The dynamic threshold feature of Tencent Cloud Observability Platform can intelligently detect metric exceptions and send alarms without requiring you to set metric thresholds. This document describes this feature and its benefits and use cases in detail.
Background
As a national key project, the Seventh National Population Census of the People's Republic of China ("2020 Chinese Census") involved the use of multiple Tencent Cloud services, such as CVM, CLS, TencentDB for MySQL, and CDN. In addition, to ensure the stability of the monitored Tencent Cloud services, the project owner not only used Tencent Cloud service metrics but also reported many custom business metrics, such as service request time, error statistics, and online users. In this scenario characterized by abundant metrics, a huge user base, and considerable fluctuations in access requests during day and night, it was difficult to guarantee the accuracy and availability of monitoring results and alarms by using static thresholds to monitor metrics. This document describes how the dynamic threshold feature can be used in different scenarios by taking the 2020 Chinese Census project as an example.
Analysis
From the perspective of OPS personnel, the following key metrics need to be monitored:
Tencent Cloud service metrics: CPU utilization, memory utilization, traffic, bandwidth, and API success rate.
Custom metrics: request time, error statistics, and online users.
In order to detect any exceptions in the key metrics listed above in a timely manner, it is necessary to always monitor them. The traditional solution is to use static threshold alarms, where OPS personnel configure certain metric thresholds based on their experience. However, the following pain points arise during the configuration of metric thresholds:
Pain point 1. How to configure reasonable thresholds?
For each category of metrics, OPS personnel need to configure thresholds they think reasonable based on specific businesses, and the thresholds configured by different OPS personnel may vary.
Example: the static thresholds configured by experienced John Smith and less experienced Jane Smith for the same metric are different. For example, for the CPU utilization metric, John knows that an alarm needs to be triggered only when the CPU utilization of a certain machine reaches 85%, so the threshold he configures will meet the business needs. However, due to a lack of experience, Jane configures the alarm to be triggered when the CPU utilization exceeds 50%, in which case, a lot of unreasonable alarm notifications may be generated and thus cause disturbance. Therefore, the threshold policies configured by different OPS personnel may differ significantly.
Pain point 2. How to ensure the consistent reasonableness of thresholds?
A reasonable threshold previously configured for a metric may become unreasonable as your business changes, so you need to check whether it is reasonable every day. If you don't adjust it, alarms may not be triggered correctly as expected.
Example: suppose the traffic of a certain business is low after its launch due to a small user base and fluctuates around 100 MB, so John Smith configures alarms to be triggered when the traffic exceeds 120 MB based on the value range of the metric. However, as the business grows, the value of the traffic metric gradually increases and fluctuates around 150 MB. At this point, the threshold of 120 MB previously configured becomes unreasonable, and John will need to manually adjust the threshold to 170 MB based on the traffic fluctuation.
Pain point 3. How to reflect the direction of metrics?
For metrics whose upward and downward changes require attention, it is necessary to configure several thresholds to ensure the accuracy of alarms.
Example: the directions of changes that require attention vary by metric. For example:
For metrics whose expected value is 100%, such as API success rate, only a decline in the metric value is considered exceptional and therefore requires attention.
For metrics of which a low value is expected, such as failure rate, error statistics, and request time, only an increase in the metric value is considered exceptional and therefore requires attention.
For metrics whose value has no obvious directions, such as traffic and online users, both an increase and a decrease are considered exceptional.
