2. On the left side, select TKE Insight > Node Map.
3. On the Node Map page, hover over the mouse on a Node at the bottom of the page and click Details.
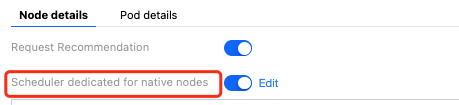
4. In the top right corner of the detail page for this node, enable the "Native Node-specific Scheduler" function.
Note:
This capability is a global one, meaning it only needs to be enabled once for a cluster. The functions in other node detail pages will be enabled/disabled synchronously. This component is only effective for the Native Node. If the native node resources are insufficient, it can easily lead to Pod Pending.
Using the Native Node-specific Scheduler
Setting the Node Amplification Factor and the Threshold
2. On the left sidebar, select TKE Insight > Node Map.
3. On the Node Map page, hover over the mouse on a native node that needs amplification at the bottom of the page, and click Details.
4. In the top right corner of the detail page for this node, click Edit on the right of the native node-specific scheduler.
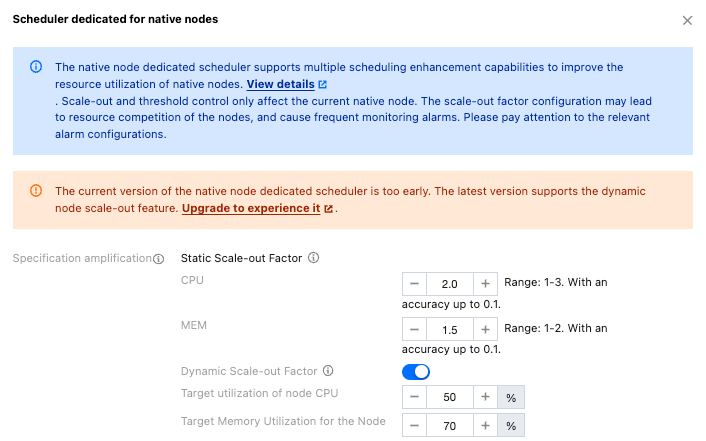
5. On the editing page of the Native Node-specific Scheduler, set the node amplification factor and the threshold, as shown below:
Field Name
Description
Specification amplification
Virtually amplifies the native node specifications to schedule more Pods, allowing the current node packing rate to exceed 100%.
Note:
The current node specification amplification only virtually amplifies the current Native Node specifications. This feature carries certain risks: if too many Pods are scheduled on a node and the total actual resource usage of Pods exceeds the node specifications, it will trigger Pod evicting and rescheduling.
Static amplification factor - CPU
Supports the entering of numbers between 1 and 3, keeping one decimal place.
Static amplification factor - Memory
Supports the entering of numbers between 1 and 2, keeping one decimal place.
Scheduling threshold control
Sets the target resource utilization for the current native node to ensure stability. When scheduling Pods, nodes with a utilization above this threshold will not be selected.
The scheduling threshold is also a default for:
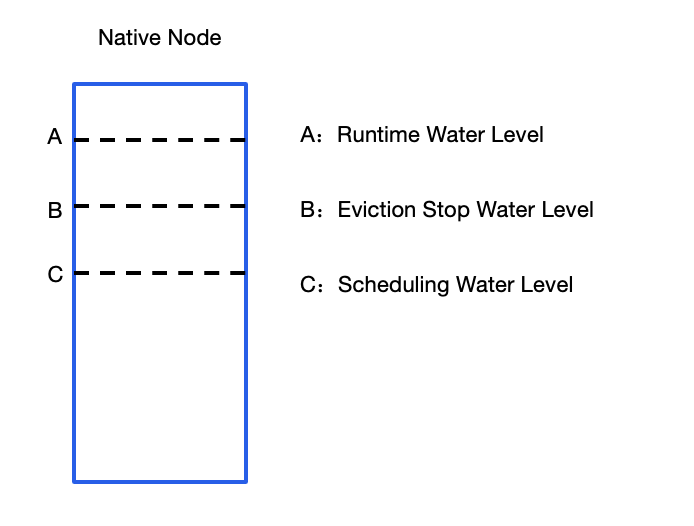
1. The evicting stop threshold: When the node utilization reaches the runtime threshold and evicting occurs, it will be evicted to the target threshold.
For example: If the runtime threshold is 80 and the scheduling threshold is 60, start evicting after the node utilization reaches 80. Pods are evicted in sequence based on the utilization of Pods that can be evicted until the threshold is below 60.
2. Low-load node threshold: When the node utilization reaches the runtime threshold and evicting occurs, it needs to be checked whether the utilization of At Least Three Native Nodes is lower than the Scheduling Threshold of these nodes.
