Using AIBrix for Multi-Node Distributed Inference on TKE
Download
Focus Mode
Font Size
Overview
AIBrix is an open-source cloud-native large model inference control plane project launched in February 2025. It is specifically designed to optimize the production deployment of large language models (LLMs). As the first full-stack Kubernetes solution deeply integrated with vLLM, it provides multiple core features such as LoRA dynamic loading, multi-node reasoning, heterogeneous GPU scheduling, and distributed KV cache.
Distributed inference refers to the technology of splitting and processing LLM models across multiple nodes or devices. This approach is particularly useful for large models that cannot be accommodated in the memory of a single machine. AIBrix uses Ray as its distributed computing framework, combined with KubeRay to coordinate Ray clusters to implement distributed inference technology.
AIBrix introduced two key APIs for managing RayCluster, namely RayClusterReplicaSet and RayClusterFleet. RayClusterFleet manages RayClusterReplicaSet, and RayClusterReplicaSet manages RayCluster. The relationship among the three is similar to that among the core concepts of Kubernetes, Deployment, ReplicaSet, and Pod. In most cases, users only need to use RayClusterFleet.
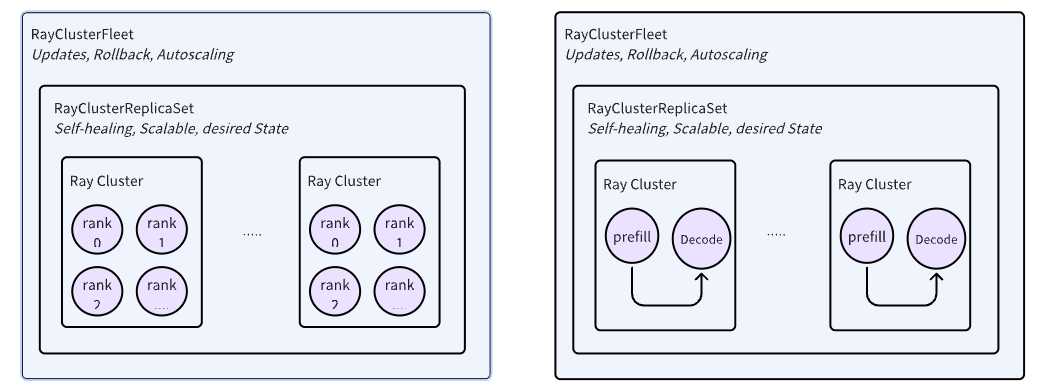
In this document, we will introduce how to use AIBrix for distributed inference on a TKE cluster.
Image Description:
The image used in the example in this document is vllm/vllm-openai, hosted on DockerHub, with a relatively large volume (about 8GB).
In TKE environment, a free DockerHub image acceleration service is provided by default. Therefore, users in the Chinese mainland can directly pull images, but the speed may be slow. It is advisable to synchronize the image to Tencent Container Registry (TCR) to improve the image pull speed and replace the corresponding image address in the YAML file.
Operation Steps
1. Creating a TKE Cluster
Cluster Type: TKE standard cluster.