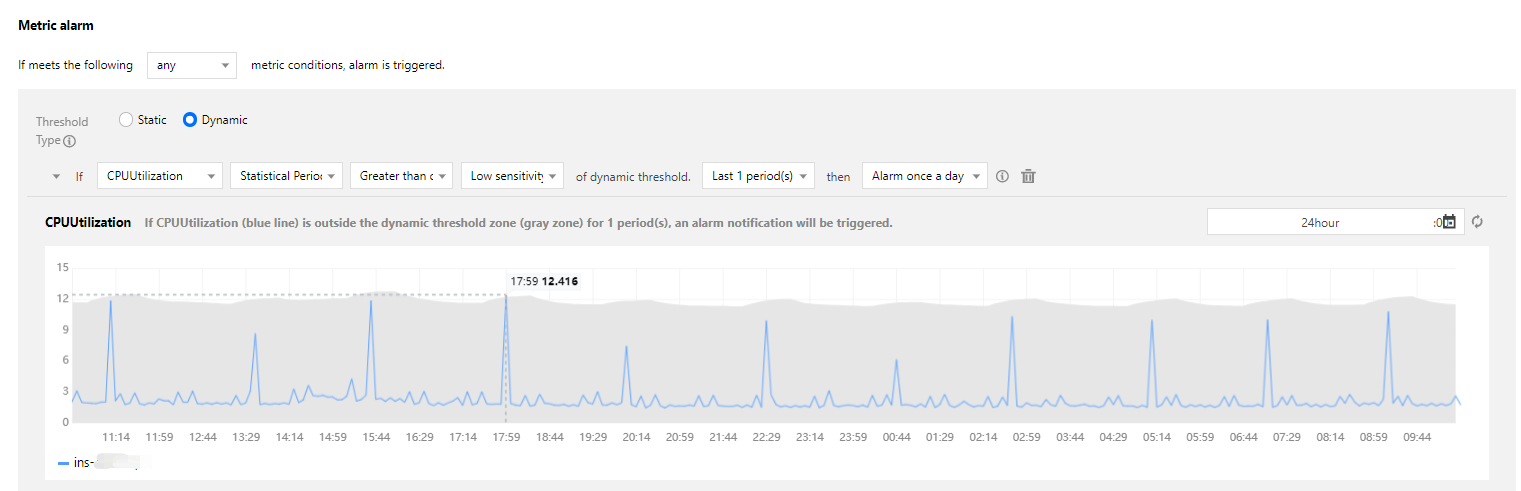
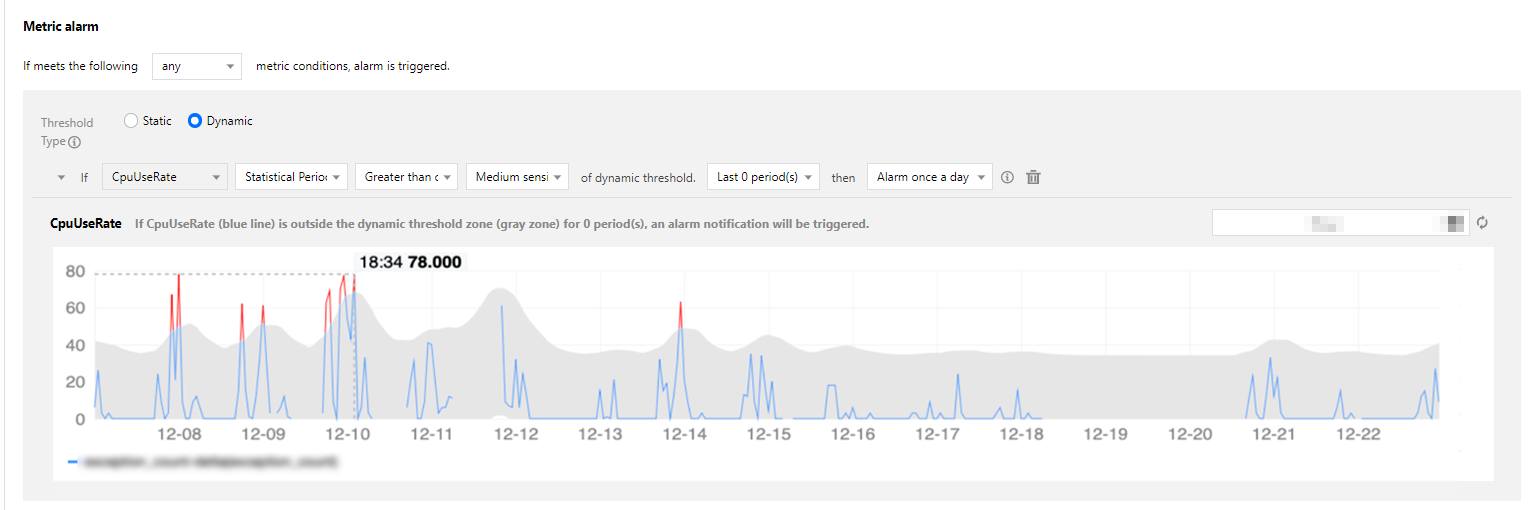
The dynamic threshold feature can adaptively extract the characteristics of the metric curve such as the trend, period, and fluctuation based on the historical trend and then automatically calculate a reasonable upper threshold. It greatly simplifies the configuration and maintenance of reasonable thresholds.
Use Cases
The following lists the use cases where dynamic thresholds are suitable as well as their characteristics, detailed metrics, and recommended configurations:
Use Case
Metrics
Characteristics
Recommended Configurations
Percentage
Success rate, failure rate, packet loss rate, traffic hit rate, outbound traffic utilization, query rejection rate, and bandwidth utilization
Such metrics range between 0 and 100%. Users will only concern if such metrics reach certain levels. For example, users will only care when the disk utilization exceeds 95%. It is suitable to use static thresholds or both static and dynamic ones for such metrics.