For example: If there are 5 native nodes, each with a runtime threshold of 80 and a scheduling threshold of 60, then when the node utilization reaches 80, it starts to check for evicting. To find the low-load native nodes that can accommodate Pods, at least three native nodes shall have the utilization lower than 60.
Note:
If different native nodes have different scheduling thresholds, it is necessary to check the utilization and scheduling threshold of the specific native node.
Target CPU utilization during scheduling
Supports the entering of integers between 0 and 100.
Target memory utilization during scheduling
Supports the entering of integers between 0 and 100.
Runtime threshold control
Sets the target resource utilization for the current native node to ensure stability. When the node is running, nodes with the utilization above this threshold may trigger evicting, provided that the tag indicating the evicting status is specified on the designated workload.
Note:
1. Business Pods are not evicted by default. To avoid evicting critical Pods, this feature does not evict Pods by default. For Pods that can be evicted, users need to indicate on the workloads of such Pods, then the component will perform evicting when the threshold is triggered. For example, set the evictable annotation of:descheduler.alpha.kubernetes.io/evictable: 'true' for the objects of statefulset and deployment.
2. The eviction can occur only when there are enough low-load nodes. To ensure that the Pods have a node to accommodate after the eviction, the scheduler requires the utilization of At Least Three Native Nodes to be below the Scheduling Threshold of these nodes. Therefore, if there are many native nodes in the cluster, but fewer than three native nodes have the threshold enabled, or fewer than three native nodes are below the Scheduling threshold, the eviction cannot be performed.
Runtime target CPU utilization
Supports the entering of integers between 0 and 100. Note: The runtime target CPU utilization shall be greater than the scheduling target CPU utilization.
Runtime target memory utilization
Supports the entering of integers between 0 and 100. Note: The runtime target memory utilization shall be greater than the scheduling target memory utilization.
Eviction-stop threshold control
Starting from v1.4.0 and later for the native node scheduler, the eviction-stop threshold can be visually configured via the console. This means that, when a node is under a high load, it will continuously evict the Pods until the eviction-stop threshold is reached.
Eviction-stop target CPU utilization
Supports the entering of integers between 0 and 100. Note: The runtime target CPU utilization shall be greater than the scheduling target CPU utilization.
Eviction-stop target memory utilization
Supports the entering of integers between 0 and 100. Note: The runtime target CPU utilization shall be greater than the scheduling target CPU utilization.
Description of Node Dynamic Amplification Capability
To address stability issues caused by overly aggressive configuration factor configuration by customers and to prevent mindless node amplification, the smaller value of the target node utilization/current node utilization and the static amplification rate will be selected as the dynamic amplification factor. The native node scheduler of v1.4.0 and later supports the dynamic amplification capability, which can be enabled as needed.
Configuration of Node Dynamic Amplification
On the editing page of the native node-specific scheduler, enable dynamic amplification, and set the target CPU and memory utilization for the node.
Calculation Methods for Node Dynamic Amplification
1. Complete the configuration for the node static amplification factor maxRatio and the dynamic amplification factor target utilization targetUsage.
2. Obtain the node peak utilization maxUsage for the recent 7 days.
3. The dynamic amplification factor is the smaller value of targetUsage/maxUsage and maxRatio.
4. To ensure cluster stability, the dynamic amplification factor shall be greater than the actual packing rate of the node currently.
Enabling Load-Awareness Scheduling
To address the issue where non-CNRP selected native nodes do not have any pod scheduling, the native node scheduler of v1.5.0 and later supports the enabling of load-awareness scheduling. Once enabled, all native nodes in the cluster will be scheduled based on the load awareness. Even if a node is not managed by CNRP, it can still be scheduled based on the actual load. This feature is disabled by default and can be manually enabled in the console.
Note:
Enabling the load-awareness scheduling does not affect the inventory. This feature is only available for the public cloud clusters.
Enabling Pod Usage Deduction Scheduling
To ensure the stability of cluster scheduling and to avoid the scheduling of high-request Pods for nodes close to the scheduling threshold, the native node scheduler of version 1.3 and later supports the "Pod usage deduction" scheduling. Once enabled, the resource usage of Pods will be deducted during the pre-selection and preferential selection stages of the scheduler, calculating whether it meets the pre-selection rules, and participating in the preferential scoring.
The method for calculating the Pod resource usage is as follows:
1. If the cluster has Request Intelligent Recommendation enabled and the Pod already has a recommended value, the load will be directly deducted based on this recommended value.