Kubernetes version: Must be greater than or equal to 1.28 that recommend choose the latest version. (This document uses 1.30)
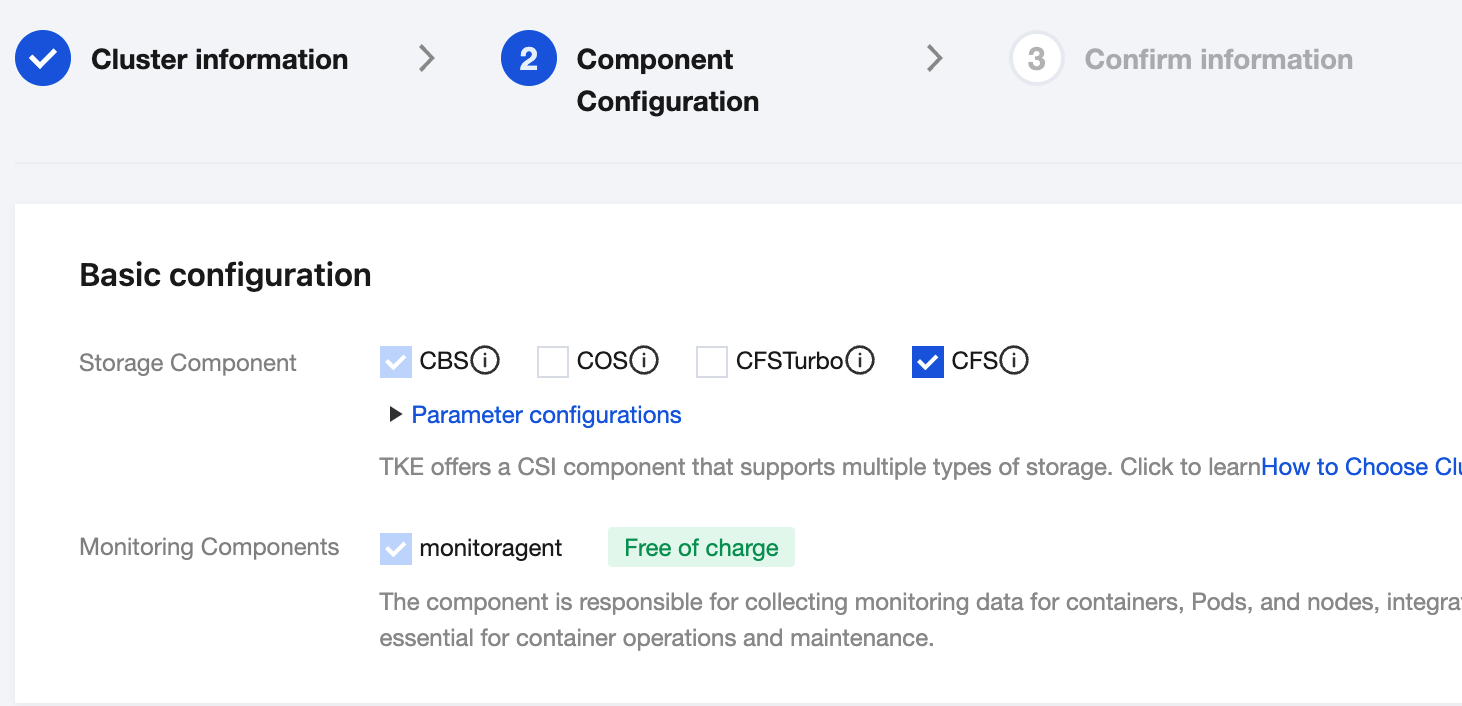
Basic configuration: Select CFS for the storage component, as shown below:
2. Creating a Super Node
In the cluster list, click the cluster ID to enter the cluster details page. Refer to step creating a super node, to create a super node pool.
3. Downloading a Model
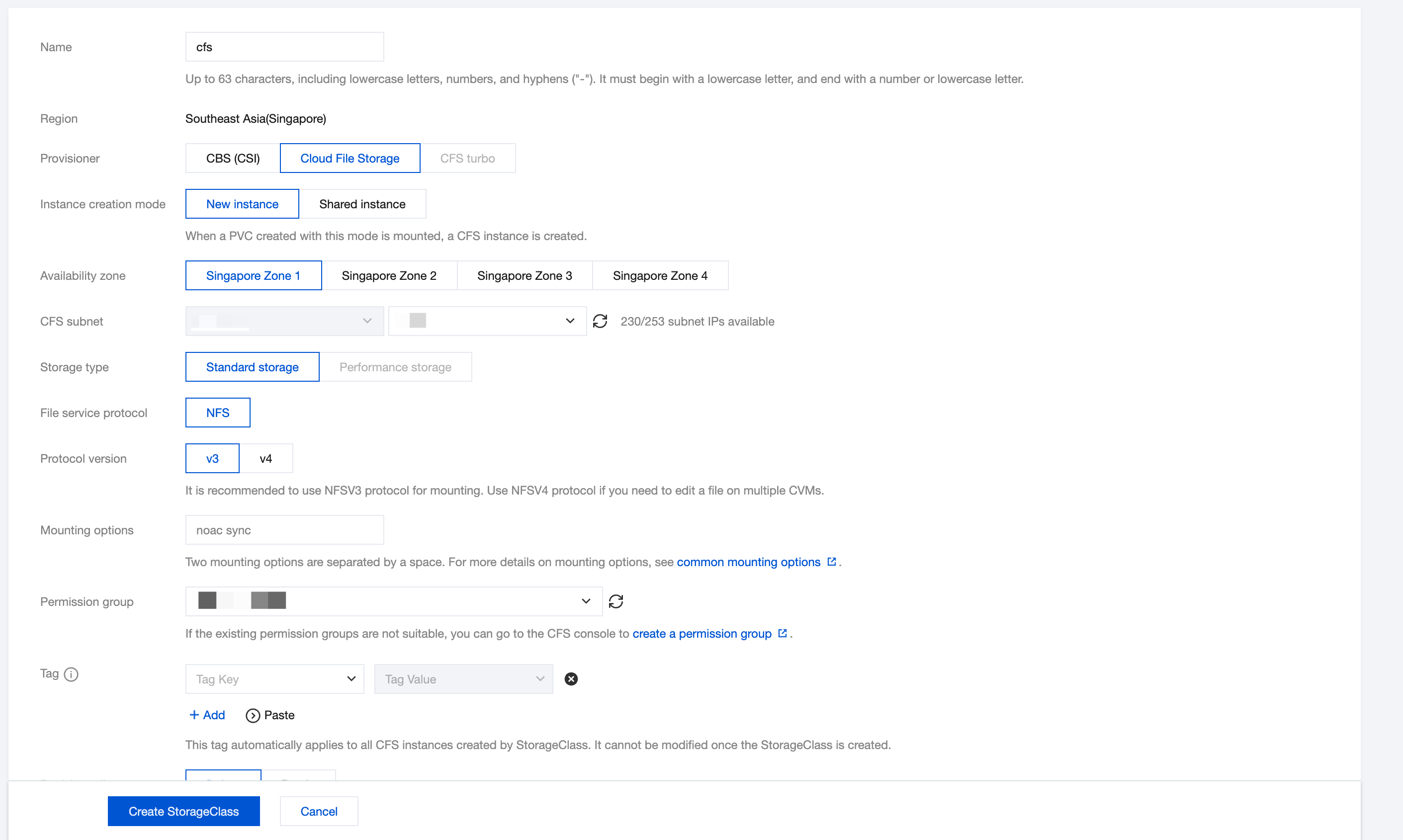
3.1 Creating a StorageClass
Create a StorageClass through the console
1. In the cluster list, click the cluster ID to enter the cluster details page.
2. Select Storage in the left sidebar and click Create on the StorageClass page.
3. On the Create Storage page, create a CFS-type StorageClass according to actual needs. As shown below:
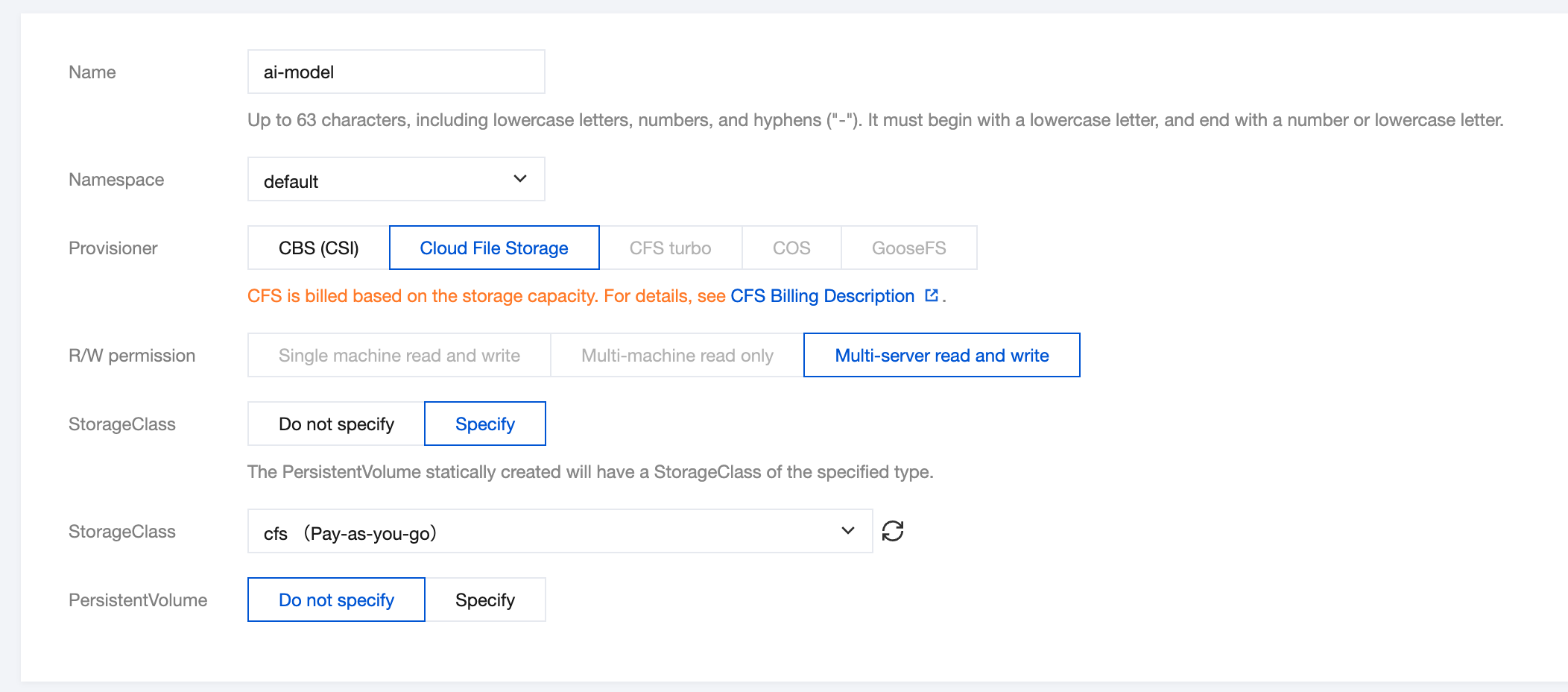
3.2 Create PVC
Create a PVC through the console