If there is a definite threshold limit, we recommend you use dynamic thresholds together with static thresholds, with the sensitivity set to low-to-medium and the duration set to 2–4 consecutive statistical periods.
The values of such metrics fluctuate greatly in an uncertain range over time. It is suitable to use dynamic thresholds for such metrics.
We recommend you set the sensitivity to medium-to-high and the duration to 2–4 consecutive statistical periods.
Delay
Delays, delay distance, and delay time
The values of such metrics typically fluctuate slightly in an uncertain range. It is suitable to use dynamic thresholds for such metrics.
We recommend you set the sensitivity to low-to-medium and the duration to 3–10 consecutive statistical periods.
Others
Slow queries, TencentDB threads, Redis connections, TCP connections, disk QPS, IO wait time, temp tables, full-table scans, and unconsumed CKafka messages
It is suitable to use dynamic thresholds for such metrics.
We recommend you set the sensitivity to medium-to-high and the duration to 1–5 consecutive statistical periods.
The following describes how to configure a dynamic threshold for a metric in each use case.
Percentage metrics
For percentage metrics, the value range is fixed, typically 0–100%. Users will only concern if such metrics reach certain levels. For example, users will only care when the disk utilization exceeds 95%. It is suitable to use static thresholds or both static and dynamic ones for such metrics. However, we recommend you consider using a medium sensitivity in practical applications.
Scenario 1: if you definitely know when a serious problem might occur with regard to a metric, such as CPU utilization, where alarms are configured to be triggered typically when the threshold of 90% is reached, you can consider using a static threshold.
Scenario 2: if you feel that an alarm threshold of 90% for a percentage metric cannot help you detect some problems in advance, you can consider using a dynamic threshold as shown below, where alarms will be triggered when the metric value surges, thus allowing you to solve problems as soon as they arise.
Scenario 3: if you feel that alarms are helpful only if they are triggered when the threshold of 60% is reached in case of metric value surge, you can consider using a dynamic threshold in combination with a static threshold.
Network traffic metrics
The values of such metrics fluctuate greatly in an uncertain range over time. It is suitable to use dynamic thresholds for such metrics.
Scenario 1: if you, as an OPS specialist, need to observe data generated a very long time ago to determine a reasonable threshold for a metric, or if you still cannot determine the optimum threshold after observation, a dynamic threshold can save you worry.
Scenario 2: if you clearly know that an exception occurs when the value of the traffic metric exceeds or drops below a certain threshold, you can consider using a dynamic threshold in combination with a static threshold.
Delay metrics
The values of such metrics typically fluctuate slightly in an uncertain range. It is suitable to use dynamic thresholds for such metrics.
As there are a lot of glitches in delay metrics, we recommend you use a medium sensitivity and a longer duration to filter out glitches and improve the alarm quality.
Other metrics
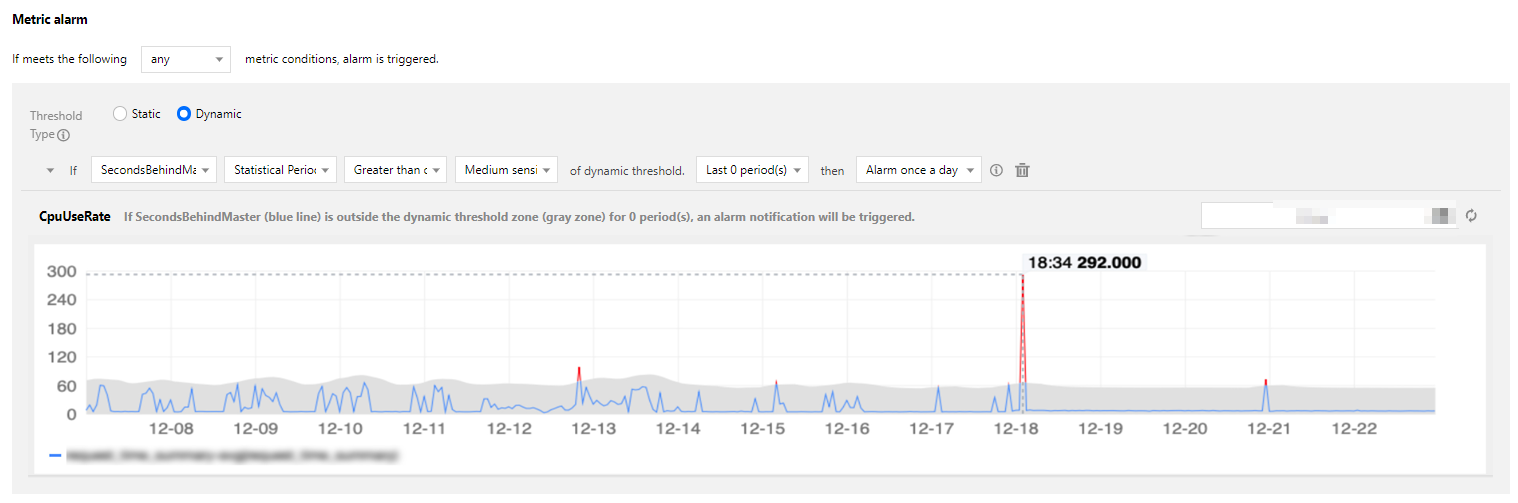
Exception statistics
At the early stage of your business, if it is difficult for you to configure a reasonable threshold, and you need to manually adjust it every day based on the changes, then you can use a dynamic threshold.
