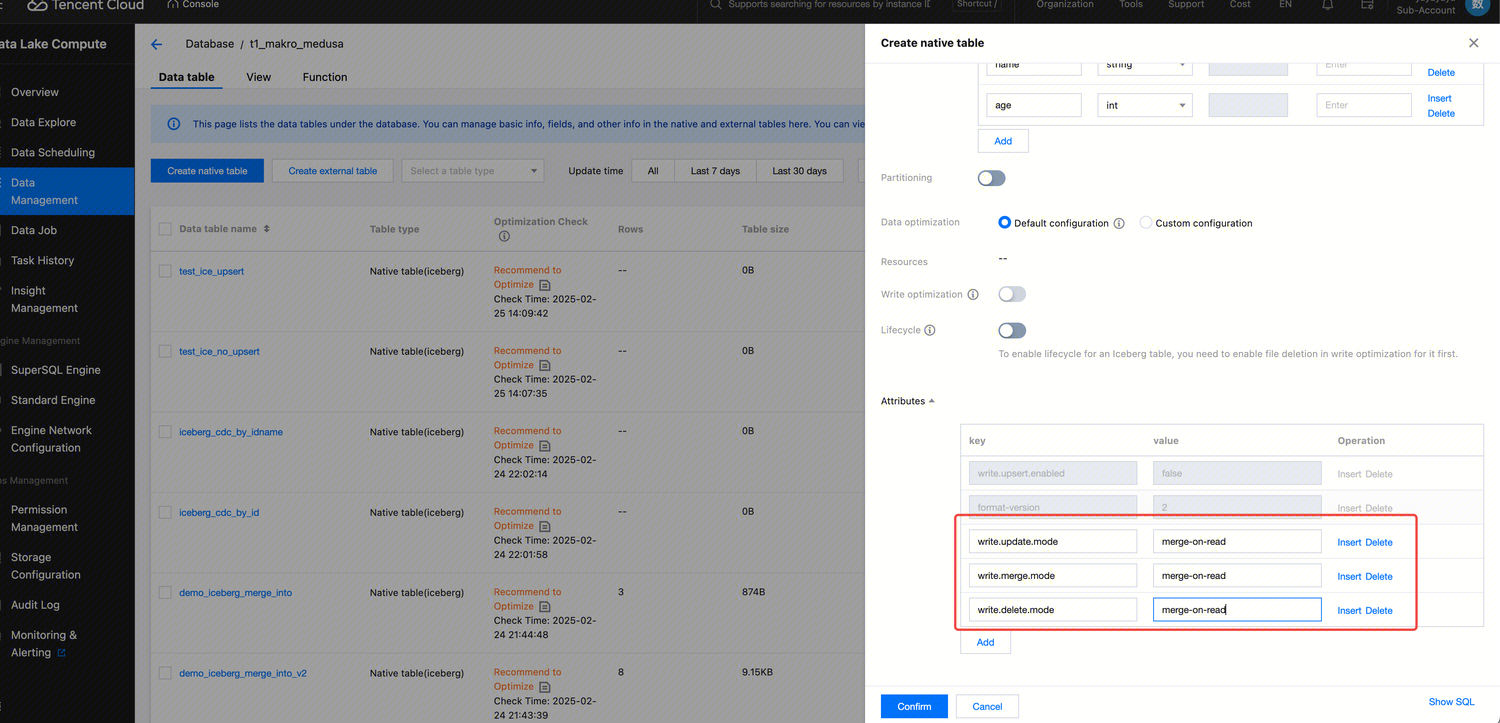
Console Creation: Merge-On-Read Mode (Requires Adding Three Additional Attribute Values)
Flink Stream Writing Scenarios
Suitable for Oceanus (Flink stream writing) scenarios.
