Configuring For High Availability Services
Download
Modo Foco
Tamanho da Fonte
Use case
Building master/slave or active-active HA clusters in the traditional way is quite cumbersome. You can use health check of Auto Scaling to implement high availability.
The system will automatically monitor the health status of the active nodes. When the active node does not respond to a ping, Auto Scaling will automatically replicate a healthy instance to replace any abnormal ones, ensuring healthy and smooth business operation and providing comprehensive protection for your business.
Directions
Step 1: Create images of stateless CVMs in a cluster.
Step 2: Create a scaling group, and configure the maximum and the minimum capacities as desired. Then, select Add a CVM on the list of CVMs in the scaling group to manually add the existing CVM to the cluster. Note: When a manually added CVM is replaced, it’s only removed from the scaling group but not terminated.
Step 3: Create a notification policy and select to receive notifications about scaling activities that replace unhealthy instances.
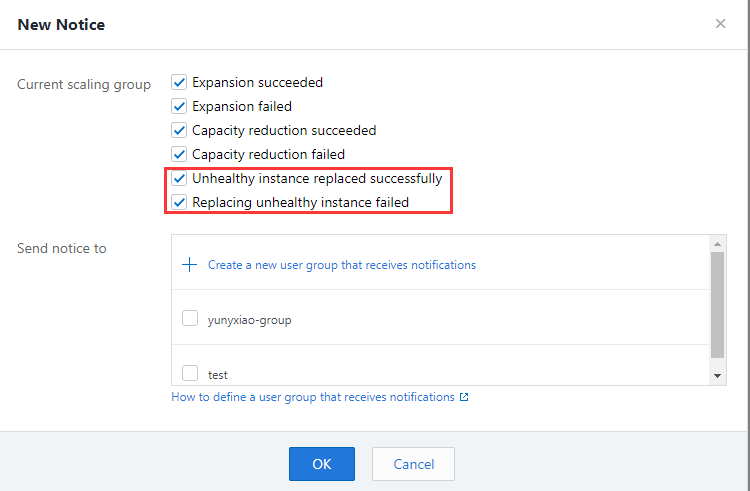
The configuration is complete.
Benefits of AS
AS can make the cluster secure.
Applicable industries
It is strongly recommended that you add stateless CVMs (if any) to the scaling group, and make this an IT deployment routine.
Ajuda e Suporte
Esta página foi útil?
Você também pode entrar em contato com a Equipe de vendas ou Enviar um tíquete em caso de ajuda.
comentários