Dynamic thresholds can adaptively track the trends of the metrics, thus making it easier for you to determine reasonable thresholds.
As long as you select a "greater or less than" threshold, the system will adaptively identify sudden increases and decreases and send alarm notifications.
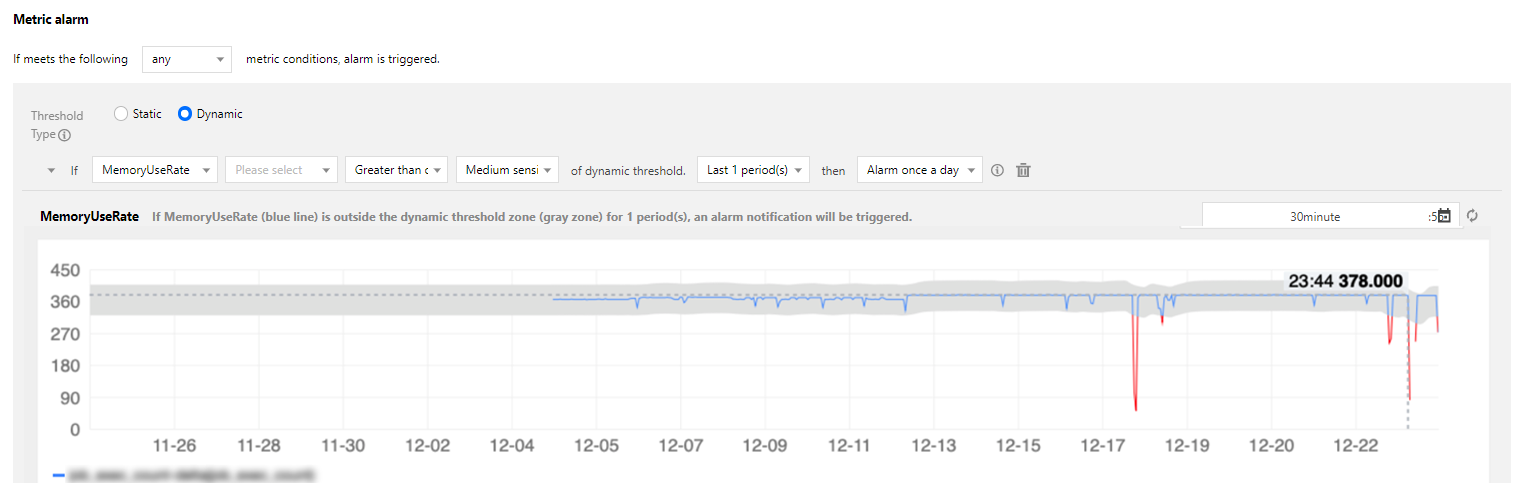
Statistics metrics
It can be found through observation that most metric values are around 350. An exception may have occurred when the metric value increases or decreases suddenly. If you use static thresholds, you would need to configure two reasonable upper and lower thresholds.
After a period of operation, the metric value may increase to 550, which is just in alignment with the current business conditions.
If you use static thresholds, you will keep receiving alarm notifications and need to reconfigure thresholds that are suitable at the current stage.
If you use a dynamic threshold, only when the metric value suddenly increases from 350 to 550, alarm notifications will be sent until the metric value stabilizes at 550 when the algorithm intelligently identifies the current value as a normal value.