/** The Flink stream writing primary key is the ID */CREATE TABLE dlc_db.iceberg_cdc_by_id (id INT,name string,age INT) TBLPROPERTIES ('format-version' = '2','write.metadata.previous-versions-max' = '100','write.metadata.delete-after-commit.enabled' = 'true','write.upsert.enabled' = 'true','write.update.mode' = 'merge-on-read','write.merge.mode' = 'merge-on-read','write.delete.mode' = 'merge-on-read','write.distribution-mode' = 'hash','write.parquet.bloom-filter-enabled.column.id' = 'true','dlc.ao.data.govern.sorted.keys' = 'id');/** The Flink stream writing primary key is a composite primary key of ID and name */CREATE TABLE dlc_db.iceberg_cdc_by_id_and_name (id INT,name string,age INT) TBLPROPERTIES ('format-version' = '2','write.metadata.previous-versions-max' = '100','write.metadata.delete-after-commit.enabled' = 'true','write.upsert.enabled' = 'true','write.update.mode' = 'merge-on-read','write.merge.mode' = 'merge-on-read','write.delete.mode' = 'merge-on-read','write.distribution-mode' = 'hash','write.parquet.bloom-filter-enabled.column.id' = 'true','write.parquet.bloom-filter-enabled.column.name' = 'true','dlc.ao.data.govern.sorted.keys' = 'id,name');
Create a table with the primary key of ID in the console.
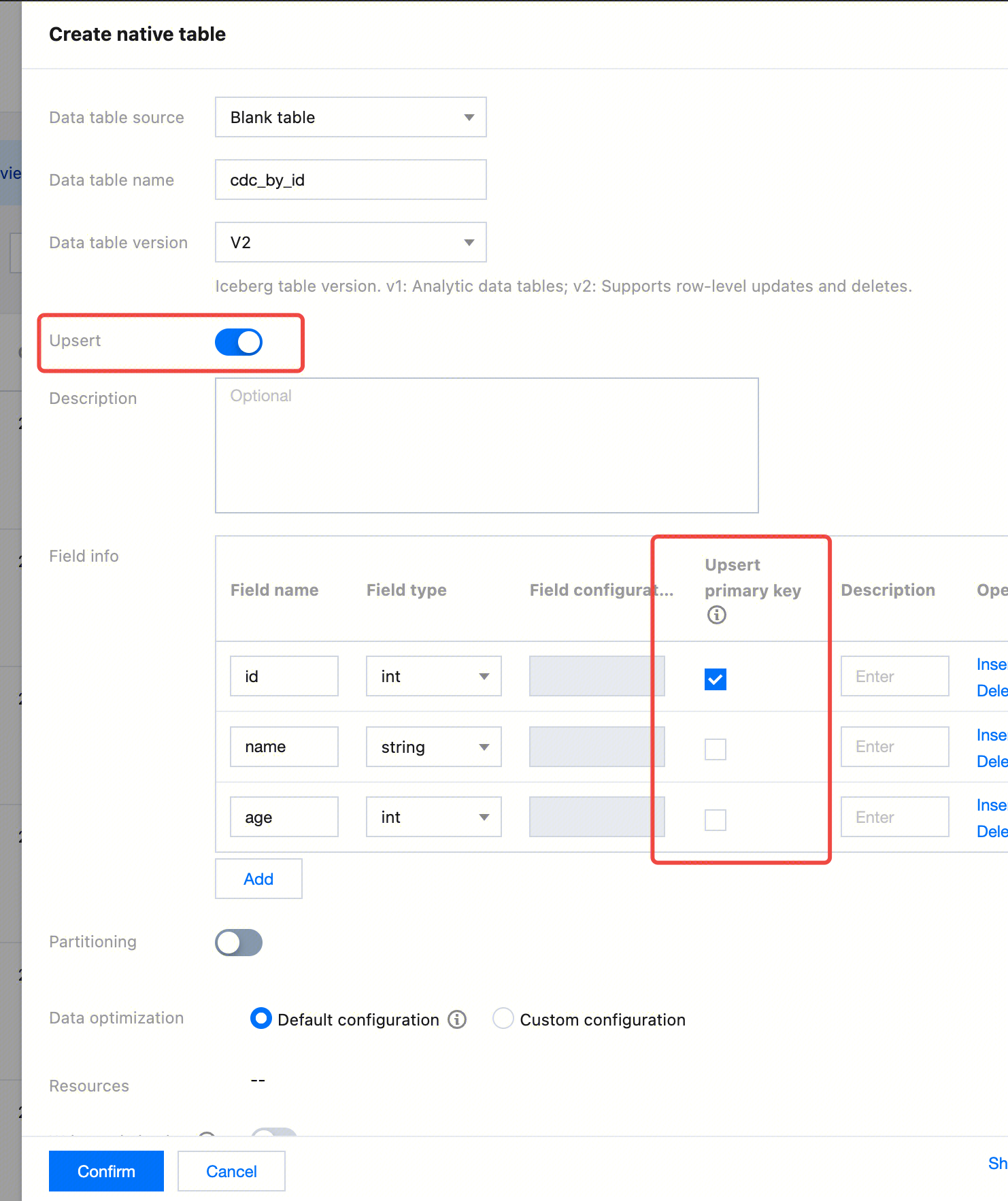
Configuration Instructions
Attribute Value | Description | Configuration Guidance |
format-version | Iceberg table version. The values include 1 and 2. The default value is 2 for Spark Standard-S 1.1 and SuperSQL Spark 3.5 and 1 for other scenarios. | It is recommended that it be set to 2. |
write.upsert.enabled | Specifies whether to enable upsert. The value is true. If it is not specified, upsert is not enabled. | If upsert is involved in a writing scenario, it should be set to true. |
write.update.mode | Update mode | The default value is copy-on-write. Copy-on-write is the default mode. If it cannot be determined which one of the two modes is used, the copy-on-write mode can be used. The merge-on-read mode has better performance in row-level update scenarios. Applicable scenarios of copy-on-write: Featuring relatively higher query performance but relatively slower writing speed, copy-on-write is suitable for scenarios that have periodic ETL tasks or batch update operations with a large data volume. Applicable scenarios of merge-on-read: Featuring relatively lower query performance but relatively faster writing speed, merge-on-read is suitable for scenarios with high write performance requirements. It has strong row-level update capabilities and significantly improves the write performance for frequent and small-scale (< 10%) merge-into/update/delete operations or Oceanus (Flink stream writing) scenarios. |