2. If there is no recommended value for the workload of the Pod, the deduction will be performed based on the request value set for the Pod.
3. If the Pod itself does not have a recommended value configured, the deduction will be performed based on CPU:100m and Mem:200Mi by default.
Setting the Scheduling of Pods in the Specified Namespace to Native Nodes
In addition to setting the amplification factor and the threshold control parameters on the current native nodes, the native node-specific scheduler also supports the scheduling of Pods from a specified namespace to native nodes. This helps users automate Pod migration and fully utilize the advantages of native nodes. The steps are as follows:
2. On the Cluster Management page, click the target cluster ID to enter the page of cluster details.
3. Select Component Management. On the component list page, select "cranescheduler (native node-specific scheduler)", and click Update Configuration.
4. Select the namespace. Pods in the specified namespace can only be scheduled to the native nodes. If the Native Node has insufficient resources, it will cause Pod Pending.
Description of Node Specification Amplification Capability
If the CPU and memory amplification factors of the nodes are specified, you can view the annotation of: expansion.scheduling.crane.io/cpu and expansion.scheduling.crane.io/memory related to the amplification factors on the native nodes. An example is as follows:
kubectl describe node10.8.22.108
...
Annotations: expansion.scheduling.crane.io/cpu: 1.5# CPU amplification factor
cpu: 1930m # Original schedulable resource amount of the node
ephemeral-storage: 47498714648
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 1333120Ki
pods: 253
...
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 960m (49%) 8100m (419%)# Occupancy of Request and Limit for this node
memory 644465536(47%)7791050368(570%)
ephemeral-storage 0(0%)0(0%)
hugepages-1Gi 0(0%)0(0%)
hugepages-2Mi 0(0%)0(0%)
...
Note:
Original CPU schedulable amount of current node: 1930m
Total CPU Request application volume of all Pods on the node: 960m
Under normal circumstances, this node can only schedule up to 1930m-960m=970m CPUs.
But in reality, the CPU schedulable amount of this node has been virtually amplified to: 1930m*1.5=2895m, and the actual remaining CPU schedulable resource is: 2895-960=1935m.
At this time, create a workload with only one Pod, the CPU application volume is 1500m. If there is no node amplification capability, this node cannot be scheduled to.
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: default
name: test-scheduler
labels:
app: nginx
spec:
replicas:1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
nodeSelector:# Specify node scheduling
kubernetes.io/hostname: 10.8.20.108 # Specify the use of native nodes in the example
containers:
-name: nginx
image: nginx:1.14.2
resources:
requests:
cpu: 1500m # The application node is greater than the schedulable amount before amplification but less than the schedulable amount after amplification.
ports:
-containerPort:80
The workload is successfully created:
kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
test-scheduler 1/1 11 2m32s
Check the resource occupancy of the node again:
kubectl describe node10.8.22.108
...
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 2460m (127%) 8100m (419%)# Occupancy of Request and Limit for this node. It can be seen that, the total Request exceeds the original schedulable amount. The node specification is successfully amplified.
memory 644465536(47%)7791050368(570%)
ephemeral-storage 0(0%)0(0%)
hugepages-1Gi 0(0%)0(0%)
hugepages-2Mi 0(0%)0(0%)
Custom Setting of Node Amplification Factor and Threshold
Note:
The custom setting of the node amplification factor and the threshold has high flexibility. You can select a node, a node pool, a batch of nodes or node pools, or even configure the same node specification amplification factor and threshold for the entire cluster.
You can create multiple configuration files to apply to different nodes. If a node is declared by multiple configuration files and the declared parameters declared in different files are different, only the latest created configuration file will take effect.