1. In the cluster list, click the tke cluster ID to enter the cluster details page.
2. Select Storage in the left sidebar and click Create on the PersistentVolumeClaim page.
3. On the Create Storage page, create a PVC for the storage model file according to actual needs. As shown below:
3.3 Using a Job to Download Model Files
Create a Job used for downloading large model files to CFS.
Notes:
The model used in the example in this document is the 7B version of Qwen2.5-Coder.
apiVersion: batch/v1kind: Jobmetadata:name: download-modellabels:app: download-modelspec:template:metadata:name: download-modellabels:app: download-modelannotations:eks.tke.cloud.tencent.com/root-cbs-size: "100" # The system disk capacity of a super node is only 20 Gi by default. After decompressing the vllm mirror, the disk will be full. Use this annotation to customize the system disk capacity (charges will apply for the part exceeding 20 Gi).spec:containers:- name: vllmimage: vllm/vllm-openai:v0.7.1command:- modelscope- download- --local_dir=/data/model/Qwen2.5-Coder-7B-Instruct- --model=Qwen/Qwen2.5-Coder-7B-InstructvolumeMounts:- name: datamountPath: /data/modelvolumes:- name: datapersistentVolumeClaim:claimName: ai-model # Name of the created PVCrestartPolicy: OnFailure
4. Install AIBrix
# Install component dependencieskubectl create -f https://github.com/vllm-project/aibrix/releases/download/v0.2.1/aibrix-dependency-v0.2.1.yaml# Install aibrix componentskubectl create -f https://github.com/vllm-project/aibrix/releases/download/v0.2.1/aibrix-core-v0.2.1.yaml
Check the installation of AIBrix and confirm that all pods are in the Running state.
kubectl -n aibrix-system get pods
5. Deploying a Model
Create a RayClusterFleet deployment for the Qwen2.5-Coder-7B-Instruct model.