write.merge.mode | Merge mode | The default value is copy-on-write. Copy-on-write is the default mode. If it cannot be determined which one of the two modes is used, the copy-on-write mode can be used. The merge-on-read mode has better performance in row-level update scenarios. Applicable scenarios of copy-on-write: Featuring relatively higher query performance but relatively slower writing speed, copy-on-write is suitable for scenarios that have periodic ETL tasks or batch update operations with a large data volume. Applicable scenarios of merge-on-read: Featuring relatively lower query performance but relatively faster writing speed, merge-on-read is suitable for scenarios with high write performance requirements. It has strong row-level update capabilities and significantly improves the write performance for frequent and small-scale (< 10%) merge-into/update/delete operations or Oceanus (Flink stream writing) scenarios. |
write.parquet.bloom-filter-enabled.column.{col} | Specifies whether to enable bloom. It is only suitable for Oceanus (Flink stream writing) scenarios. The value true indicates that it is enabled, and it is not enabled by default. | For Flink stream writing scenarios, it should be enabled and configured based on the upstream primary key. If there are multiple primary keys in the upstream, the first two (at most) primary keys are used. After it is enabled, the MOR query and small file merge performance can be improved. |
write.distribution-mode | Write mode | When it is set to hash, written data is repartitioned automatically. However, the write performance is affected for some write situations. It is recommended that it is not configured by default. For Oceanus (Flink stream writing) scenarios, it is recommended that it be set to hash to optimize the write performance. For other scenarios, it is recommended that the default value be retained, that is, it is not configured. |
write.metadata.delete-after-commit.enabled | Starts auto cleanup of metadata files. | It is strongly recommended that it be set to true. After it is enabled, Iceberg automatically cleans historical metadata files when generating snapshots, which prevents the accumulation of a large number of metadata files. |
write.metadata.previous-versions-max | Sets the default number of metadata files to be retained. | The default value is 100. In some special cases, users can appropriately adjust this value. It needs to be used together with write.metadata.delete-after-commit.enabled. |
Create External Table
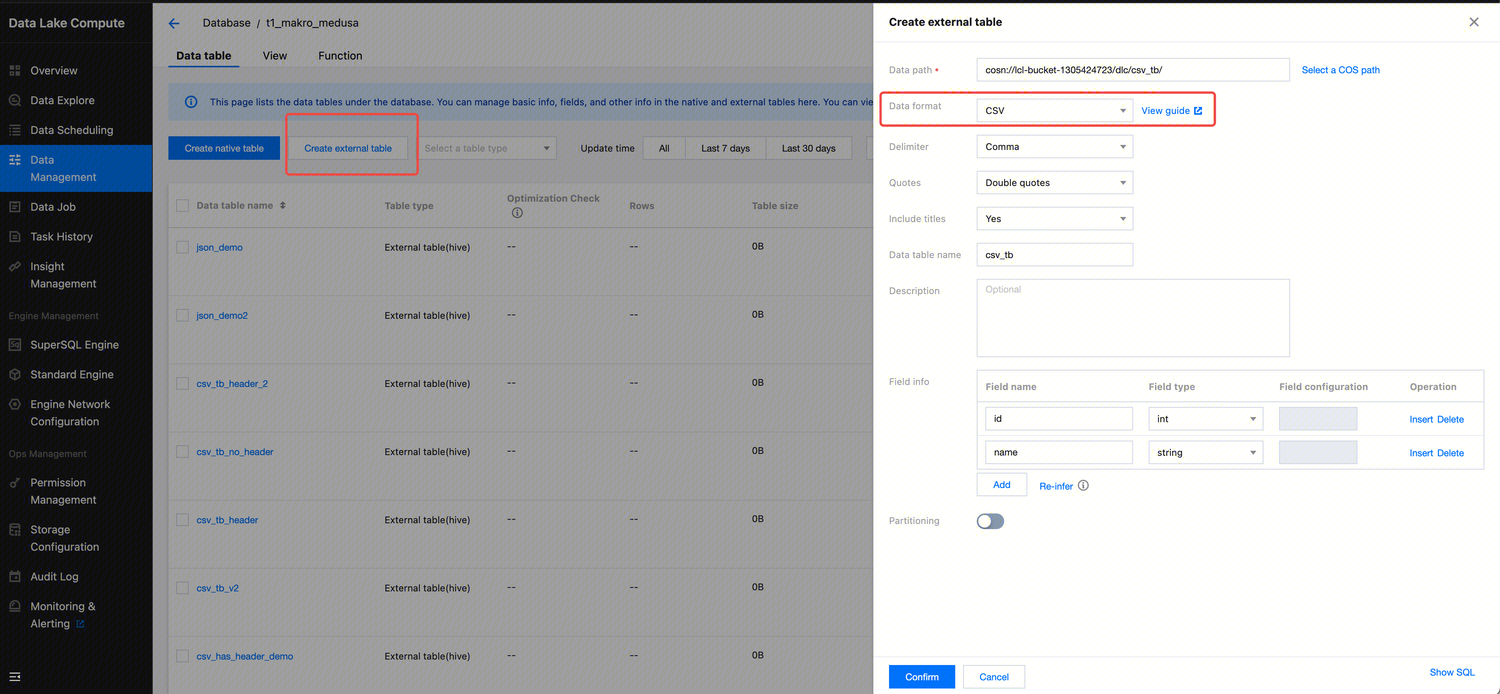
Creating a CSV Format External Table