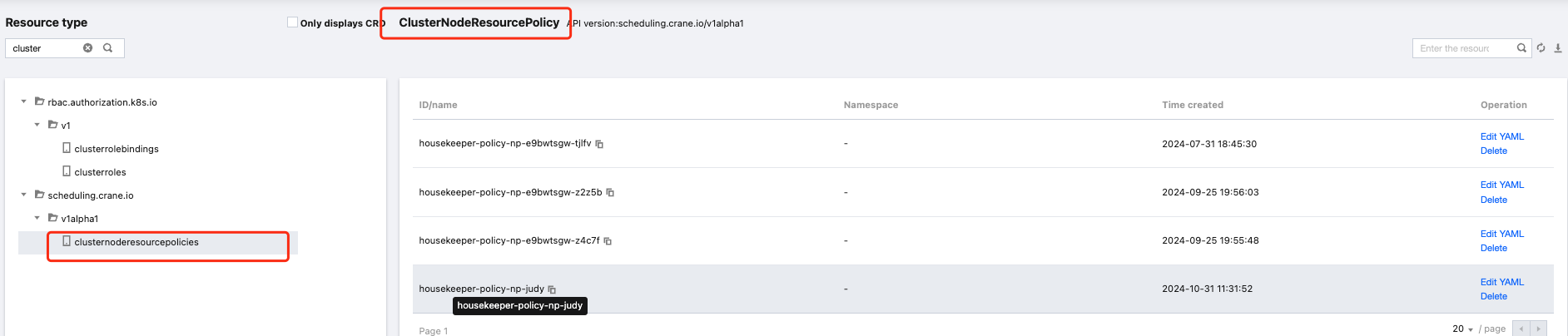
In addition to the console operation, the parameters of the native node-specific scheduler also support the configuration through YAML. Each configuration file is saved in a resource object named clusternoderesourcepolicies (CNRP). You can directly create this type of resource object:
apiVersion: scheduling.crane.io/v1alpha1
kind: ClusterNodeResourcePolicy
metadata:
name: housekeeper-policy-np-88888888-55555# name cannot be duplicated.
spec:
applyMode: annotation # Default value. Other values are not supported for now.
nodeSelector:# It is used to select a group of nodes with the same configuration. For example, below is used to select a native node with the ID of np-88888888-55555. You can also use a common tag for a batch of nodes to achieve batch selection of nodes.
# evictLoadThreshold is the runtime threshold control of native nodes. It is used for setting the eviction resource utilization for the current batch of native nodes to ensure stability. When the Pods run on native nodes, the native nodes above this threshold may be evicted. To avoid evicting critical Pods, this feature does not evict Pods by default. For Pods that can be evicted, users need to explicitly judge the workload of the Pod. For example, set the evictable annotation of: descheduler.alpha.kubernetes.io/evictable: 'true' for the objects of statefulset and deployment.
# evictLoadThreshold shall be greater than targetLoadThreshold, otherwise the node may be continuously scheduled with new Pods after eviction to cause jitter.
evictLoadThreshold:
percents:
cpu:80
memory:80
resourceExpansionStrategyType: static # default value. Other values are not supported for now.
staticResourceExpansion:
ratios:# Node specification amplification factor. It is used for setting the amplification factor for the current batch of native nodes.
cpu:"3"# The amplification factor of the node CPU. It is recommended not to set it too high, otherwise it may cause stability risks. The maximum value is limited to 3 in the console.
memory:"2"# The amplification factor of the node memory. It is recommended not to set it too high, otherwise it may cause stability risks. The maximum value is limited to 2 in the console.
# targetLoadThreshold is the scheduling threshold control of native nodes. It is used for setting the amplification factor for the current batch of native nodes to ensure stability. Native nodes above this threshold will not be selected during Pod scheduling.
# targetLoadThreshold shall be less than evictLoadThreshold, otherwise the node may be continuously scheduled with new Pods after eviction to cause jitter.
targetLoadThreshold:
percents:
cpu:70
memory:70
You can modify or create this type of resource object. As shown below, you can view the inventory of clusternoderesourcepolicies (CNRP) in the console.
1. Log in to the Tencent Kubernetes Engine console, and select Cluster in the left sidebar.
2. Click the cluster ID of the native node-specific scheduler to be viewed, and enter the resource object browser page. Search for clusternoderesourcepolicies (CNRP) in the top-left box, as shown below:
If you configure the scheduling parameters for native nodes via the console page, these files will be designated as: housekeeper-policy-np-88888888-55555, wherein np-88888888 is the node pool ID of this native node, and np-88888888-55555 is the node ID of this native node.
Setting Node Dynamic Amplification
The native node scheduler of v1.4.0 and later supports node dynamic amplification. The parameters can also be configured via the backend YAML. The corresponding ClusterNodeResourcePolicy example is as follows:
apiVersion: scheduling.crane.io/v1alpha1
kind: ClusterNodeResourcePolicy
metadata:
name: housekeeper-policy-np-88888888-55555# name cannot be duplicated.
spec:
applyMode: annotation # Default value. Other values are not supported for now.
nodeSelector:# It is used to select a group of nodes with the same configuration. For example, below is used to select a native node with the ID of np-88888888-55555. You can also use a common tag for a batch of nodes to achieve batch selection of nodes.
resourceExpansionStrategyType: auto # Enable node dynamic amplification
autoResourceExpansion:
crontab: 0 * * * 0-6
decayLife: 168h
# Setting Specific Parameters for Node Dynamic Amplification
maxRatios:
cpu:"2"
memory:"1.5"
minRatios:
cpu:"1.0"
memory:"1.0"
targetLoadThreshold:
percents:
cpu:50
memory:70
# evictLoadThreshold is the runtime threshold control of native nodes. It is used for setting the eviction resource utilization for the current batch of native nodes to ensure stability. When Pods run on native nodes, native nodes above this threshold may be evicted. To avoid evicting critical Pods, this feature does not evict Pods by default. For Pods that can be evicted, users need to explicitly judge the workload of the Pod. For example, set the evictable annotation of: descheduler.alpha.kubernetes.io/evictable: 'true' for the objects of statefulset and deployment.