apiVersion: orchestration.aibrix.ai/v1alpha1kind: RayClusterFleetmetadata:labels:app.kubernetes.io/name: aibrixapp.kubernetes.io/managed-by: kustomizename: qwen-coder-7b-instructspec:replicas: 1selector:matchLabels:model.aibrix.ai/name: qwen-coder-7b-instructstrategy:rollingUpdate:maxSurge: 25%maxUnavailable: 25%type: RollingUpdatetemplate:metadata:labels:model.aibrix.ai/name: qwen-coder-7b-instructannotations:ray.io/overwrite-container-cmd: "true"spec:rayVersion: "2.10.0" # Must match the Ray version within the containerheadGroupSpec:rayStartParams:dashboard-host: "0.0.0.0"template:metadata:annotations:eks.tke.cloud.tencent.com/gpu-type: V100 # Specify the GPU card modeleks.tke.cloud.tencent.com/root-cbs-size: '100' # The system disk capacity of a super node is only 20 Gi by default. After decompressing the vllm image, the disk will be full. Use this annotation to customize the system disk capacity (charges will apply for the part exceeding 20 Gi).spec:containers:- name: ray-headimage: vllm/vllm-openai:v0.7.1ports:- containerPort: 6379name: gcs-server- containerPort: 8265name: dashboard- containerPort: 10001name: client- containerPort: 8000name: servicecommand: ["/bin/bash", "-lc", "--"]args:- |ulimit -n 65536;echo head;$KUBERAY_GEN_RAY_START_CMD & KUBERAY_GEN_WAIT_FOR_RAY_NODES_CMDS;vllm serve /data/model/Qwen2.5-Coder-7B-Instruct \\--served-model-name Qwen/Qwen2.5-Coder-7B-Instruct \\--tensor-parallel-size 2 \\--distributed-executor-backend ray \\--dtype=halfresources:limits:cpu: "4"nvidia.com/gpu: 1requests:cpu: "4"nvidia.com/gpu: 1volumeMounts:- name: datamountPath: /data/modelvolumes:- name: datapersistentVolumeClaim:claimName: ai-model # Name of the created PVCworkerGroupSpecs:- replicas: 1minReplicas: 1maxReplicas: 5groupName: small-grouprayStartParams: {}template:metadata:annotations:eks.tke.cloud.tencent.com/gpu-type: V100 # Assign the GPU card modeleks.tke.cloud.tencent.com/root-cbs-size: '100' # The system disk capacity of a super node is only 20 Gi by default. After decompressing the vllm image, the disk will be full. Use this annotation to customize the system disk capacity (charges will apply for the part exceeding 20 Gi).spec:containers:- name: ray-workerimage: vllm/vllm-openai:v0.7.1command: ["/bin/bash", "-lc", "--"]args:["ulimit -n 65536; echo worker; $KUBERAY_GEN_RAY_START_CMD"]lifecycle:preStop:exec:command: ["/bin/sh", "-c", "ray stop"]resources:limits:cpu: "4"nvidia.com/gpu: 1requests:cpu: "4"nvidia.com/gpu: 1volumeMounts:- name: datamountPath: /data/modelvolumes:- name: datapersistentVolumeClaim:claimName: ai-model # Name of the created PVC
6. Verify API
After the Pod deployed by RayClusterFleet runs successfully, you can quickly verify the API through kubectl port-forward.
# Get service namesvc=$(kubectl get svc -o name | grep qwen-coder-7b-instruct)# Use the forward function to expose the API to port 18000 locallykubectl port-forward $svc 18000:8000# Start another terminal and run the following command to test the APIcurl -X POST "http://localhost:18000/v1/chat/completions" \\-H "Content-Type: application/json" \\-d '{"model": "Qwen/Qwen2.5-Coder-7B-Instruct","messages": [{"role": "system", "content": "You are an AI programming assistant."},{"role": "user", "content": "Implement quick sort algorithm in Python"}],"temperature": 0.3,"max_tokens": 512,"top_p": 0.9}'
FAQs
aibrix-kuberay-operator cannot start, Error runtime/cgo: pthread_create failed: Operation not permitted
Check whether aibrix-kuberay-operator is deployed on the super node. If aibrix-kuberay-operator is deployed on the super node, please refer to the following two solutions:
1. Modify the Deployment of aibrix-kuberay-operator and add the following annotations in the Pod Template:
eks.tke.cloud.tencent.com/cpu-type: intel # Specify the CPU type as Intel
2. Refer to setting scheduling rules for workloads and route aibrix-kuberay-operator to a regular node.
How to set up API Key to restrict access?
vLLM provides the following two methods to set the API key:
1. Set the
--api-key parameter.2. Set the environment variable
VLLM_API_KEY.Modify the definition of RayClusterFleet, after setting the API key in headGroupSpec using either of the above methods, include the following Header in the request for access:
Authorization: Bearer <VLLM_API_KEY>
Help and Support
Was this page helpful?
You can also Contact sales or Submit a Ticket for help.
Help us improve! Rate your documentation experience in 5 mins.
Feedback