/**1. separatorChar: Separator, which is a comma (,) by default. It is used to specify the separator between fields in a CSV file, helping Hive correctly parse the fields in each row.2. quoteChar: Quote character, which are quotation marks (") by default. If the original file does not have a quote character, the default value can be used. The quote character helps process fields that contain separators (such as commas) or line breaks. For example, if the value x1,x2 of the column1 field is surrounded by quotation marks "x1,x2", it will not be incorrectly parsed as two separate fields.3. LOCATION: It needs to be changed to the COS storage path.4. Table attribute skip.header.line.count in TBLPROPERTIES: The default value is 0. When it is set to 1, one row is skipped. This attribute specifies the number of header rows to skip when a file is read because the headers of many CSV files usually contain column names instead of actual data.*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.`csv_tb`(`id` int,`name` string)ROW FORMAT SERDE'org.apache.hadoop.hive.serde2.OpenCSVSerde'WITH SERDEPROPERTIES ('quoteChar'='"','separatorChar'=',')STORED AS INPUTFORMAT'org.apache.hadoop.mapred.TextInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION'cosn://your_cos_location'TBLPROPERTIES ('skip.header.line.count'='1');
Creating a Json Format External Table
/**LOCATION: Refers to the COS storage path.Others remain unchanged.*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.json_demo(`id` bigint, `name` string)ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'STORED AS TEXTFILELOCATION 'cosn://your_cos_location'
Example of JSON file content. Each line is an independent JSON string:
{"id":1,"name":"tom"}{"id":2,"name":"tony"}
Creating an External Table in Parquet Format
The SQL statements for table creation are as follows:
/**LOCATION: Refers to the COS storage path.Others remain unchanged.*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.parquet_demo(`id` int, `name` string)PARTITIONED BY (`dt` string)STORED AS PARQUET LOCATION 'cosn://your_cos_location';
Creating an ORC Format External Table
/**LOCATION: Refers to the COS storage path.Others remain unchanged.*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.orc_demo(`id` int,`name` string)PARTITIONED BY (`dt` string)STORED AS ORC LOCATION 'cosn://your_cos_location'
Creating an External Table in AVRO Format
/**LOCATION: Refers to the COS storage path.Others remain unchanged.*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.avro_demo(`id` int,`name` string)PARTITIONED BY (`dt` string)STORED AS ORC LOCATION 'cosn://your_cos_location'
Supplementary Description