# evictLoadThreshold shall be greater than targetLoadThreshold, otherwise the node may be continuously scheduled with new Pods after eviction to cause jitter.
evictLoadThreshold:
percents:
cpu:80
memory:80
# targetLoadThreshold is the scheduling threshold control of native nodes. It is used for setting the current target resource utilization of these native nodes to ensure stability. Native nodes above this threshold will not be selected during Pod scheduling.
# targetLoadThreshold shall be less than evictLoadThreshold, otherwise the node may be continuously scheduled with new Pods after eviction to cause jitter.
targetLoadThreshold:
percents:
cpu:70
memory:70
Custom Eviction-Stop Threshold
As mentioned above, there are two additional features of: Eviction-stop threshold and low-load node threshold for the current scheduling threshold. However, this design leads to feature binding issues, for example:
1. If users want to evict fewer Pods during business eviction, they need to raise the scheduling threshold, which will result in more Pods being scheduled on the node, increasing the probability of eviction. Additionally, since fewer Pods are evicted, the node may experience frequent scheduling and eviction, increasing node instability.
2. If users want to evict more Pods during business eviction, they need to reduce the scheduling threshold, which will result in fewer Pods being scheduled on the node, decreasing the probability of eviction. Since more Pods are evicted, the possible utilization of the node will change dramatically, and the node instability will also be increased. Additionally, since the scheduling threshold is lower, the utilization cannot be improved, leading to significant resource waste.
Therefore, in the new Crane Scheduler, TKE has introduced the third threshold of: the eviction-stop threshold, which has the two additional features of: the eviction-stop threshold and the low-load node threshold for the scheduling threshold.
Note:
This feature requires the version of the Crane Scheduler to be at least 1.1.10. For version details and upgrade information, refer to Documentation.
apiVersion: scheduling.crane.io/v1alpha1
kind: ClusterNodeResourcePolicy
metadata:
name: housekeeper-policy-np-88888888-55555# name cannot be duplicated.
spec:
applyMode: annotation # Default value. Other values are not supported for now.
nodeSelector:# It is used to select a group of nodes with the same configuration. For example, below is used to select a native node with the ID of np-88888888-55555. You can also use a common tag for a batch of nodes to achieve batch selection of nodes.
# evictLoadThreshold is the runtime threshold control of native nodes. It is used for setting the eviction resource utilization for the current batch of native nodes to ensure stability. When Pods run on native nodes, native nodes above this threshold may be evicted. To avoid evicting critical Pods, this feature does not evict Pods by default. For Pods that can be evicted, users need to explicitly judge the workload of the Pod. For example, set the evictable annotation of: descheduler.alpha.kubernetes.io/evictable: 'true' for the objects of statefulset and deployment.
# evictLoadThreshold shall be greater than targetLoadThreshold, otherwise the node may be continuously scheduled with new Pods after eviction to cause jitter.
evictLoadThreshold:
percents:
cpu:80
memory:80
##################
## Eviction Stop Watermark ##
# The value shall be lower than the runtime threshold of evictLoadThreshold.
evictTargetLoadThreshold:
percents:
cpu:75
memory:75
resourceExpansionStrategyType: static # default value. Other values are not supported for now.
staticResourceExpansion:
ratios:# Node specification amplification factor. It is used for setting the amplification factor for the current batch of native nodes.
cpu:"3"# The amplification factor of the node CPU. It is recommended not to set it too high, otherwise it may cause stability risks. The maximum value is limited to 3 in the console.
memory:"2"# The amplification factor of the node memory. It is recommended not to set it too high, otherwise it may cause stability risks. The maximum value is limited to 2 in the console.
# targetLoadThreshold is the scheduling threshold control of native nodes. It is used for setting the current target resource utilization of these native nodes to ensure stability. Native nodes above this threshold will not be selected during Pod scheduling.
# targetLoadThreshold shall be less than evictLoadThreshold, otherwise the node may be continuously scheduled with new Pods after eviction to cause jitter.