Column Types and Partition Field Types
Note:
When a SELECT query statement is executed to query binary fields, the following error may occur because the engine writes the result set to a CSV file by default, which does not support binary data.

Solution (engine or task-level configuration are all supported):
1. Change the results file format for saving: kyuubi.operation.result.saveToFile.format=parquet (Set the format of the stored file, Parquet or ORC.)
2. Change the configuration to save the results to another place other than COS: kyuubi.operation.result.saveToFile.enabled=false
Complex Column Types
/**LOCATION: Refers to the COS storage path.Others remain unchanged.*/CREATE EXTERNAL TABLE dlc_db.orc_demo_with_complex_type(col_bigint bigint COMMENT 'id number',col_int int,col_struct struct<x: double, y: double>,col_array array<struct<x: double, y: double>>,col_map map<struct<x: int>, struct<a: int>>,col_decimal DECIMAL(10,2),col_float FLOAT,col_double DOUBLE,col_string STRING,col_boolean BOOLEAN,col_date DATE,col_timestamp TIMESTAMP)PARTITIONED BY (`dt` string)STORED AS ORC LOCATION 'cosn://your_cos_location';
Note:
1. AVRO data sources do not support nested struct fields to map or array fields.
2. The key of map fields in an AVRO data source can only be string type.
3. When struct, array, or map fields are used in a CSV data source, the following error may occur because the engine performs strong verification on the data format.
Disable strong verification settings of the engine and set the static parameter of the engine with spark.sql.storeAssignmentPolicy=legacy.
Complex Partition Field Types
1. LOCATION: It needs to be changed to the COS storage path.
2. Supported partition field types include TINYINT, SMALLINT, INT, BIGINT, DECIMAL, FLOAT (not recommended, and DECIMAL is recommended ), DOUBLE (not recommended, and DECIMAL is recommended ), STRING, BOOLEAN, DATE, and TIMESTAMP.
CREATE EXTERNAL TABLE dlc_db.orc_demo_with_complex_partition(col_int int)PARTITIONED BY (pt_tinyint TINYINT,pt_smallint SMALLINT,pt_decimal DECIMAL(10,2),pt_string STRING,pt_date DATE,pt_timestamp TIMESTAMP )STORED AS ORC LOCATION 'cosn://lcl-bucket-1305424723/dlc/orc_demo_with_complex_partition/';
Note:
The sum of Hive table partition names cannot exceed 767 characters.
Case-insensitive Metadata
Table names and column names in metadata are case-insensitive when they are used. However, the original case format during creation is retained on the Data Management page.
Help and Support
Was this page helpful?
You can also Contact sales or Submit a Ticket for help.
Help us improve! Rate your documentation experience in 5 mins.
Feedback